表空间的格式 #
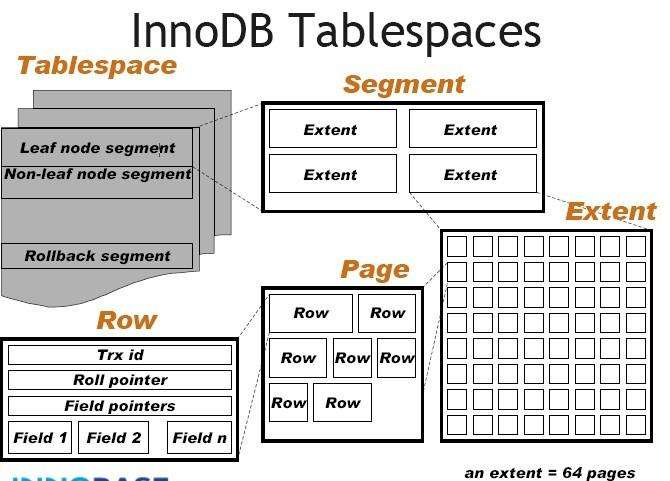
segment和extent是InnoDB内部用于分配管理页的逻辑结构(物理上不存在,只是逻辑上存在这样的上下级关系,物理上都是页组成),用于分配与回收页,对于写入数据的性能至关重要。
但这张图有所局限性,可能会产生误解:
- 图中是系统表空间,因此存在rollback segment,独立表空间则没有。
- leaf node segment实际是InnoDB的inode概念,一个segment可能包含最多32个碎片page、0个extent(用于小表优化),或者是非常多的extent,我猜测作者图中画了4个extent是在描述表超过32MB大小的时候一次申请4个extent。
- 一个extent在默认16k的page大小下,由64个page组成,page大小由UNIV_PAGE_SIZE定义,所以extent不一定由64个page组成。
- 表的所有行数据都存在页类型为INDEX的索引页(page)上,为了管理表空间,还需要很多其他的辅助页,例如文件管理页FSP_HDR/XDES、插入缓冲IBUF_BITMAP页、INODE页等。
页的结构 #
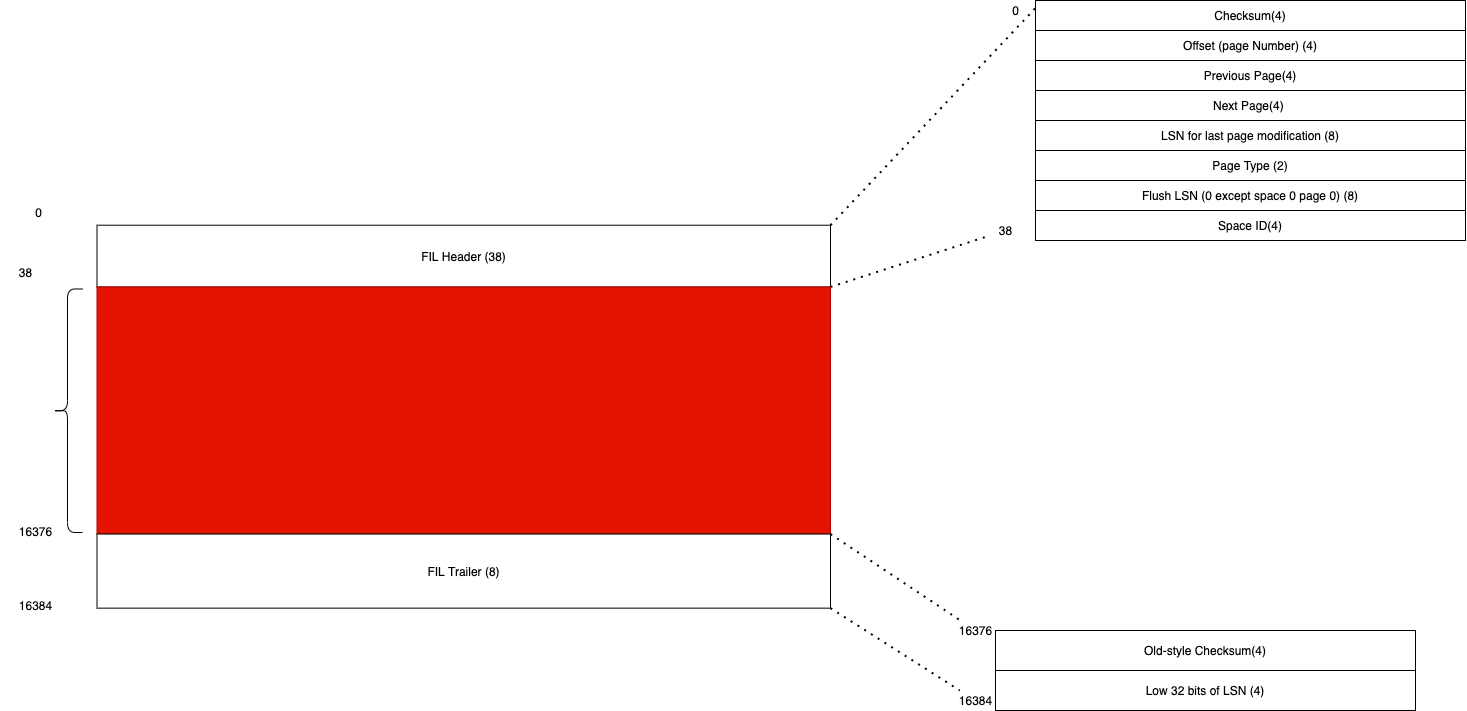
MySQL一次IO的最小单位是页(page),也可以理解为一次原子操作都是以page为单位的,默认大小16k。刚刚列出的所有物理文件结构上都是以Page构成的,只是page内部的结构不同。
文件管理页 #
- 文件管理页的页类型是FSP_HDR和XDES(extent descriptor),用于分配、管理extent和page。
- FSP_HDR和XDES的唯一区别,它们两者除了
