索引 #
索引简介 #
索引是什么?
A database index is a data structure that improves the speed of operations in a table MySQL官方对索引的定义为:索引(INDEX)是帮助MySQL对表高效操作的数据结构。
从而可以获得索引的本质:索引是排好序的快速查找数据结构。
索引的目的在于提高查询效率,可以类比字典的目录。如果要查mysql这个这个单词,我们肯定要先定位到m字母,然后从上往下找y字母,再找剩下的sql。如果没有索引,那么可能需要a---z,这样全字典扫描,如果我想找Java开头的单词呢?如果我想找Oracle开头的单词呢???
重点:索引会影响到MySQL查找(WHERE的查询条件)和排序(ORDER BY)两大功能!
除了数据本身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
# Linux下查看磁盘空间命令 df -h
[root@Ringo ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 40G 16G 23G 41% /
devtmpfs 911M 0 911M 0% /dev
tmpfs 920M 0 920M 0% /dev/shm
tmpfs 920M 480K 920M 1% /run
tmpfs 920M 0 920M 0% /sys/fs/cgroup
overlay 40G 16G 23G 41%
我们平时所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。当然,除了B+树这种数据结构的索引之外,还有哈希索引(Hash Index)等。
索引的优势和劣势
优势:
- 查找:类似大学图书馆的书目索引,提高数据检索的效率,降低数据库的IO成本。
- 排序:通过索引対数据进行排序,降低数据排序的成本,降低了CPU的消耗。
劣势:
- 实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的。
- 虽然索引大大提高了查询速度,但是同时会降低表的更新速度,例如对表频繁的进行
INSERT、UPDATE和DELETE。因为更新表的时候,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加的索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。 - 索引只是提高效率的一个因素,如果MySQL有大数据量的表,就需要花时间研究建立最优秀的索引。
索引分类 #
索引分类:
- 单值索引:一个索引只包含单个列,一个表可以有多个单列索引。
- 唯一索引:索引列的值必须唯一,但是允许空值。
- 复合索引:一个索引包含多个字段。
建议:一张表建的索引最好不要超过5个!
/* 基本语法 */
/* 1、创建索引 [UNIQUE]可以省略*/
/* 如果只写一个字段就是单值索引,写多个字段就是复合索引 */
CREATE [UNIQUE] INDEX indexName ON tabName(columnName(length));
/* 2、删除索引 */
DROP INDEX [indexName] ON tabName;
/* 3、查看索引 */
/* 加上\G就可以以列的形式查看了 不加\G就是以表的形式查看 */
SHOW INDEX FROM tabName \G;
使用ALTER命令来为数据表添加索引
/* 1、该语句添加一个主键,这意味着索引值必须是唯一的,并且不能为NULL */
ALTER TABLE tabName ADD PRIMARY KEY(column_list);
/* 2、该语句创建索引的键值必须是唯一的(除了NULL之外,NULL可能会出现多次) */
ALTER TABLE tabName ADD UNIQUE indexName(column_list);
/* 3、该语句创建普通索引,索引值可以出现多次 */
ALTER TABLE tabName ADD INDEX indexName(column_list);
/* 4、该语句指定了索引为FULLTEXT,用于全文检索 */
ALTER TABLE tabName ADD FULLTEXT indexName(column_list);
索引数据结构 #
索引数据结构:
BTree索引。Hash索引。Full-text全文索引。R-Tree索引。
BTree索引检索原理:
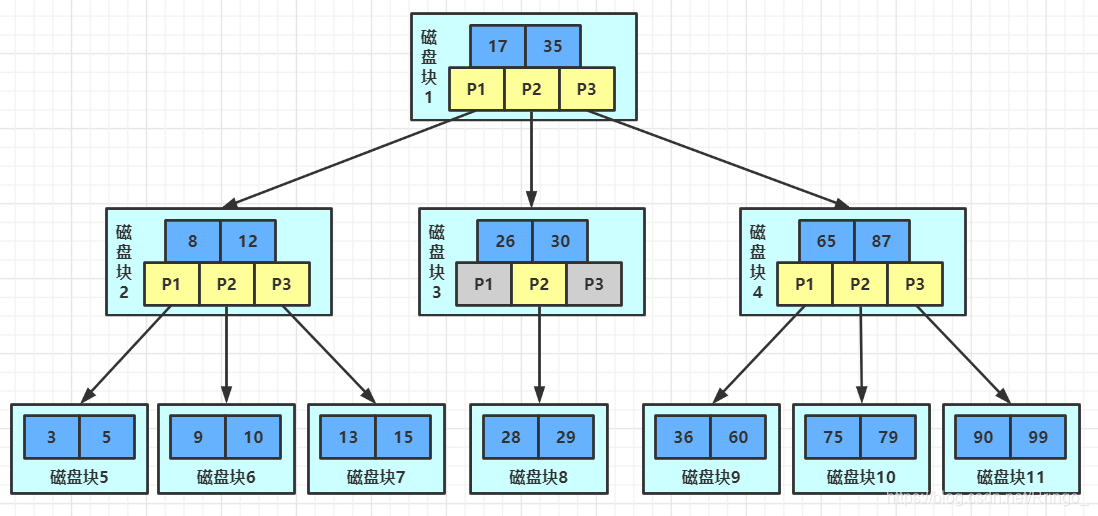
哪些情况需要建索引 #
- 主键:
- 如果有主键,默认会使用主键作为聚簇索引的索引键(key);
- 如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键(key);
- 在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键(key);
- where/order by:
- 频繁作为查询条件的字段应该创建索引。
- 查询中统计或者分组字段(group by也和索引有关)。
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度。
- 查询中与其他表关联的字段,外键关系建立索引。
那些情况不要建索引 #
- 记录太少的表。
- 经常增删改的表。
- 频繁更新的字段不适合创建索引。
