goroutine被动调度 #
什么是被动调度: goroutine执行某个操作因条件不满足需要等待而发生的调度
- goroutine进入睡眠
- 比如是goroutineN发送数据到无缓冲chan上面,当没有其他Goroutine从chan上面读数据的时候,goroutineN阻塞在chan上面. 此刻睡眠含义:进入chan的缓存读取队列(goroutine链表)
- 重新运行schedule()
- 唤醒睡眠中的goroutine;
- 唤醒空闲的P和唤醒/创建工作线程;
- goroutine(被创建出来后/创建运行了一段时间后)如何放入运行队列P中
被动进入睡眠 #
- goroutine因某个条件而阻塞
- chan
- waitGroup 等这些都会发生阻塞
package main
import (
"fmt"
"runtime"
"sync"
"sync/atomic"
)
func main() {
var n int32
var wg sync.WaitGroup
runtime.GOMAXPROCS(2)
wg.Add(1)
go func() {
wg.Done()
for{
atomic.AddInt32(&n, 1)
}
}()
wg.Wait()
fmt.Println(atomic.LoadInt32(&n)) // 1
}

gdb调试前准备 #
编译程序 #
编译一下源代码: go build -gcflags "-N -l" -o test ..
准备mcall函数断点的文件 #
进入wg.Wait()
我们都知道main函数里面的wg.Wait()这个只有当wg的计数器到0后才会继续执行,来看看当wg还没有到0的时候,这里会发生什么呢?
| |
runtime_Semacquire #
// src/sync/runtime.go // Semacquire waits until *s > 0 and then atomically decrements it. // It is intended as a simple sleep primitive for use by the synchronization // library and should not be used directly. func runtime_Semacquire(s *uint32)这里类似PV操作, 但是:
- P:等待直到(*s)大于0, 然后才自动减(也就是如果是等于0, 那么就会休眠)
- v:首先自动增加(*s),唤醒被等待的goroutine.
// src/sync/runtime.go // Semacquire waits until *s > 0 and then atomically decrements it. // It is intended as a simple sleep primitive for use by the synchronization // library and should not be used directly. func runtime_Semacquire(s *uint32)继续下去发现找不到定义了, 我们gdb查找一下:
list /usr/lib/golang/src/sync/waitgroup.go:130 b 130 list /usr/lib/golang/src/sync/runtime.go:1 b 130 (gdb) info break Num Type Disp Enb Address What 1 breakpoint keep y 0x0000000000466bfb in sync.(*WaitGroup).Wait at /usr/lib/golang/src/sync/waitgroup.go:130 2 breakpoint keep y 0x00000000004669c0 in sync.init.1 at /usr/lib/golang/src/sync/runtime.go:14 (gdb) (gdb) step sync.runtime_Semacquire (addr=0xc00007e014) at /usr/lib/golang/src/runtime/sema.go:55 55 func sync_runtime_Semacquire(addr *uint32) { (gdb) frame #0 sync.runtime_Semacquire (addr=0xc00007e014) at /usr/lib/golang/src/runtime/sema.go:55 55 func sync_runtime_Semacquire(addr *uint32) {
sync_runtime_Semacquire #
| |
这里的sema变量, 如果是等于0(它是无符号整形,不会为负数),就代表它没有获取到sema,需要等待, 如果sema变量是大于0,可以直接运行,不需要等待
func cansemacquire(addr *uint32) bool { for { v := atomic.Load(addr) if v == 0 { return false } if atomic.Cas(addr, v, v-1) { return true } } }我们知道sync.WaitGroup()函数, 一般是先Add(), 然后Wait()等待所有任务Done()[Add(-1)] sema开始值是0,按照我们前面说的,他无法获得sema,会进行休眠,同理如果有多个Wait(), 那么它们都会 休眠; 当Add(-1)后到达0后, 就是所有任务都已经完成,它会调用
runtime_Semrelease(semap, false, 0) // 进行V操作进行sema值加一, 然后唤醒一个goroutine, 当这个goroutine醒来[在一个loop里面], 发现sema不等于0了, 直接减一,然后跳出了semacquire1关于WaitGroup的分析, 参看我其他的文章.继续分析这个休眠和唤醒的;
gopark #
// src/runtime/proc.go
// Puts the current goroutine into a waiting state and unlocks the lock.