FSP Header这个位置在FSP_HDR有值,在XDES中是用0填充外, 其他field都一样。FSP Header这个field,它在XDES页中是空的(zero-filled for XDES pages) ---> (112); page 0(FSP_HDR页面)中FSP_HDR中有值。- FSP_HDR页都是page 0,XDES页一般出现在page 16384, 32768等固定的位置。一个FSP_HDR或者XDES页大小同样是16K。
- 一般情况下,每个extent都有一个占40字节的XDES entry描述维护,Innodb这里定义了一个页保存256个extent描述符, 每个区描述符所在页的偏移量都是16384(256x64, 16384, 后续随着空间文件增大,XDES页会在16384,32768等位置), 换言之管理256M,16384个page)。
- FSP header: 里面最重要的信息就是四个链表头尾数据(FLST_BASE_NODE结构,FLST意思是first and last),FLST_BASE_NODE如下。
- 1)当一个Extent中所有page都未被使用时,挂在FSP_FREE list base node上,可以用于随后的分配;
- 2)有一部分page被写入的extent,挂在FREE_FRAG list base node上;
- 3)全满的extent,挂在FULL_FRAG list base node上;
- 4)归属于某个segment时候挂在FSEG list base node上。
- 当InnoDB写入数据的时候,会从这些链表上分配或者回收extent和page,这些extent也都是在这几个链表上移动的。
- XDES entry 存储所管理的extent状态:
- 1)FREE(空)
- 2)FREE_FRAG(至少一个被占用)
- 3)FULL_FRAG(满)