- Where条件里用不到的字段不创建索引。
- 假如一个表有10万行记录,有一个字段A只有true和false两种值,并且每个值的分布概率大约为50%,那么对A字段建索引一般不会提高数据库的查询速度。索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99。一个索引的选择性越接近于1,这个索引的效率就越高。
索引分析 #
单表索引分析–>范围之后的索引会失效 #
数据准备 #
DROP TABLE IF EXISTS `article`;
CREATE TABLE IF NOT EXISTS `article`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
`author_id` INT(10) UNSIGNED NOT NULL COMMENT '作者id',
`category_id` INT(10) UNSIGNED NOT NULL COMMENT '分类id',
`views` INT(10) UNSIGNED NOT NULL COMMENT '被查看的次数',
`comments` INT(10) UNSIGNED NOT NULL COMMENT '回帖的备注',
`title` VARCHAR(255) NOT NULL COMMENT '标题',
`content` VARCHAR(255) NOT NULL COMMENT '正文内容'
) COMMENT '文章';
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES(1,1,1,1,'1','1');
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES(2,2,2,2,'2','2');
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES(3,3,3,3,'3','3');
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES(1,1,3,3,'3','3');
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES(1,1,4,4,'4','4');
案例:查询
category_id为1且comments大于1的情况下,views最多的article_id。
编写SQL语句并查看SQL执行计划。 #
# 1、sql语句
SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
# 2、sql执行计划
mysql> EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: article
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 5
filtered: 20.00
Extra: Using where; Using filesort # 产生了文件内排序,需要优化SQL
1 row in set, 1 warning (0.00 sec)
创建索引idx_article_ccv。
#
CREATE INDEX idx_article_ccv ON article(category_id,comments,views);
mysql> show index from article;
+---------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| article | 0 | PRIMARY | 1 | id | A | 5 | NULL | NULL | | BTREE | | |
| article | 1 | idx_article_ccv | 1 | category_id | A | 3 | NULL | NULL | | BTREE | | |
| article | 1 | idx_article_ccv | 2 | comments | A | 5 | NULL | NULL | | BTREE | | |
| article | 1 | idx_article_ccv | 3 | views | A | 5 | NULL | NULL | | BTREE | | |
+---------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
4 rows in set (0.00 sec)
查看现在SQL语句的执行计划。 #
mysql> EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+
| 1 | SIMPLE | article | NULL | range | idx_article_ccv | idx_article_ccv | 8 | NULL | 2 | 100.00 | Using index condition; Using filesort |
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.00 sec)
我们发现,创建符合索引
idx_article_ccv之后,虽然解决了全表扫描的问题,但是在order by排序的时候没有用到索引,MySQL居然还是用的Using filesort,为什么?