// The goroutine can be made runnable again by calling goready(gp).
func goparkunlock(lock *mutex, reason waitReason, traceEv byte, traceskip int) {
gopark(parkunlock_c, unsafe.Pointer(lock), reason, traceEv, traceskip)
}
// Puts the current goroutine into a waiting state and calls unlockf.
// If unlockf returns false, the goroutine is resumed.
// unlockf must not access this G's stack, as it may be moved between
// the call to gopark and the call to unlockf.
// Reason explains why the goroutine has been parked.
// It is displayed in stack traces and heap dumps.
// Reasons should be unique and descriptive.
// Do not re-use reasons, add new ones.
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
if reason != waitReasonSleep {
checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy
}
mp := acquirem() // 这里的作用是什么? ---------wait
gp := mp.curg // 得到当前的Goroutine
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waittraceev = traceEv
mp.waittraceskip = traceskip
releasem(mp) // ---------wait
// can't do anything that might move the G between Ms here.
mcall(park_m)
}
mcall就是切换到g0栈上去,gN的cpu寄存器等保存到g’sched,然后把gN作为实参给mcall的fn形参, 继续看park_m.
park_m #
// park continuation on g0.
func park_m(gp *g) {
_g_ := getg() // 得到g0
if trace.enabled {
traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip)
}
casgstatus(gp, _Grunning, _Gwaiting)
dropg()//解除gN与m的关系
if fn := _g_.m.waitunlockf; fn != nil {
ok := fn(gp, _g_.m.waitlock) //解除lock
_g_.m.waitunlockf = nil
_g_.m.waitlock = nil
if !ok {
if trace.enabled {
traceGoUnpark(gp, 2)
}
casgstatus(gp, _Gwaiting, _Grunnable)
execute(gp, true) // Schedule it back, never returns.
}
}
schedule() //重新进入调度
}
dropg函数,参见<前置知识.类汇编>
进入睡眠的步骤:
goparkunlock --> gopark --> mcall(park_m) --> schedule.
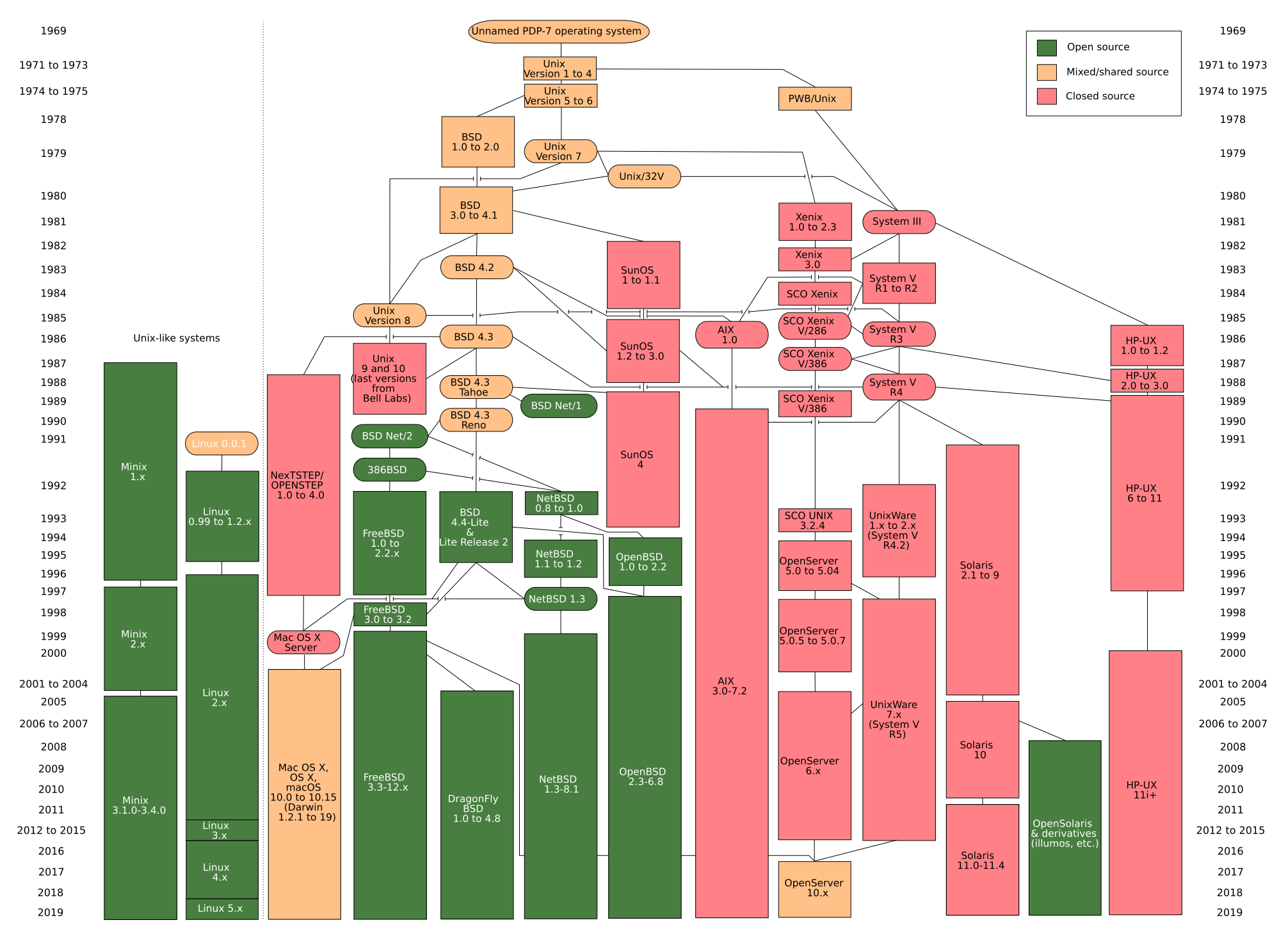
唤醒睡眠中的goroutine #
唤醒的总体流程如下图:
func (wg *WaitGroup) Add(delta int) {
statep, semap := wg.state()
if race.Enabled {
_ = *statep // trigger nil deref early
if delta < 0 {
// Synchronize decrements with Wait.
race.ReleaseMerge(unsafe.Pointer(wg))
}