- 4)归某个segment管理的信息
- XDES entry还存储了每个extent内部page是否free(有空间)信息(用bitmap表示)。XDES entry组成了一个双向链表,同一种extent状态的收尾连在一起,便于管理。
- FSP header: 里面最重要的信息就是四个链表头尾数据(FLST_BASE_NODE结构,FLST意思是first and last),FLST_BASE_NODE如下。
- FSP_HDR和XDES的唯一区别,它们两者除了
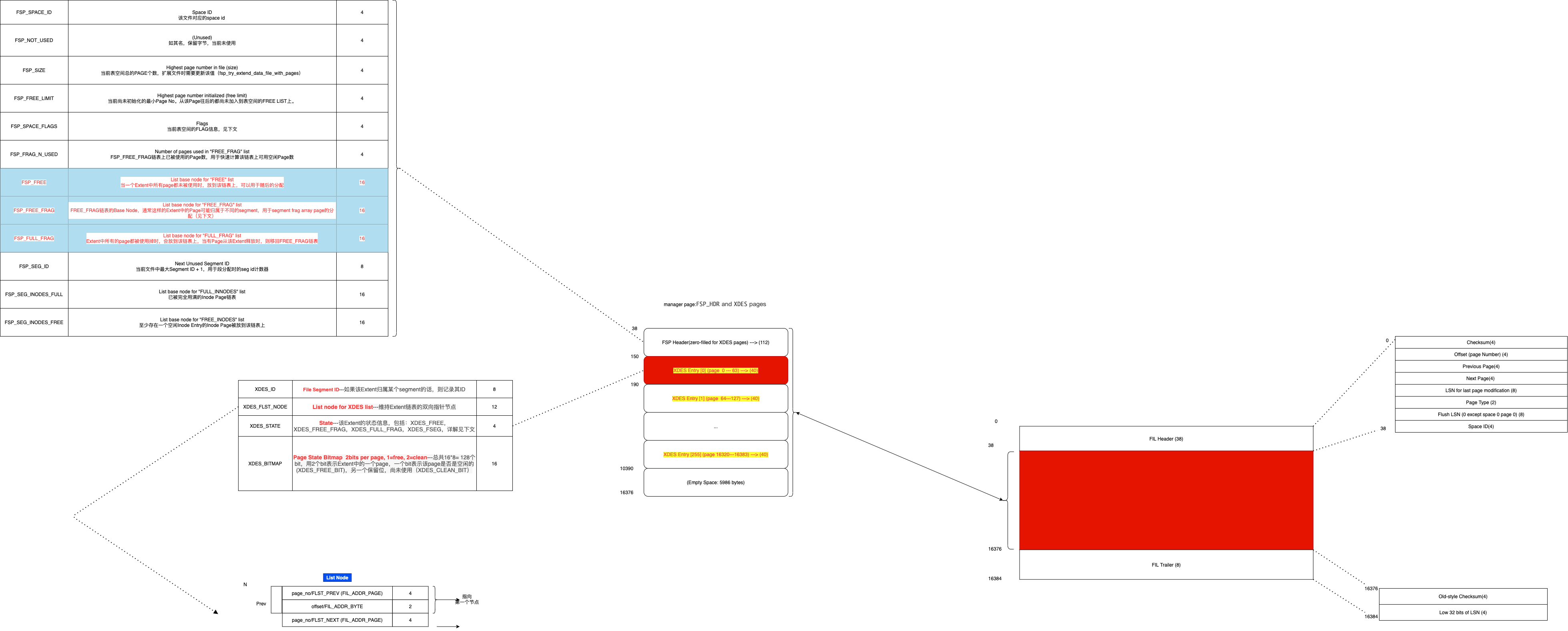
INODE页 #
what:
why:
how:
- segment是表空间管理的逻辑单位。INODE页就是用于管理segment的,每个Inode entry负责一个segment。
- 一个segment由32个碎片页(fragment array),FSEG_FREE、FSEG_NOT_FULL、FSEG_FULL组成,这些信息记录在Inode entry里,可以简单理解为Inode就是segment元信息的载体。
- segment是表空间管理的逻辑单位。INODE页就是用于管理segment的,每个Inode entry负责一个segment。
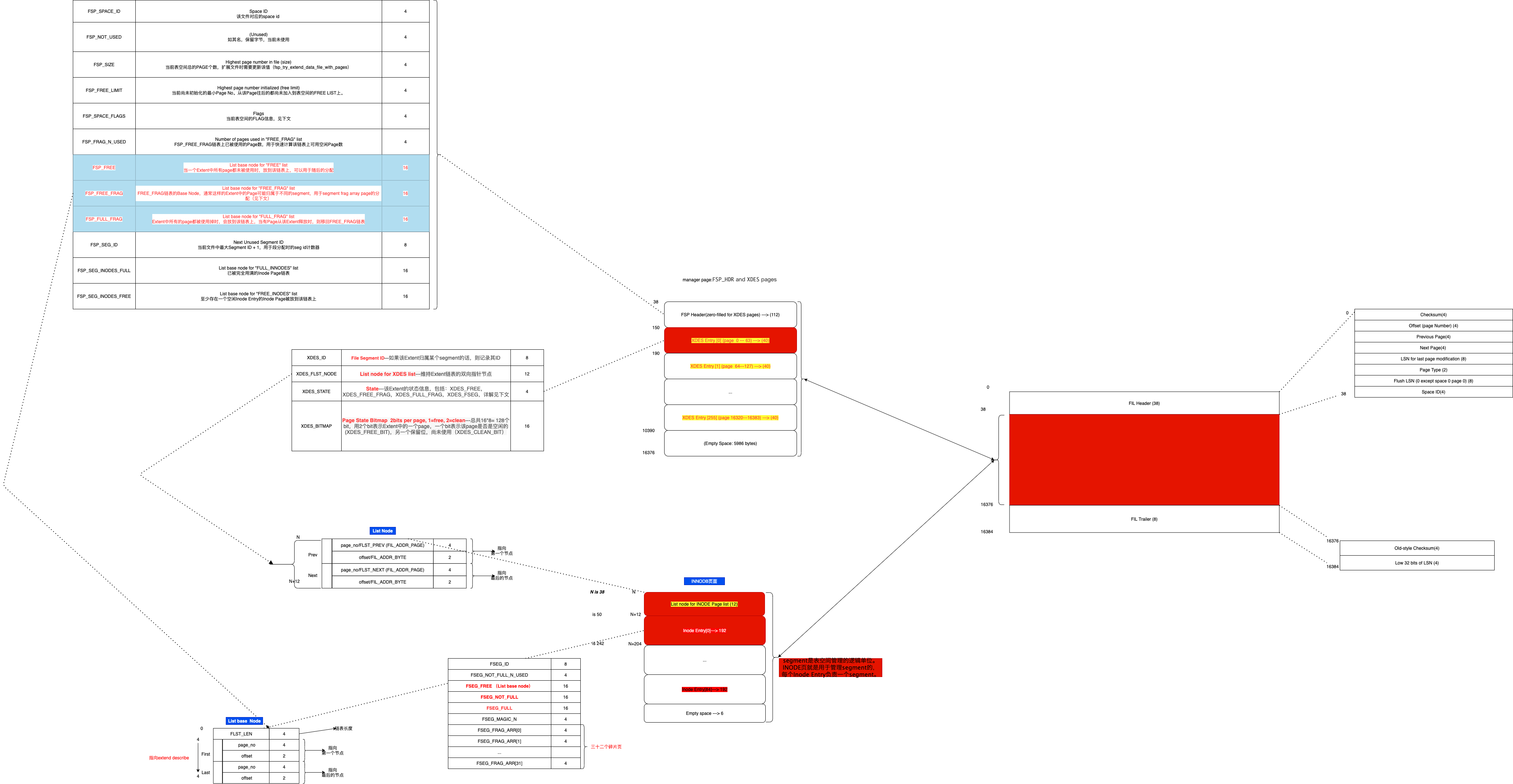
说说List base node这种数据结构, 它结构如下:
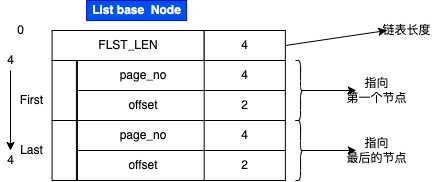
- FSEG_FREE、FSEG_NOT_FULL、FSEG_FULL都是属于这种结构对象
- FSP_HDR/XDES页里面的FSP_FREE、FREE_FRAG、FULL_FRAG、FSEG也是。 这些链表被InnoDB使用,用于高效的管理页分配和回收。