我们试试把SQL修改为SELECT id,author_id FROM article WHERE category_id = 1 AND comments = 1 ORDER BY views DESC LIMIT 1;看看SQL的执行计划。
#
mysql> EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments = 1 ORDER BY views DESC LIMIT 1;
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | article | NULL | ref | idx_article_ccv | idx_article_ccv | 8 | const,const | 1 | 100.00 | Using where |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
推论:当
comments > 1的时候order by排序views字段索引就用不上,但是当comments = 1的时候order by排序views字段索引就可以用上!!!所以,范围之后的索引会失效。
我们现在知道范围之后的索引会失效,原来的索引idx_article_ccv最后一个字段views会失效,那么我们如果删除这个索引,创建idx_article_cv索引呢????
#
drop index idx_article_ccv on article;
/* 创建索引 idx_article_cv */
CREATE INDEX idx_article_cv ON article(category_id,views);
show index from article;
查看当前的索引
mysql> show index from article;
+---------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| article | 0 | PRIMARY | 1 | id | A | 5 | NULL | NULL | | BTREE | | |
| article | 1 | idx_article_cv | 1 | category_id | A | 3 | NULL | NULL | | BTREE | | |
| article | 1 | idx_article_cv | 2 | views | A | 5 | NULL | NULL | | BTREE | | |
+---------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
当前索引是idx_article_cv,来看一下SQL执行计划。
#
mysql> EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
+----+-------------+---------+------------+-------+----------------+----------------+---------+------+------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+----------------+----------------+---------+------+------+----------+------------------------------------+
| 1 | SIMPLE | article | NULL | range | idx_article_cv | idx_article_cv | 4 | NULL | 3 | 33.33 | Using index condition; Using where |
+----+-------------+---------+------------+-------+----------------+----------------+---------+------+------+----------+------------------------------------+
1 row in set, 1 warning (0.00 sec)
两表索引分析—>左连接将索引创建在右表上更合适 #
数据准备 #
DROP TABLE IF EXISTS `class`;
DROP TABLE IF EXISTS `book`;
CREATE TABLE IF NOT EXISTS `class`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
`card` INT(10) UNSIGNED NOT NULL COMMENT '分类'
) COMMENT '商品类别';
CREATE TABLE IF NOT EXISTS `book`(
`bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
`card` INT(10) UNSIGNED NOT NULL COMMENT '分类'
) COMMENT '书籍';
两表连接查询的SQL执行计划
1、不创建索引的情况下,SQL的执行计划。
mysql> EXPLAIN select * from book left join class on book.card = class.card;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
book和class两张表都是没有使用索引,全表扫描,那么如果进行优化,索引是创建在book表还是创建在class表呢?下面进行大胆的尝试!