race.Disable()
defer race.Enable()
}
state := atomic.AddUint64(statep, uint64(delta)<<32)
v := int32(state >> 32)
w := uint32(state)
if race.Enabled && delta > 0 && v == int32(delta) {
// The first increment must be synchronized with Wait.
// Need to model this as a read, because there can be
// several concurrent wg.counter transitions from 0.
race.Read(unsafe.Pointer(semap))
}
if v < 0 {
panic("sync: negative WaitGroup counter")
}
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
if v > 0 || w == 0 {
return
}
// This goroutine has set counter to 0 when waiters > 0.
// Now there can't be concurrent mutations of state:
// - Adds must not happen concurrently with Wait,
// - Wait does not increment waiters if it sees counter == 0.
// Still do a cheap sanity check to detect WaitGroup misuse.
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// Reset waiters count to 0.
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0) // 进行V操作 --------------------------------here
}
}
runtime_Semrelease #
src/sync/runtime.go
| |
readyWithTime #
func readyWithTime(s *sudog, traceskip int) {
if s.releasetime != 0 {
s.releasetime = cputicks()
}
goready(s.g, traceskip)
}
goready #
前面都很好理解, 这里有两个函数, 一个是systemstack, 一个是ready函数
func goready(gp *g, traceskip int) {
systemstack(func() {
ready(gp, traceskip, true)
})
}
// Mark gp ready to run.
func ready(gp *g, traceskip int, next bool) {
if trace.enabled { //忽略
traceGoUnpark(gp, traceskip)
}
status := readgstatus(gp) // return atomic.Load(&gp.atomicstatus)读atomicstatus的状态
// Mark runnable.
_g_ := getg()
mp := acquirem() // disable preemption because it can be holding p in a local var
if status&^_Gscan != _Gwaiting {
dumpgstatus(gp)
throw("bad g->status in ready")
}
// status is Gwaiting or Gscanwaiting, make Grunnable and put on runq
casgstatus(gp, _Gwaiting, _Grunnable) // 修改状态到_Grunnable
runqput(_g_.m.p.ptr(), gp, next) // 放入全局或本地队列,等待调度
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 {
// 有空闲的P,并且没有正在自旋状态的M(偷取其他线程的goroutine);
// 那么需要唤醒P.万一就把上面的待运行的goroutine调度起来了呢?
