kafka总结
文章目录
Kafka
Broker
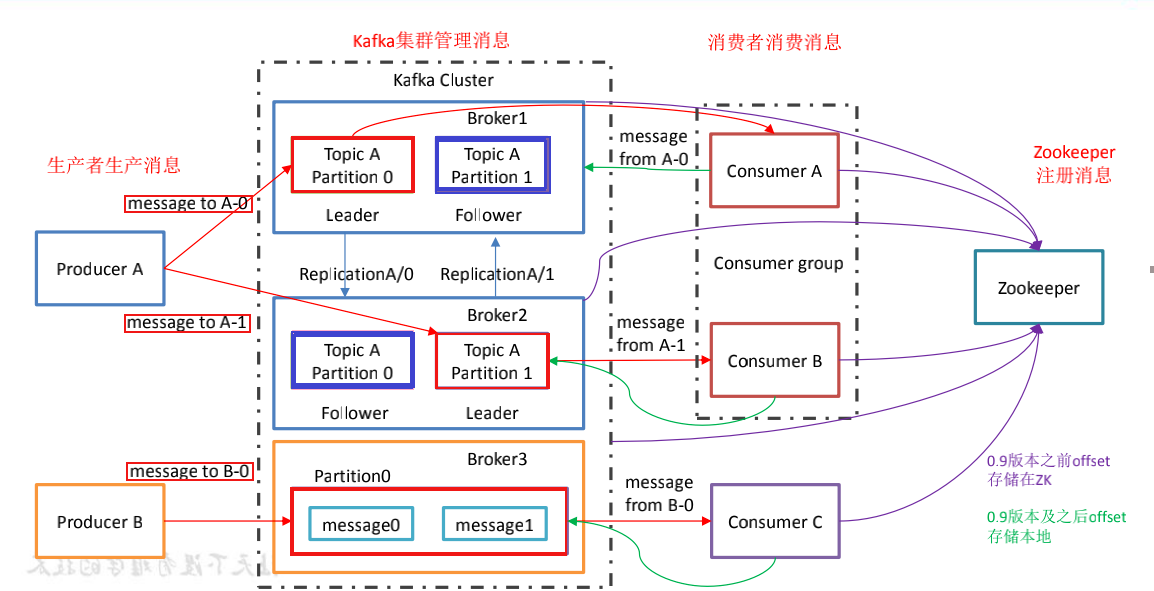
一台kafka服务器就是一个broker。一个集群由多个broker 组成。一个broker可以容纳多个topic。
Topic(主题)
Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic;
Partition(分区)
what:
- 每个partition可以被认为是一个无限长度的数组,新数据顺序追加进这个数组。物理上,每个partition对应于一个文件夹。一个broker上可以存放多个partition。这样,producer可以将数据发送给多个broker上的多个partition,consumer也可以并行从多个broker上的不同paritition上读数据,实现了水平扩展
why: 要在topic里加入分区的概念?
- 面向接口编程,而不面向实现
- 对于生产者和消费者而言,只关心要向某个topic生产和消费数据,不感知数据是怎么存的。
- 为了性能考虑,如果topic内的消息只存于一个broker,那这个broker会成为瓶颈,无法做到水平扩展。所以把topic内的数据分布到整个集群就是一个自然而然的设计方式。Partition的引入就是解决水平扩展问题的一个方案
- topic是逻辑的概念,partition是物理的概念;
- 方便在集群中扩展
- 每个 Partition 可以通过调整以适应它所在的机器,而一个 topic又可以有多个 Partition 组成,因此整个集群就可以适应任意大小的数据了;
- 可以提高并发
- 因为可以以 Partition 为单位读写了。
how:
Segment
what: segment file 是什么?
- segment file 由2大部分组成,(以.index结尾的索引文件,和以.log 结尾的数据文件),一个partition对应一个文件夹,一个partition里理论上可以包含任意多个segment。所以partition可以认为是在segment上做了一层包装。
why: 为什么有了partition还需要segment?