左表(book表)创建索引。
#
创建索引idx_book_card
/* 在book表创建索引 */
CREATE INDEX idx_book_card ON book(card);
在book表中有idx_book_card索引的情况下,查看SQL执行计划
mysql> EXPLAIN select * from book left join class on book.card = class.card;
+----+-------------+-------+------------+-------+---------------+---------------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | book | NULL | index | NULL | idx_book_card | 4 | NULL | 1 | 100.00 | Using index |
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+-------+---------------+---------------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
删除book表的索引,右表(class表)创建索引。
#
创建索引idx_class_card
drop index idx_book_card on book;
/* 在class表创建索引 */
CREATE INDEX idx_class_card ON class(card);
在class表中有idx_class_card索引的情况下,查看SQL执行计划
mysql> EXPLAIN select * from book left join class on book.card = class.card;
+----+-------------+-------+------------+------+----------------+----------------+---------+--------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+----------------+----------------+---------+--------------------+------+----------+-------------+
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | SIMPLE | class | NULL | ref | idx_class_card | idx_class_card | 4 | zxc_test.book.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+----------------+----------------+---------+--------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
由此可见,左连接将索引创建在右表上更合适,右连接将索引创建在左表上更合适。
三张表索引分析 #
数据准备 #
DROP TABLE IF EXISTS `phone`;
CREATE TABLE IF NOT EXISTS `phone`(
`phone_id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
`card` INT(10) UNSIGNED NOT NULL COMMENT '分类'
) COMMENT '手机';
三表连接查询SQL优化
不加任何索引,查看SQL执行计划。 #
mysql> EXPLAIN select * from class left join book on class.card = book.card left join phone on book.card = phone.card;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
| 1 | SIMPLE | phone | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
3 rows in set, 1 warning (0.00 sec)
根据两表查询优化的经验,左连接需要在右表上添加索引,所以尝试在book表和phone表上添加索引。
#
/* 在book表创建索引 */
CREATE INDEX idx_book_card ON book(card);
/* 在phone表上创建索引 */
CREATE INDEX idx_phone_card ON phone(card);
再次执行SQL的执行计划
ysql> /* book */
mysql> CREATE INDEX idx_book_card ON book(card);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql>
mysql> /* phone */
mysql> CREATE INDEX idx_phone_card ON phone(card);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql>
mysql>
mysql> EXPLAIN select * from class left join book on class.card = book.card left join phone on book.card = phone.card;
+----+-------------+-------+------------+------+----------------+----------------+---------+---------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+----------------+----------------+---------+---------------------+------+----------+-------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | idx_book_card | idx_book_card | 4 | zxc_test.class.card | 1 | 100.00 | Using index |
