编程范式-泛型编程
文章目录
泛型
要说泛型,就需要了解类型的本质。
类型
编程语言会有两种类型,一种是内建类型,如 int、float 和 char 等,一种是抽象类型,如 struct、class 和 function 等
对于静态类型编程语言:静态类型检查是在编译器进行语义分析时进行的。
对于动态类型编程语言:一个变量的类型是由运行时的解释器来动态标记的,这样就可以动态地和底层的计算机指令或内存布局对应,动态类型的语言必然要给出一堆诸如:is_array(), is_int(), is_string() 或是 typeof() 这样的运行时类型检查函数。
作用于不同类型的代码,虽然长得非常相似,但是由于类型的问题需要根据不同类型写出不同的算法,如果要做到泛型,就需要涉及比较底层的玩法。
👆:对不同类型有不同的操作方式;
👇:类型是内存的一种抽象,不同类型有不同内存。
泛型操作
所以要做到泛型,就需要:
- 抽象不同类型的初始化/销毁。(分配/释放)
- 抽象为一组对类型的操作。
- 标准化掉数据容器的操作。(比如:查找算法、过滤算法、聚合算法……)
类型是对内存的一种抽象。不同的类型,会有不同的内存布局和内存分配的策略。 不同的类型,有不同的操作。所以,对于特定的类型,也有特定的一组操作。
类型抽象&数据结构抽象&业务与控制逻辑的分离
- 类型抽象:对于静态类型编程语言有许多不同的类型。
- 数据结构:是数据的聚合形式,比如基础的数组,链表,然后在此延伸出的队列,栈,散列表,堆,树和图。
- 类型相当于元素(element),数据结构是多个元素的组织形式。
- 算法的抽象。
- 程序的算法(成应用逻辑)
- 应该是和数据类型甚至数据结构无关的。
- 各种特殊的数据类型(或数据结构)
- 理应做好自己的份内的工作。
- 算法只关于一个完全标准和通用的实现。
- 对于泛型的抽象,我们需要回答一个问题:
- 如果让我的数据类型符合通用的算法,那么什么是数据类型最小的需求?
评估方式
通过让不同的编程语言来写出swap/search/sum三种函数,来评估此语言的类型抽象,数据结构抽象和控制逻辑的抽象能力
- Swap(X,y)通用的与类型无关的泛型
- 类型抽象
- Search(container,va)泛型函数
- 类型的抽像
- 数据结构的抽像
- Sum-Employee.vacation/Emplyee.Salary
- 业务逻辑与控制逻辑的分离
- 控制逻辑的抽象和泛型
C语言
swap
| |
- 执行:https://onlinegdb.com/1SPNbkCSPr
search
| |
Do not use memcmp() to compare security critical data, such as cryptographic secrets, because the required CPU time depends on the number of equal bytes. Instead, a function that performs comparisons in constant time is required. Some operating systems provide such a function (e.g., NetBSD’s consttime_memequal()), but no such function is specified in POSIX. On Linux, it may be necessary to implement such a function oneself.