- 为了kafka对文件的顺序写优化设计方案
- 如果不引入segment,一个partition直接对应一个文件(应该说两个文件,一个数据文件,一个索引文件),那这个文件会一直增大。同时,在做data purge时,需要把文件的前面部分给删除,不符合kafka对文件的顺序写优化设计方案。引入segment后,每次做data purge,只需要把旧的segment整个文件删除即可,保证了每个segment的顺序写,
把数据平行扩展的一种实现方式;all data --> some partition(different broker) ---> more and more segment every partition
- 为了kafka对文件的顺序写优化设计方案
how:
- 每个partition 只需支持顺序进行读写即可,segment 的生命周期由服务端配置参数决定。
Replication(副本)
- Replication:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
- leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
- follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的 follower。
1)副本数据同步策略–>对broker而言
| 方案 | 优点 | 缺点 |
|---|---|---|
| 半数以上完成同步,就发送ack | 延迟低 | 选举新的leader时,容忍n台节点的故障,需要2n+1个副本 |
| 全部完成同步,才发送ack | 选举新的leader时,容忍n台节点的故障,需要n+1个副本 | 延迟高 |
- Kafka 选择了第二种方案,原因如下:
- 1.同样为了容忍 n 台节点的故障,第一种方案需要 2n+1 个副本,而第二种方案只需要 n+1个副本,而 Kafka 的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
- 2.虽然第二种方案的网络延迟会比较高,但网络延迟对 Kafka 的影响较小。
1.2)ISR–>对broker而言
- 采用第二种方案之后,设想以下情景:
- leader 收到数据,所有 follower 都开始同步数据,但有一个 follower,因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去,直到它完成同步,才能发送 ack。这个问题怎么解决呢?
- Leader 维护了一个动态的 in-sync replicaset (ISR),意为和 leader 保持同步的 follower 集合。当 ISR 中的 follower 完成数据的同步之后,leader 就会给 follower 发送 ack。如果 follower长时间未向leader同步数据,则该 follower 将被踢出ISR , 该时间阈值由replica.lag.time.max.ms参数设定。Leader 发生故障之后,就会从 ISR 中选举新的 leader。
- leader 收到数据,所有 follower 都开始同步数据,但有一个 follower,因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去,直到它完成同步,才能发送 ack。这个问题怎么解决呢?
2)故障处理细节
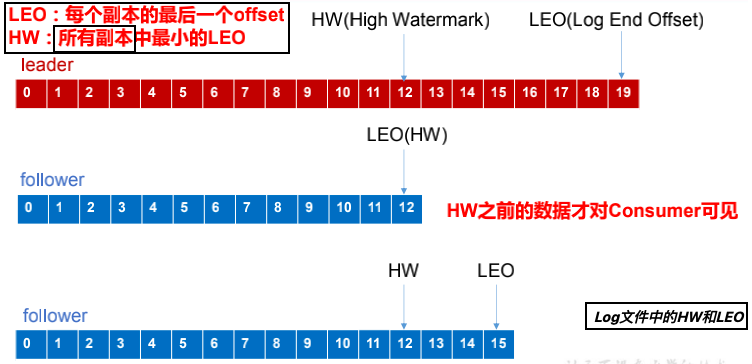
- LEO:指的是每个副本最大的 offset;
- HW:指的是消费者能见到的最大的 offset,ISR 队列中最小的 LEO。
follower故障 1.1. follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的 HW,并将log文件高于HW的部分截取掉,然后从 HW 开始向 leader 进行同步。 1.2. 等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
leader故障 2.1. leader发生故障之后,会从ISR中选出一个新的leader,之后,为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW的部分截掉,然后从新的leader同步数据。
- 2.1.1. 怎么选出新的leader?