| 1 | SIMPLE | phone | NULL | ref | idx_phone_card | idx_phone_card | 4 | zxc_test.book.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+----------------+----------------+---------+---------------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
结论 #
JOIN语句的优化:
- 尽可能减少
JOIN语句中的NestedLoop(嵌套循环)的总次数:永远都是小的结果集驱动大的结果集。 - 优先优化
NestedLoop的内层循环。 - 保证
JOIN语句中被驱动表上JOIN条件字段已经被索引。 - 当无法保证被驱动表的
JOIN条件字段被索引且内存资源充足的前提下,不要太吝惜Join Buffer的设置。
索引失效 #
数据准备
CREATE TABLE `staffs`(
`id` INT(10) PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` INT(10) NOT NULL DEFAULT 0 COMMENT '年龄',
`pos` VARCHAR(20) NOT NULL DEFAULT '' COMMENT '职位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间'
)COMMENT '员工记录表';
INSERT INTO `staffs`(`name`,`age`,`pos`) VALUES('Ringo', 18, 'manager');
INSERT INTO `staffs`(`name`,`age`,`pos`) VALUES('张三', 20, 'dev');
INSERT INTO `staffs`(`name`,`age`,`pos`) VALUES('李四', 21, 'dev');
/* 创建索引 */
CREATE INDEX idx_staffs_name_age_pos ON `staffs`(`name`,`age`,`pos`);
索引失效的情况 #
- 全值匹配我最爱。
- 最佳左前缀法则。
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描。
- 索引中范围条件右边的字段会全部失效。
- 尽量使用覆盖索引(只访问索引的查询,索引列和查询列一致),减少
SELECT *。 - MySQL在使用
!=或者<>的时候无法使用索引会导致全表扫描。 is null、is not null也无法使用索引。like以通配符开头%abc索引失效会变成全表扫描。- 字符串不加单引号索引失效。
- 少用
or,用它来连接时会索引失效。
最佳左前缀法则 #
案例
/* 用到了idx_staffs_name_age_pos索引中的name字段 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo';
/* 用到了idx_staffs_name_age_pos索引中的name, age字段 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18;
/* 用到了idx_staffs_name_age_pos索引中的name,age,pos字段 这是属于全值匹配的情况!!!*/
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager';
/* 索引没用上,ALL全表扫描 */
EXPLAIN SELECT * FROM `staffs` WHERE `age` = 18 AND `pos` = 'manager';
/* 索引没用上,ALL全表扫描 */
EXPLAIN SELECT * FROM `staffs` WHERE `pos` = 'manager';
/* 用到了idx_staffs_name_age_pos索引中的name字段,pos字段索引失效 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `pos` = 'manager';
概念
最佳左前缀法则:如果索引是多字段的复合索引,要遵守最佳左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的字段。
口诀:带头大哥不能死,中间兄弟不能断。
索引列上不计算 #
案例
# 现在要查询`name` = 'Ringo'的记录下面有两种方式来查询!
# 1、直接使用 字段 = 值的方式来计算
mysql> SELECT * FROM `staffs` WHERE `name` = 'Ringo';
+----+-------+-----+---------+---------------------+
| id | name | age | pos | add_time |
+----+-------+-----+---------+---------------------+
| 1 | Ringo | 18 | manager | 2020-08-03 08:30:39 |
+----+-------+-----+---------+---------------------+
1 row in set (0.00 sec)
# 2、使用MySQL内置的函数
mysql> SELECT * FROM `staffs` WHERE LEFT(`name`, 5) = 'Ringo';
+----+-------+-----+---------+---------------------+
| id | name | age | pos | add_time |
+----+-------+-----+---------+---------------------+
| 1 | Ringo | 18 | manager | 2020-08-03 08:30:39 |
+----+-------+-----+---------+---------------------+
1 row in set (0.00 sec)
我们发现以上两条SQL的执行结果都是一样的,但是执行效率有没有差距呢???
通过分析两条SQL的执行计划来分析性能。

由此可见,在索引列上进行计算,会使索引失效。
口诀:索引列上不计算。
范围之后全失效 #
案例
/* 用到了idx_staffs_name_age_pos索引中的name,age,pos字段 这是属于全值匹配的情况!!!*/