至于碎片页上(fragment array),用于优化小表空间分配,先从全局的碎片分配Page,当fragment array填满(32个槽位)时,之后每次分配一个完整的Extent,如果表大于32MB,则一次分配4个extent。
MySQL的数据是按照B+ tree聚簇索引(clustered index)组织数据的,每个B+ tree使用两个segment来管理page,分别是leaf node segment(叶子节点segment)和non-leaf node segment(非叶子节点segment)。
- 这两个segment的Inode entry地址记录在B+ tree的root page中FSEG_HEADER里面,而root page又被分配在non-leaf segment第一个碎片页上(fragment array)。
INDEX数据索引页 #
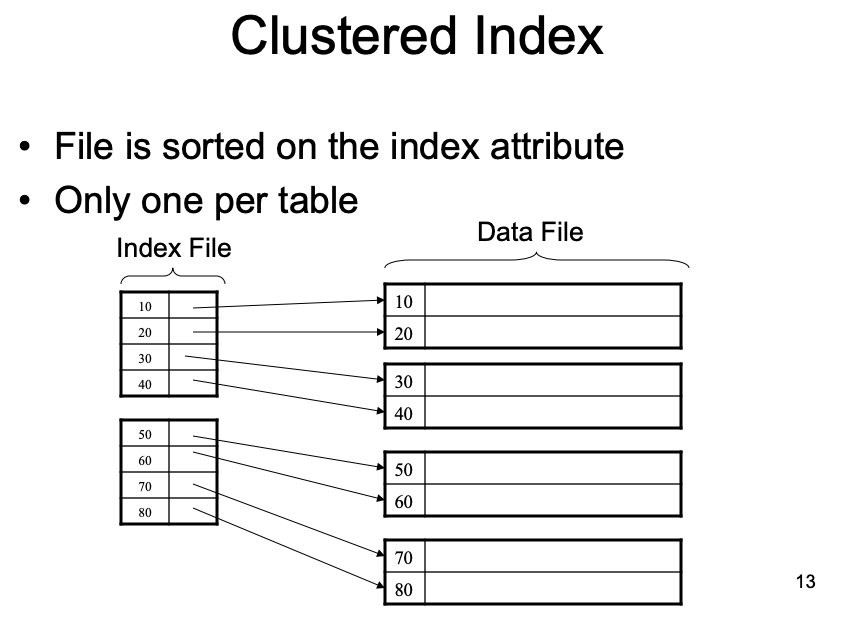
索引(index)用于快速定位数据,对于InnoDB来说,主键和非主键都是索引,一切数据都存储在INDEX索引页中,索引即数据,数据即索引。 clustered index将数据按照索引的顺序存储。通常来讲,索引和数据在一起,找到了索引也就找到了数据(但不一定强求)。 unclustered index则将数据与索引分开结构,索引指向了具体的记录。索引相近的记录,在物理文件上相距可能很远。
主键索引, 为聚簇索引。
二级索引,就可以理解为非聚簇索引,也是一颗B+树,只不过这棵树的叶子节点是指向聚簇索引主键的,可以看做“行指针”,因此查询的时候需要“回表”。
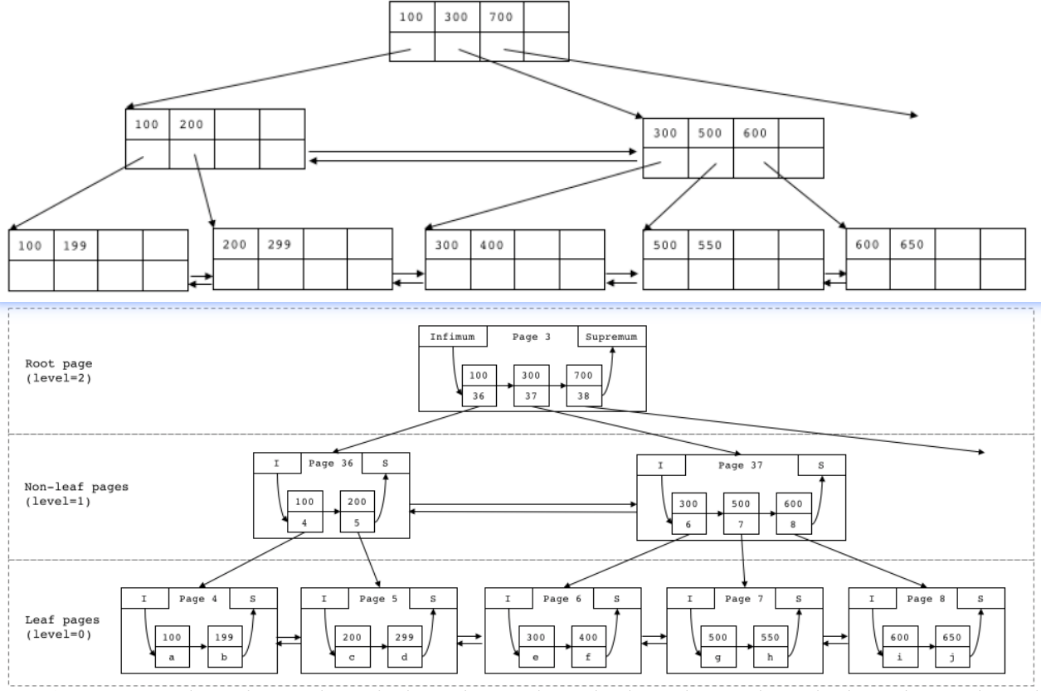
B+树结构特点:
- 叶子节点(leaf node)存储数据,非叶子节点(non-leaf node)只是索引,这样非叶子节点就会足够的小,因此数据很“热”,便于更好的缓存。
- 数据和索引顺序一致,充分利用磁盘顺序IO性能普遍高于随机IO的特性。
- 并且有引用横向链接,支持范围查找, 可以在2-3次的IO操作内完成千万级别的表操作;
索引的结构
聚簇和非聚簇 #
- what:
- Clustered/Unclustered
- Clustered
- Index determines the location of indexed records
- Typically, clustered index is one where values are data records (but not necessary)
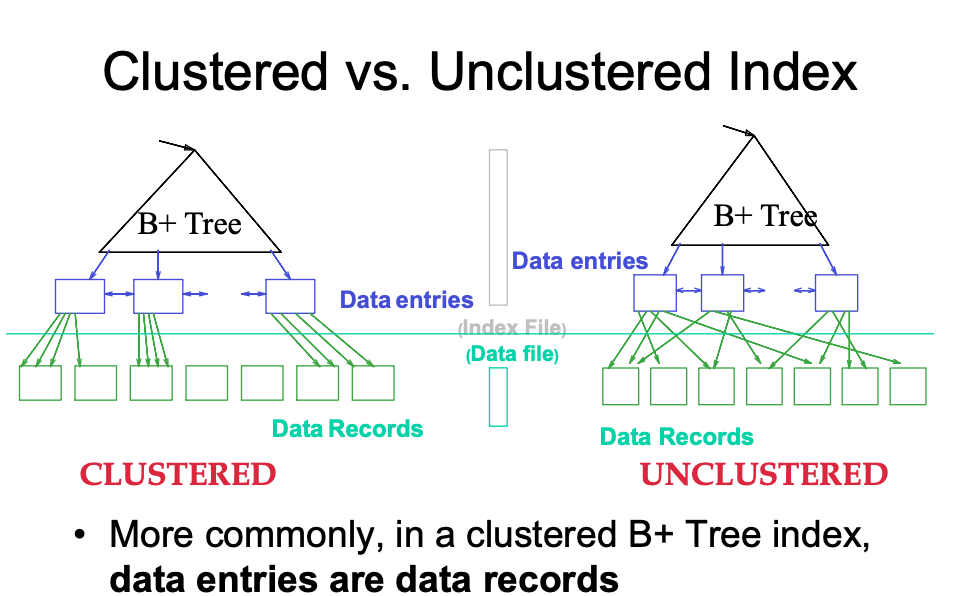
- Unclustered
- Index cannot reorder data, does not determine data location
- In these indexes: value = pointer to data record
- Clustered
- Clustered/Unclustered
- why:
- how:
- 就是它的实际数据也是按照顺序排的,那么可以向上和向下查找,但是如果是非聚族的,它如果想找比它大一点点的值,你不可能从Data file里面就能找到,你必须回归到Data entries?
- 使用B+树聚簇索引(B+ tree clustered index)的好处在于,
- 1)数据和索引顺序一致,充分利用磁盘顺序IO性能普遍高于随机IO的特性。
- 2)对于局部性查询也会大有裨益。