C语言泛型的问题
没有办法解决数据结构的抽象。
- 如果再继续进入数据结构中的泛型。如:vector,stack,map几乎很难了
- 数据容器还需要解决两个问题:
- 数据对象的内存是如何分配和释放的?
- 数据对象的复制是如何复制的?深拷贝还是浅拷贝?
算法越复杂,对于类型的抽象越难满足。
- 随着算法越来越复杂,接口越来越复杂。
- 数据类型的自适应问题
- 随着算法越来越复杂,接口越来越复杂。
C++语言
C++有效地解决了程序的泛型问题
- 类的出现
- 构造函数、析构函数一定义了数据模型的内存分配和释放。
- 拷贝函数函数、赋值函数一定义了数据模型中数据的拷贝和赋值。
- 重载操作符一定义了数据模型中数据的操作是如何进行的
- 模板的出现
- 根据不同的类型直接生成不同类型的函数,对不同的类型进行了有效的隔离。
- 具化的模板和特定的重载函数,可以为特定的类型指定特定的操作。
| |
sum
| |
c++Lambda
[capture list] (params list) mutable exception-> return type { function body }
c++迭代器
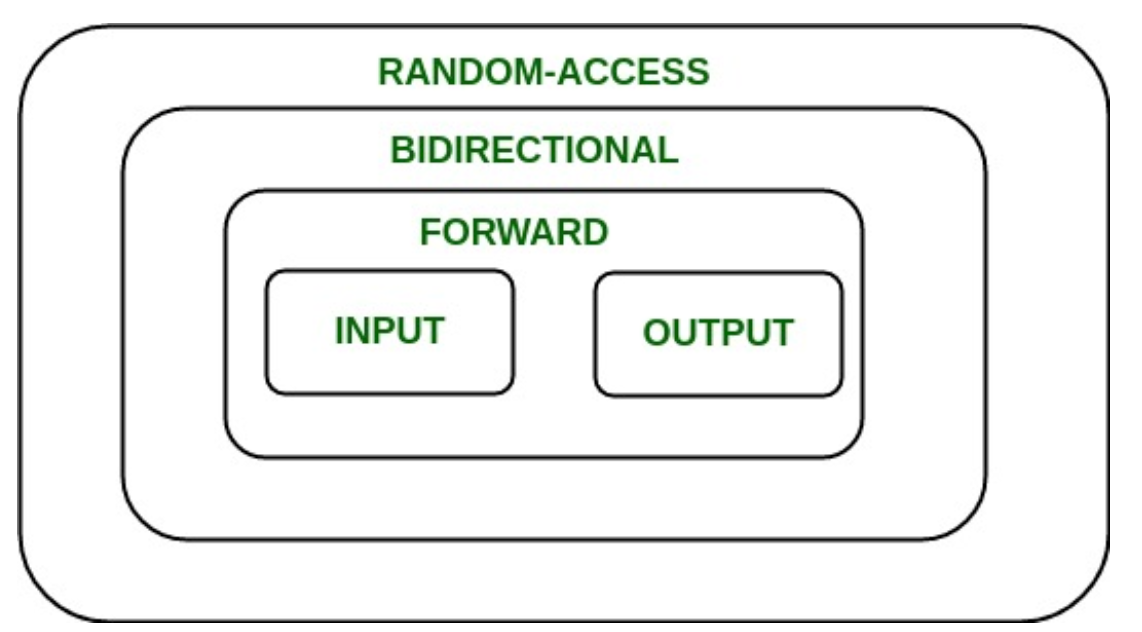
迭代器的种类 迭代器可以被分为5种:输入迭代器、输出迭代器、前向迭代器、双向迭代器、随机访问迭代器。下面是它们的分类依据:
输入迭代器:只能单步向前迭代元素,不允许修改由该类迭代器引用的元素。 输出迭代器:只能单步向前迭代元素,对元素只有写的权力。 前向迭代器:拥有输入迭代器和输出迭代器的所有特性 双向迭代器:在前向迭代器的基础上提供了单步向后迭代元素的能力 随机访问迭代器:拥有上面4个迭代器的所有特性,而且可以像指针那样进行算术计算,而不是仅仅只有单步向前或向后迭代。 在STL中,各容器提供的迭代器种类如下:
vector,deque:随机访问迭代器 list,set,multiset,map,multimap:双向迭代器 stack,queue,priority_queue:不支持任何迭代器
各种迭代器支持的操作如下:
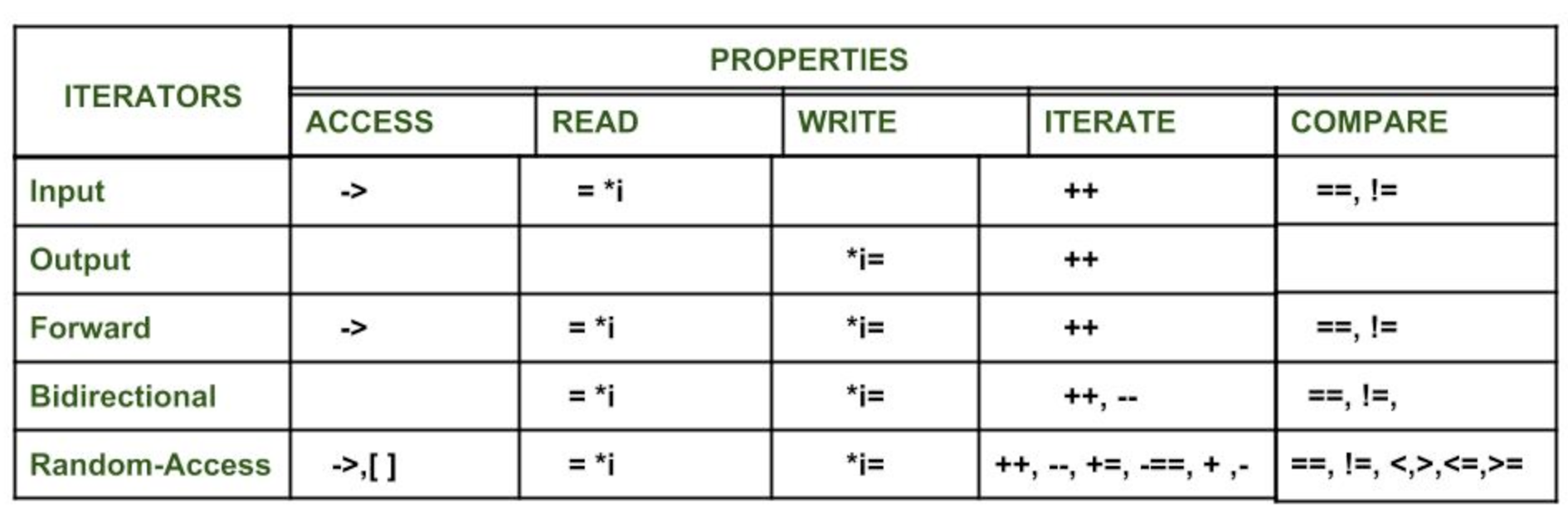
五种迭代器均支持:
- p++:后置单步向前迭代
- ++p:前置单步向前迭代
- 输入迭代器:
- *p:解引用作为右值(读)
- p=p1:将一个迭代器赋给另一个迭代器
- p==p1:比较迭代器的相等性
- p!=p1:比较迭代器的不等性
- 输出迭代器:
- *p:解引用作为左值(写)
- p=p1:将一个迭代器赋给另一个迭代器
- 前向迭代器:
- 输入迭代器和输出迭代器的所有支持操作的总和
- 双向迭代器:
- p–:后置单步向后迭代
- –p:前置单步向后迭代
- 随机访问迭代器:
- p+=i/p+i:i步向前迭代
- p-=i/p-i:i步向后迭代
- p[i]:返回偏离i位元素的引用
- p<p1 & p<=p1 & p>p1 & p>=p1:比较两个迭代器的先后顺序位置
golang
sum
| |
| |
php
| |
| |
| |
文章作者 zput
上次更新 2022-10-20