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager';
/* 用到了idx_staffs_name_age_pos索引中的name,age字段,pos字段索引失效 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = '张三' AND `age` > 18 AND `pos` = 'dev';
查看上述SQL的执行计划

由此可知,查询范围的字段使用到了索引,但是范围之后的索引字段会失效。
口诀:范围之后全失效。
覆盖索引尽量用 #
在写SQL的不要使用SELECT *,用什么字段就查询什么字段。
/* 没有用到覆盖索引 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager';
/* 用到了覆盖索引 */
EXPLAIN SELECT `name`, `age`, `pos` FROM `staffs` WHERE `name` = 'Ringo' AND `age` = 18 AND `pos` = 'manager';

口诀:查询一定不用*。
不等有时会失效 #
/* 会使用到覆盖索引 */
EXPLAIN SELECT `name`, `age`, `pos` FROM `staffs` WHERE `name` != 'Ringo';
/* 索引失效 全表扫描 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` != 'Ringo';
like百分加右边 #
/* 索引失效 全表扫描 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` LIKE '%ing%';
/* 索引失效 全表扫描 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` LIKE '%ing';
/* 使用索引范围查询 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` LIKE 'Rin%';
口诀:like百分加右边。
如果一定要使用%like,而且还要保证索引不失效,那么使用覆盖索引来编写SQL。
/* 使用到了覆盖索引 */
EXPLAIN SELECT `id` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆盖索引 */
EXPLAIN SELECT `name` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆盖索引 */
EXPLAIN SELECT `age` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆盖索引 */
EXPLAIN SELECT `pos` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆盖索引 */
EXPLAIN SELECT `id`, `name` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆盖索引 */
EXPLAIN SELECT `id`, `age` FROM `staffs` WHERE `name` LIKE '%in%';
/* 使用到了覆盖索引 */
EXPLAIN SELECT `id`,`name`, `age`, `pos` FROM `staffs` WHERE `name` LIKE '%in';
/* 使用到了覆盖索引 */
EXPLAIN SELECT `id`, `name` FROM `staffs` WHERE `pos` LIKE '%na';
/* 索引失效 全表扫描 */
EXPLAIN SELECT `name`, `age`, `pos`, `add_time` FROM `staffs` WHERE `name` LIKE '%in';

口诀:覆盖索引保两边。
字符要加单引号 #
/* 使用到了覆盖索引 */
EXPLAIN SELECT `id`, `name` FROM `staffs` WHERE `name` = 'Ringo';
/* 使用到了覆盖索引 */
EXPLAIN SELECT `id`, `name` FROM `staffs` WHERE `name` = 2000;
/* 索引失效 全表扫描 */
EXPLAIN SELECT * FROM `staffs` WHERE `name` = 2000;
这里name = 2000在MySQL中会发生强制类型转换,将数字转成字符串。
口诀:字符要加单引号。
索引相关题目 #
假设index(a,b,c)
| Where语句 | 索引是否被使用 |
|---|---|
| where a = 3 | Y,使用到a |
| where a = 3 and b = 5 | Y,使用到a,b |
| where a = 3 and b = 5 | Y,使用到a,b,c |
| where b = 3 或者 where b = 3 and c = 4 或者 where c = 4 | N,没有用到a字段 |
| where a = 3 and c = 5 | 使用到a,但是没有用到c,因为b断了 |
| where a = 3 and b > 4 and c = 5 | 使用到a,b,但是没有用到c,因为c在范围之后 |
| where a = 3 and b like ‘kk%’ and c = 4 | Y,a,b,c都用到 |
| where a = 3 and b like ‘%kk’ and c = 4 | 只用到a |
| where a = 3 and b like ‘%kk%’ and c = 4 | 只用到a |
| where a = 3 and b like ‘k%kk%’ and c = 4 | Y,a,b,c都用到 |
面试题分析 #
数据准备
/* 创建表 */
CREATE TABLE `test03`(
`id` INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
`c1` CHAR(10),
`c2` CHAR(10),
`c3` CHAR(10),
`c4` CHAR(10),
`c5` CHAR(10)
);
/* 插入数据 */
INSERT INTO `test03`(`c1`,`c2`,`c3`,`c4`,`c5`) VALUES('a1','a2','a3','a4','a5');