wakep()
}
releasem(mp)
}
sync_runtime_Semrelease ---> semrelease1 ---> readyWithTime ---> goready --systemstack-> ready
ready---> runqput -------------> releasem
\-->wakep-/
runqput #
其中runqput是,当从s, t0 := root.dequeue(addr)得到睡眠中的Goroutine,修改状态为_Grunnable,然后放入本地或全局队列
runqput的具体实现可以参见: runqput
wakep #
| |
如果有空闲的P,并且没有正在自旋状态的M(换言之所有的M都在工作?,换言之M都是运行/睡眠状态),这种状态成立,那么就会进行执行wakep函数
- 什么时候P变成了空闲了: P空闲状态
- 什么时候M变成了自旋状态了: M自旋转
- 为什么要满足这两个状态才进行唤醒:
- 1> 有空闲的P才能进行唤醒,如果都没空闲的了,唤醒也没用
- 2> 自旋状态的M是一直在伺机偷其他P队列g的,如果有自旋状态的M那么就不需要再专门唤醒
- 不唤醒可以?: 去掉这个唤醒逻辑,正常来说此goroutine还是有几率被快速执行,只是对整个系统来说,只要P空闲,
M睡眠了,就没有逻辑唤醒它们
分析wakep #
wakep主要是唤醒一个空闲P,获得/创建一个M,开始轮询调度,为了把上面已唤醒的G调度起来