- 3)采用B+树,叶子节点(leaf node)存储数据,非叶子节点(non-leaf node)只是索引,这样非叶子节点就会足够的小(一个页面就能存储很多的节点,查找的时候,减少了磁盘io),因此数据很“热”,便于更好的缓存。
- 4)对于覆盖索引,可以直接利用叶子节点的主键值。
- 二级索引,就可以理解为非聚簇索引,也是一颗B+树,只不过这棵树的叶子节点是指向聚簇索引主键的,可以看做“行指针”,因此查询的时候需要“回表”。
index #
what:
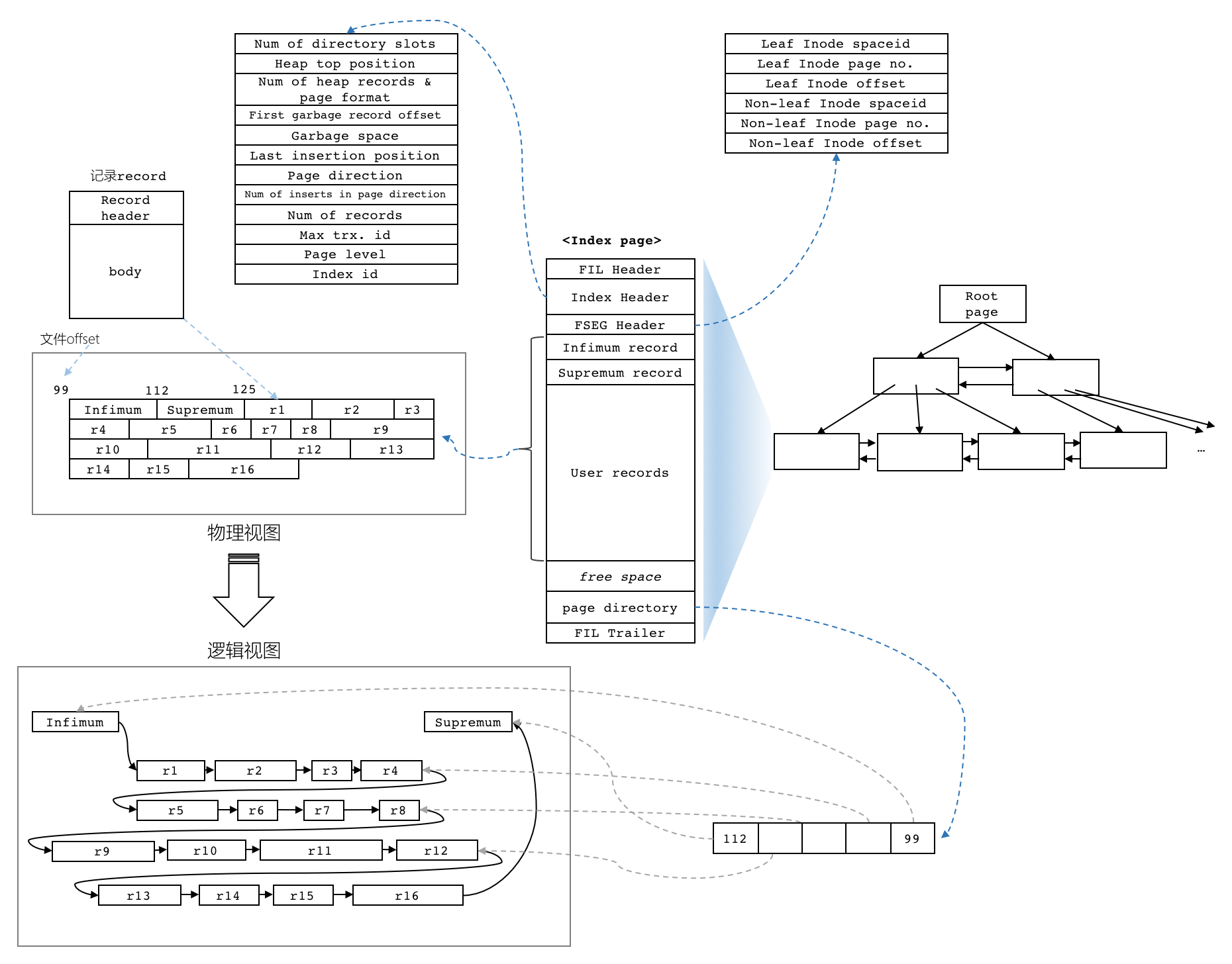
- 主键、二级索引、行和列
- B+树的**每个节点(包括叶子和非叶子节点)**都是一个INDEX索引页,其结构都是相同的;
- 对于聚簇索引,非叶子节点包含主键和child page number,叶子节点包含主键和具体的行;
- 对于非聚簇索引,也就是二级索引,非叶子节点包含二级索引和child page number,叶子节点包含二级索引和主键值。
- 叶子和非叶子都在index索引页,那么inode里面保存的segment信息,是不是这个segment用的所有页都能从这里找到,(先用的32个碎片页,然后也能从管理页中申请extent?)
- 主键、二级索引、行和列
why:
how:
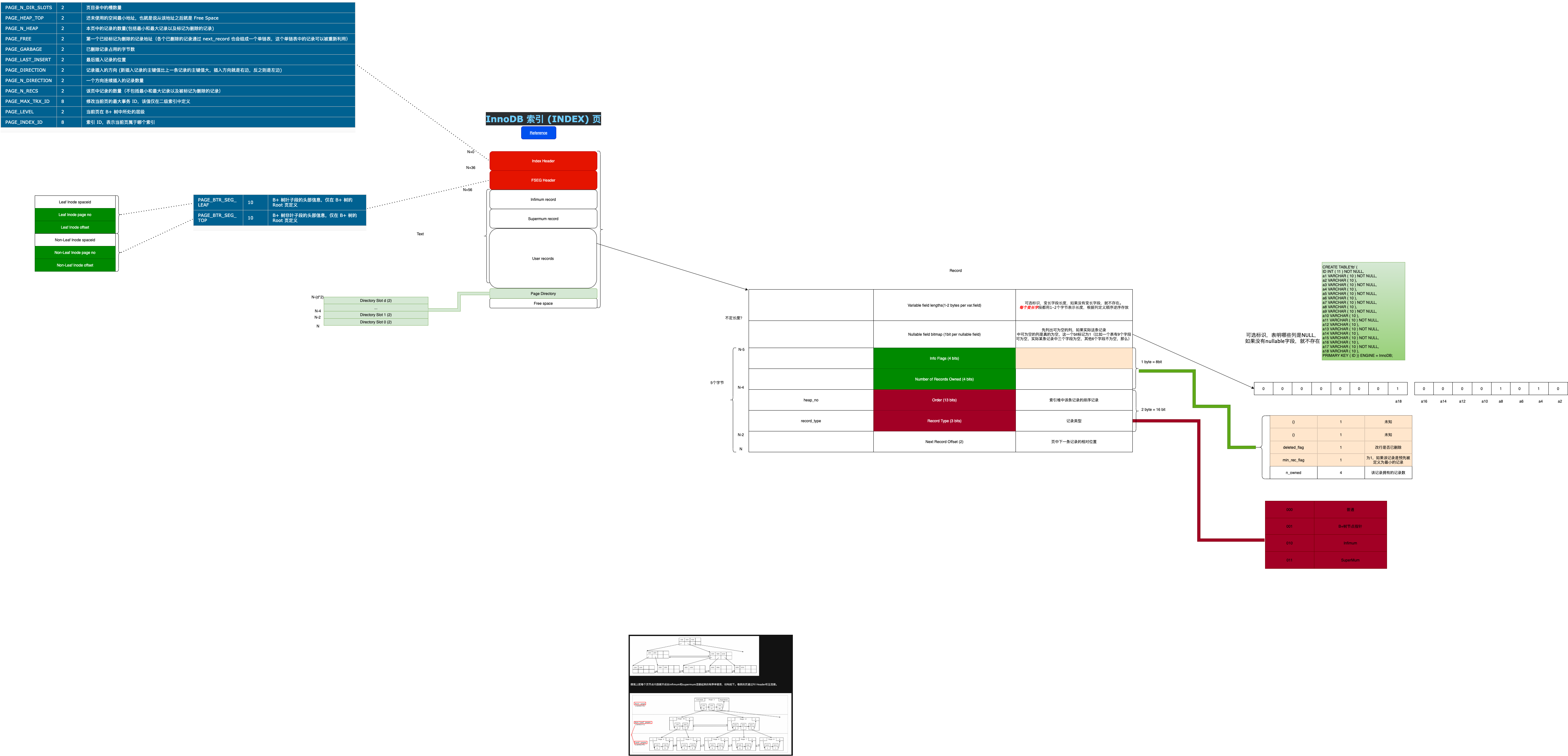
- page directory从Fil Trailer开始从后往前写,里面包含槽位slots,每个slot 2个字节,存储了某些record在该页中的物理偏移量,例如图中最后面是infimum record的offset,最前面是supremum record的offset,中间从后往前是r4,r8,r12 record的offset,一般总是每隔4-8个record添加一个slot,这样slots就等同于一个稀疏索引(sparse index),加速页内查询的办法就是通过二分查找,查询key的时间复杂度可以降为O(logN),由于页都在内存里面,所以查询性能可控,内存访问延迟100ns左右,如果在CPU缓存中则可能更快。