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
生产者
消费者
Between producter and broker
数据可靠性保证
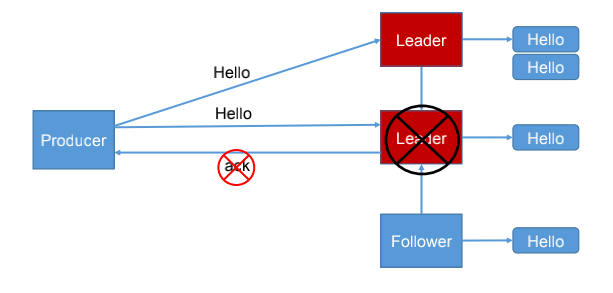
为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 的每个 partition 收到producer 发送的数据后,都需要向 producer 发送 ack(acknowledgement 确认收到),如果producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。
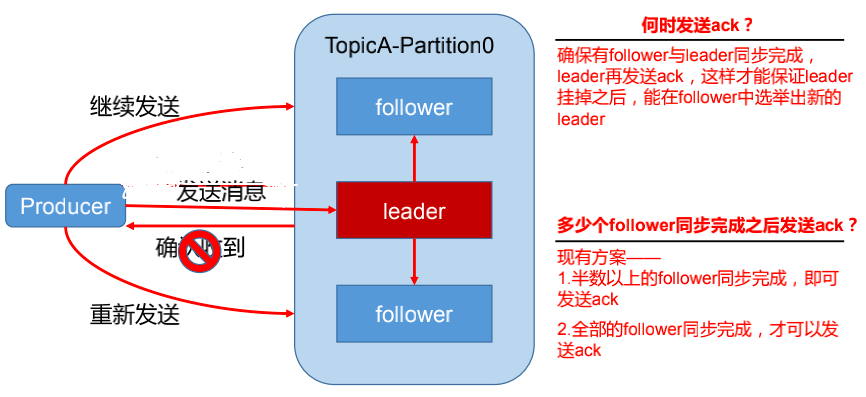
3)ack应答机制–>对producer而言
why: 对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 follower 全部接收成功。
how: 所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。
- acks 参数配置:
- 0:producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据;
- 1:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,
- 如果在 follower同步成功之前 leader 故障,那么将会丢失数据;
- 如果在 follower同步成功之前 leader 故障,那么将会丢失数据;
- -1(all):producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盘成功后才返回 ack。(
如果follower的个数等于0个,那么退化成第二种情况,也可能出现丢数据的情况,应该leader也已经把数据保存到了磁盘,然后服务不可用?)- 但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会造成数据重复。
- 但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会造成数据重复。
- acks 参数配置:
// TODO
什么情况下会发生kafka丢数据的情况?
Exactly Once语义
At Least Once
- 将服务器的 ACK 级别设置为-1,可以保证 Producer 到 Server 之间不会丢失数据,即 AtLeast Once语义。
- At Least Once 可以保证数据不丢失,但是不能保证数据不重复;
At Most Once
- 相对的,将服务器 ACK 级别设置为 0,可以保证生产者每条消息只会被发送一次,即 At Most Once 语义。
- 可以保证数据不重复,但是不能保证数据不丢失。
Exactly Once 语义
what:
At Least Once + 幂等性 = Exactly Once- 幂等性:
- 所谓的幂等性就是指 Producer 不论向 Server 发送多少次重复数据,Server 端都只会持久化一条。(幂等性结合 At Least Once 语义,就构成了 Kafka 的 Exactly Once 语义)。
- 幂等性:
why:
- 下游数据消费者要求数据既不重复也不丢失,即 Exactly Once 语义。比如说交易数据
how:
- 要启用幂等性,只需要将 Producer 的参数中
enable.idompotence设置为true即可。 - Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。
- 开启幂等性的 Producer 在初始化的时候会被分配一个 PID,发往同一 Partition 的消息会附带 Sequence Number。而Broker 端会对
<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker 只会持久化一条。但是 PID 重启就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区跨会话的 Exactly Once。
- 要启用幂等性,只需要将 Producer 的参数中
Between broker and comsume group
consumers(consumer group) <---> partition(every topic)
消费组的分配策略
一个 consumer group 中有多个 consumer,一个 topic 有多个 partition,所以必然会涉及 到 partition 的分配问题,即确定那个 partition 由哪个 consumer 来消费。
- Kafka 有两种分配策略:
- rangeAssignor
- roundRobinAssinor
- stickAssignor
当消费者是以消费组的呢?