INSERT INTO `test03`(`c1`,`c2`,`c3`,`c4`,`c5`) VALUES('b1','b22','b3','b4','b5');
INSERT INTO `test03`(`c1`,`c2`,`c3`,`c4`,`c5`) VALUES('c1','c2','c3','c4','c5');
INSERT INTO `test03`(`c1`,`c2`,`c3`,`c4`,`c5`) VALUES('d1','d2','d3','d4','d5');
INSERT INTO `test03`(`c1`,`c2`,`c3`,`c4`,`c5`) VALUES('e1','e2','e3','e4','e5');
/* 创建复合索引 */
CREATE INDEX idx_test03_c1234 ON `test03`(`c1`,`c2`,`c3`,`c4`);
题目
/* 最好索引怎么创建的,就怎么用,按照顺序使用,避免让MySQL再自己去翻译一次 */
/* 1.全值匹配 用到索引c1 c2 c3 c4全字段 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c3` = 'a3' AND `c4` = 'a4';
/* 2.用到索引c1 c2 c3 c4全字段 MySQL的查询优化器会优化SQL语句的顺序*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c4` = 'a4' AND `c3` = 'a3';
/* 3.用到索引c1 c2 c3 c4全字段 MySQL的查询优化器会优化SQL语句的顺序*/
EXPLAIN SELECT * FROM `test03` WHERE `c4` = 'a4' AND `c3` = 'a3' AND `c2` = 'a2' AND `c1` = 'a1';
/* 4.用到索引c1 c2 c3字段,c4字段失效,范围之后全失效 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c3` > 'a3' AND `c4` = 'a4';
/* 5.用到索引c1 c2 c3 c4全字段 MySQL的查询优化器会优化SQL语句的顺序*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c4` > 'a4' AND `c3` = 'a3';
/*
6.用到了索引c1 c2 c3三个字段, c1和c2两个字段用于查找, c3字段用于排序了但是没有统计到key_len中,c4字段失效
*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c4` = 'a4' ORDER BY `c3`;
/* 7.用到了索引c1 c2 c3三个字段,c1和c2两个字段用于查找, c3字段用于排序了但是没有统计到key_len中*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' ORDER BY `c3`;
/*
8.用到了索引c1 c2两个字段,c4失效,c1和c2两个字段用于查找,c4字段排序产生了Using filesort说明排序没有用到c4字段
*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' ORDER BY `c4`;
/* 9.用到了索引c1 c2 c3三个字段,c1用于查找,c2和c3用于排序 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c5` = 'a5' ORDER BY `c2`, `c3`;
/* 10.用到了c1一个字段,c1用于查找,c3和c2两个字段索引失效,产生了Using filesort */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c5` = 'a5' ORDER BY `c3`, `c2`;
/* 11.用到了c1 c2 c3三个字段,c1 c2用于查找,c2 c3用于排序 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' ORDER BY c2, c3;
/* 12.用到了c1 c2 c3三个字段,c1 c2用于查找,c2 c3用于排序 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c5` = 'a5' ORDER BY c2, c3;
/*
13.用到了c1 c2 c3三个字段,c1 c2用于查找,c2 c3用于排序 没有产生Using filesort
因为之前c2这个字段已经确定了是'a2'了,这是一个常量,再去ORDER BY c3,c2 这时候c2已经不用排序了!
所以没有产生Using filesort 和(10)进行对比学习!
*/
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c2` = 'a2' AND `c5` = 'a5' ORDER BY c3, c2;
/* GROUP BY 表面上是叫做分组,但是分组之前必定排序。 */
/* 14.用到c1 c2 c3三个字段,c1用于查找,c2 c3用于排序,c4失效 */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c4` = 'a4' GROUP BY `c2`,`c3`;
/* 15.用到c1这一个字段,c4失效,c2和c3排序失效产生了Using filesort */
EXPLAIN SELECT * FROM `test03` WHERE `c1` = 'a1' AND `c4` = 'a4' GROUP BY `c3`,`c2`;
GROUP BY基本上都需要进行排序,索引优化几乎和ORDER BY一致,但是GROUP BY会有临时表的产生。
总结 #
索引优化的一般性建议:
- 对于单值索引,尽量选择针对当前
query过滤性更好的索引。 - 在选择复合索引的时候,当前
query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。 - 在选择复合索引的时候,尽量选择可以能够包含当前
query中的where子句中更多字段的索引。 - 尽可能通过分析统计信息和调整
query的写法来达到选择合适索引的目的。
口诀:
- 带头大哥不能死。
- 中间兄弟不能断。
- 索引列上不计算。
- 范围之后全失效。
- 覆盖索引尽量用。
- 不等有时会失效。
- like百分加右边。
- 字符要加单引号。
- 一般SQL少用or。