Row Format #
what: #
row format可通过innodb_default_row_format参数指定,也可以在建表的时候指定。
CREATE TABLE choose_row_format (
id INT,
) ENGINE=InnoDB ROW_FORMAT=DYNAMIC;
- REDUNDANT: 是比较老的格式,
- COMPACT: 5.6版本默认,COMPACT比REDUNDANT要更节省空间,大概在20%左右。
- DYNAMIC: 5.7版本默认,DYNAMIC在变长存储上做了更大的空间优化,对于VARBINARY, VARCHAR, BLOB和TEXT类型更友好,
- COMPRESSED是压缩页。
what: #
how: #
row的格式在上面图中简单介绍过,由可选的两个标识+record header+body组成,具体如下。
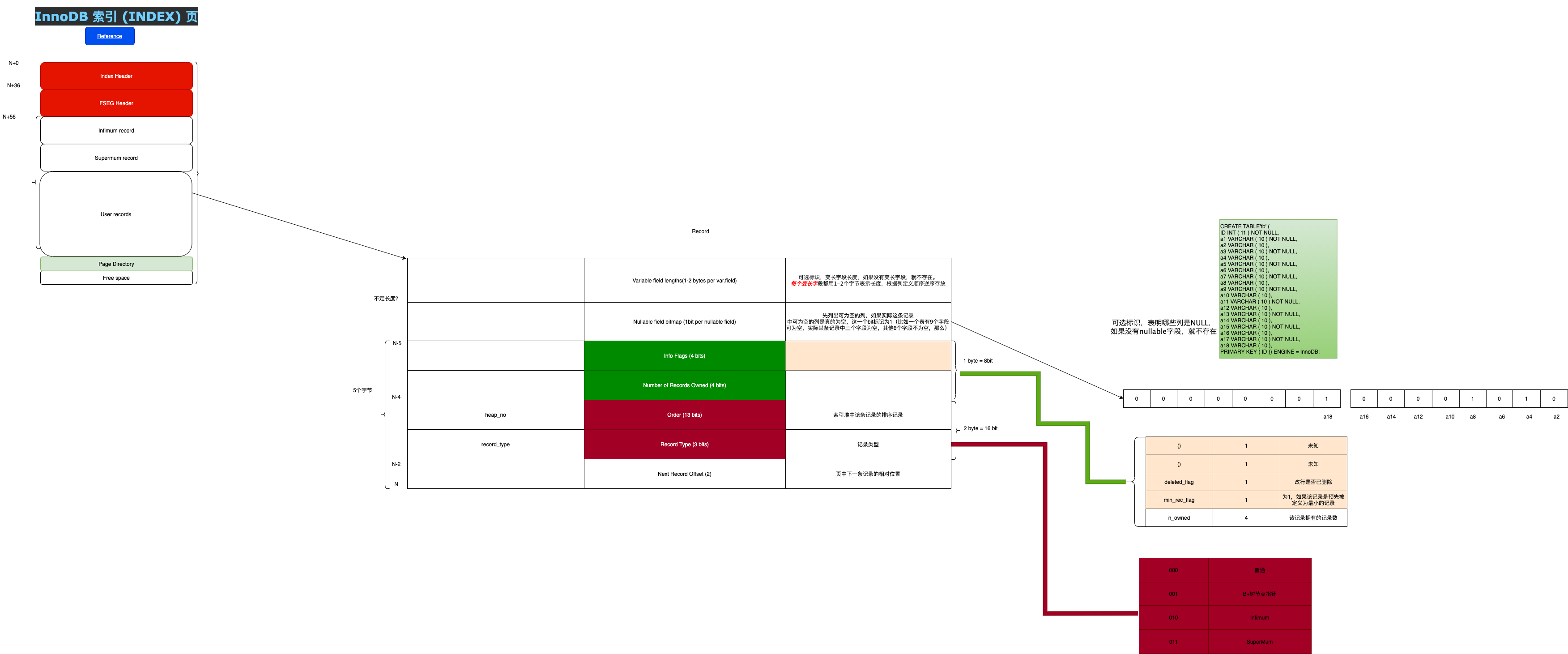
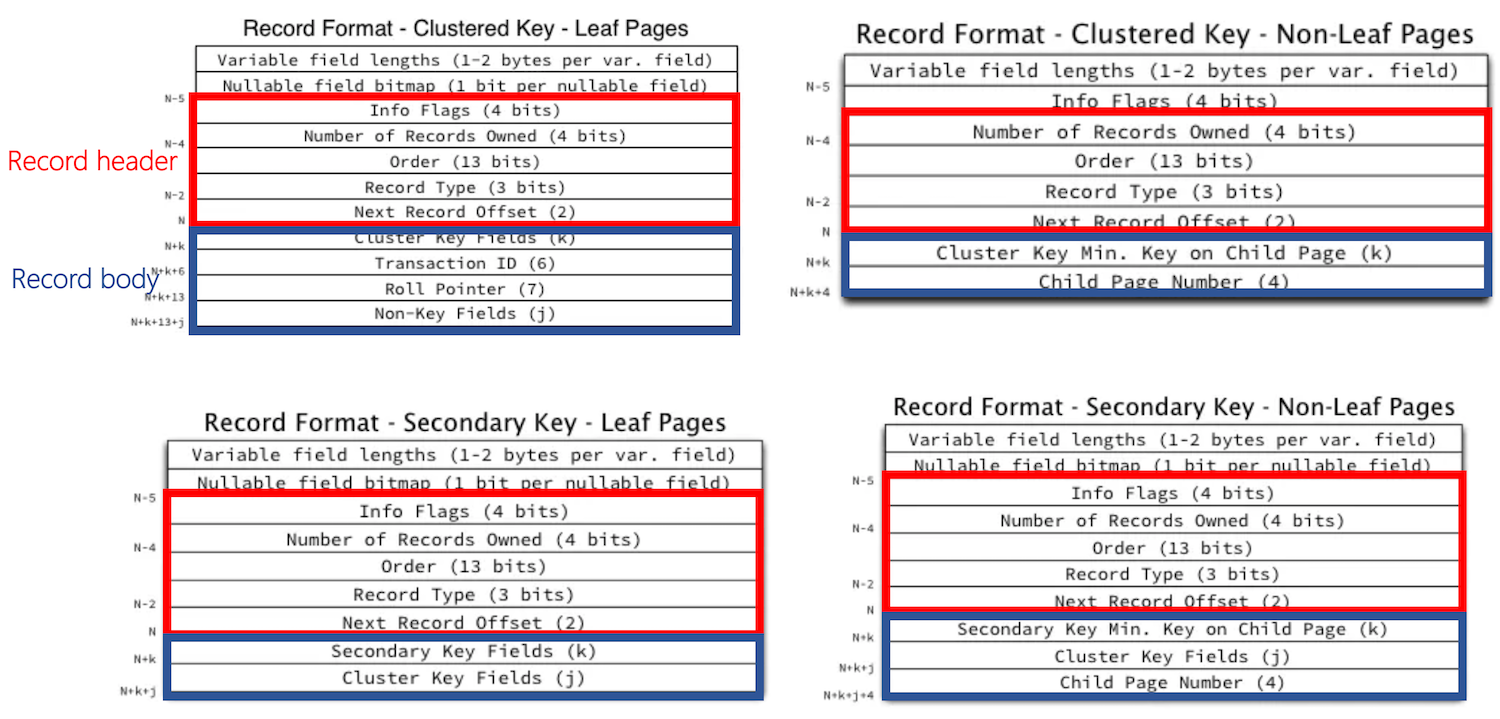
4)索引:序列化后存储于此,例如int类型索引主键就占用4个字节。 对于聚簇索引的叶子节点,存储行。 对于二级索引的叶子节点,存储行的主键值。 对于聚簇索引和二级索引的非叶子节点,存储child page最小的key。 上面提到的infimum和supremum中就只存字符串在行数据里。
讨论innodb数据结构 #
- 索引最终选择B+树的原因:
- 1,范围查询,2,减少磁盘IO
- 减少IO的次数,每次读取尽可能多的数据.