上面的都是讨论的一个消费组内的消费者,
假想:如果是一个消费组内只有一个消费者,那么只要这个消费者订阅某个topic,那么必然能接收到topic消息。 所以上面讨论的都是组内的消费者!!!
range
- 以每个topic为基础,对每个topic
- ① 假设
n = 这个topic的分区数 / 订阅此topic消费者数量(在某个消费组内讨论), - ②
m=分区数%消费者数量 - ③ 那么前m个消费者每个分配n+1个分区,后面的(消费者数量-m)个消费者每个分配n个分区。
- ① 假设
https://kafka.apache.org/23/javadoc/org/apache/kafka/clients/consumer/RangeAssignor.html
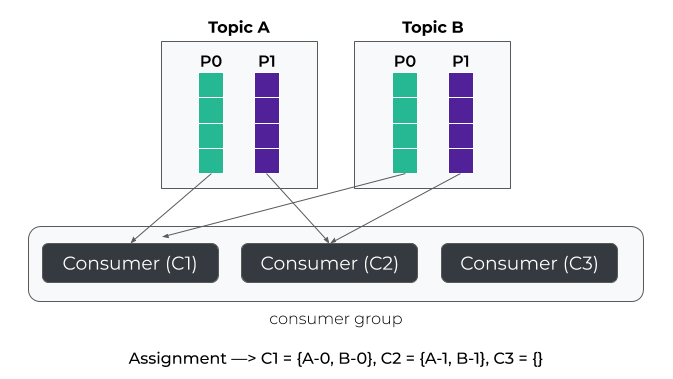
The range assignor works on a per-topic basis. For each topic, we lay out the available partitions in numeric order and the consumers in lexicographic order. We then divide the number of partitions by the total number of consumers to determine the number of partitions to assign to each consumer. If it does not evenly divide, then the first few consumers will have one extra partition.
For example, suppose there are two consumers C0 and C1, two topics t0 and t1, and each topic has 3 partitions, resulting in partitions t0p0, t0p1, t0p2, t1p0, t1p1, and t1p2.
The assignment will be:
C0: [t0p0, t0p1, t1p0, t1p1] C1: [t0p2, t1p2]
范围分配器以每个主题为基础工作。对于每个主题,我们按数字顺序列出可用的分区,按词法顺序列出消费者。然后,我们将分区的数量除以消费者的总数,以确定分配给每个消费者的分区数量。如果没有平均分配,那么前几个消费者就会多出一个分区。
round robin
请愿的时候,要杀名字靠前的前二到三个人,所以想轮盘写名字,同罪,中间是情愿书。
- 基于某个消费组内所有消费者订阅的topic汇总去重后, topics所有的partitions和某个消费组内的所有消费者,把消费者排成轮盘,然后所有partitions进行分配。
- 当某个消费者没有订阅某个topic,则跳过。
https://kafka.apache.org/23/javadoc/org/apache/kafka/clients/consumer/RoundRobinAssignor.html
The round robin assignor lays out all the available partitions and all the available consumers. It then proceeds to do a round robin assignment from partition to consumer. If the subscriptions of all consumer instances are identical, then the partitions will be uniformly distributed. (i.e., the partition ownership counts will be within a delta of exactly one across all consumers.)
| |
When subscriptions differ across consumer instances, the assignment process still considers each consumer instance in round robin fashion but skips over an instance if it is not subscribed to the topic. Unlike the case when subscriptions are identical, this can result in imbalanced assignments.
| |
sticky
- 对每个消费者保证尽可能平衡;
- 当重新分配发生,尽可能保持原有的关系不变。
https://kafka.apache.org/23/javadoc/org/apache/kafka/clients/consumer/StickyAssignor.html
- The sticky assignor serves two purposes.