- 因为B+树非叶子节点没有数据,可以存储更多的节点或者叫索引数据,比B树更加矮胖,可以更快的定位到叶子节点,自然就减少了磁盘IO的次数。
- 如果范围数据左右子树都有
- B+树的数据结构特点是:数据都在叶子节点,而叶子节点又是通过指针相连,是有序链表.
- 减少IO的次数,每次读取尽可能多的数据.
- 1,范围查询,2,减少磁盘IO
- hash很快,但每次IO只能取一个数(范围查找不适合);
- 哈希索引只需要计算一次就可以获取到对应的数据,检索速度非常快。但是 Mysql 并没有采取哈希作为其底层算法,这是为什么呢?因为考虑到数据检索有一个常用手段就是范围查找,比如以下这个 SQL 语句:
select \* from user where id \>3;针对以上这个语句,我们希望做的是找出 id>3 的数据,这是很典型的范围查找。如果使用哈希算法实现的索引,范围查找怎么做呢?一个简单的思路就是一次把所有数据找出来加载到内存,然后再在内存里筛选筛选目标范围内的数据。但是这个范围查找的方法也太笨重了,没有一点效率而言。- 所以,使用哈希算法实现的索引虽然可以做到快速检索数据,但是没办法做数据高效范围查找,因此哈希索引是不适合作为 Mysql 的底层索引的数据结构。
- 哈希索引只需要计算一次就可以获取到对应的数据,检索速度非常快。但是 Mysql 并没有采取哈希作为其底层算法,这是为什么呢?因为考虑到数据检索有一个常用手段就是范围查找,比如以下这个 SQL 语句:
- AVL和红黑树,在大量数据的情况下,IO操作还是太多;
- B树每个节点内存储的是数据,因此每个节点存储的分支太少;
- B+节点存储的是索引+指针(引用指向下一个节点),可以存储大量索引,同时最终
- 非叶子节点没有数据;数据存储在叶子节点.
- 并且有引用横向链接,可以在2-3次的IO操作内完成千万级别的表操作;
- 建议索引是是自增长数字,这样适合范围查找.