First, it guarantees an assignment that is as balanced as possible, meaning either:
- the numbers of topic partitions assigned to consumers differ by at most one; or
- each consumer that has 2+ fewer topic partitions than some other consumer cannot get any of those topic partitions transferred to it.
Second, it preserved as many existing assignment as possible when a reassignment occurs. This helps in saving some of the overhead processing when topic partitions move from one consumer to another.
Starting fresh it would work by distributing the partitions over consumers as evenly as possible. Even though this may sound similar to how round robin assignor works, the second example below shows that it is not. During a reassignment it would perform the reassignment in such a way that in the new assignment
- topic partitions are still distributed as evenly as possible, and
- topic partitions stay with their previously assigned consumers as much as possible.
Of course, the first goal above takes precedence over the second one.
| |
| |
offset 的维护
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故 障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢 复后继续消费。
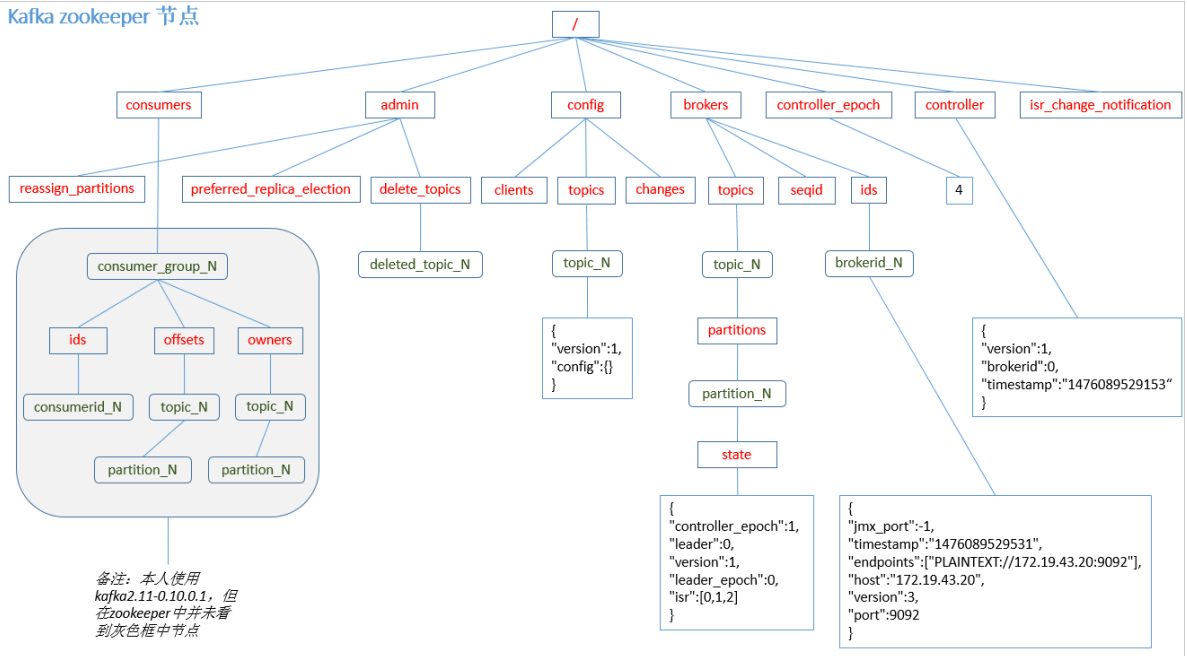
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中,从 0.9 版本开始, consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为__consumer_offsets。
1)修改配置文件consumer.properties
| |
2)读取 offset
- 0.11.0.0 之前版本:
| |
- 0.11.0.0 之后版本(含):
| |
文章作者 zput
上次更新 2020-03-24