// Tries to add one more P to execute G's.
// Called when a G is made runnable (newproc, ready).
func wakep() {
// be conservative about spinning threads
if !atomic.Cas(&sched.nmspinning, 0, 1) {
return
}
startm(nil, true)
}
- 一个P只能找到M,从空闲的M中找? 然后通过m.g0找到.
- 生成新的M,此时,创造新的线程,因为M与线程是一一对应的,同时它也会创造一个g0.
这里重新再判断一下是否有自旋的M,如果还是没有就设置自旋M的数量为1,后面(觉得还是为了避免wakep被其他线程再次进入执行,后面会让新建/唤醒的M的状态设置为自旋)startm函数准备创建/唤醒一个M
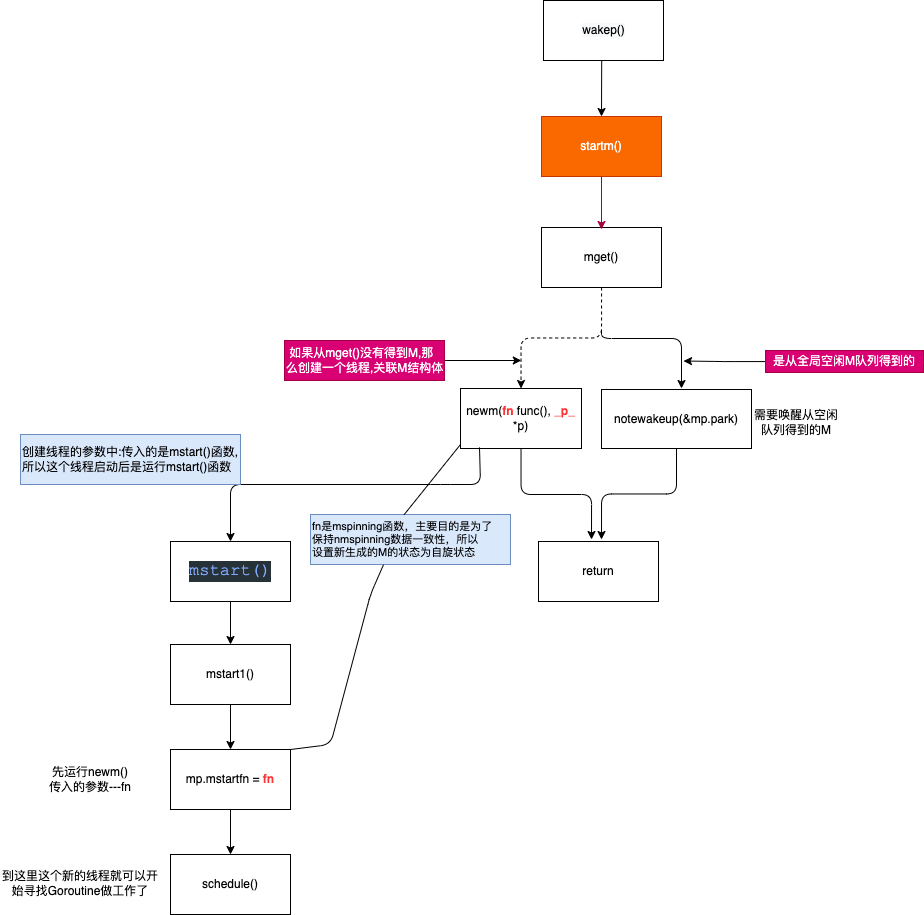
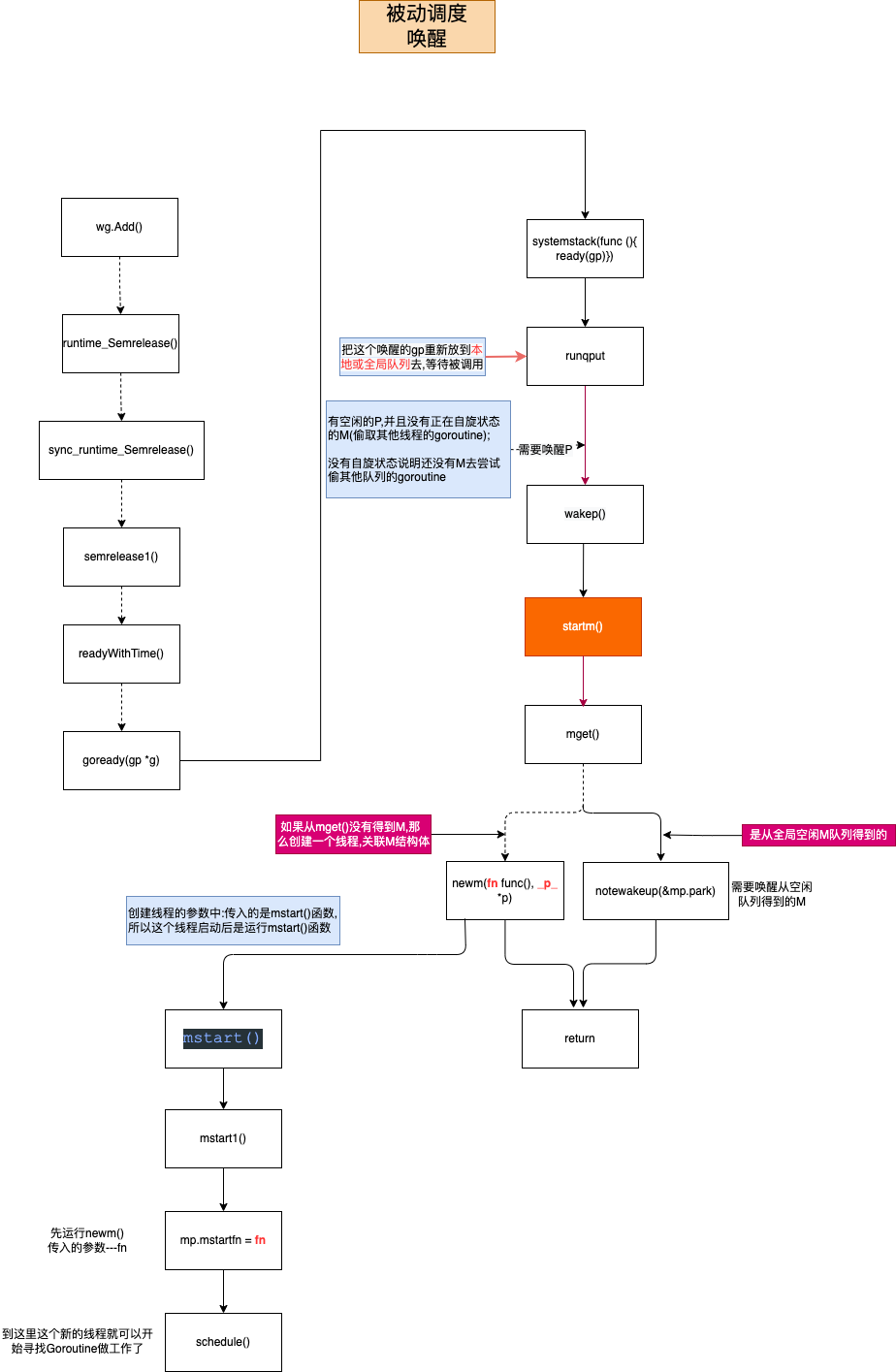
startm #
继续看下startm:可以发现主要是尝试用mget函数从全局空闲M队列获取一个M,如果失败则调用newm函数准备创建一个M,否则就用notewakeup去唤醒刚获取的M,这里有一点为了保证nmspinning数据一致性,需把新建/唤醒的M的状态设置为自旋
func startm(_p_ *p, spinning bool) {
lock(&sched.lock)
if _p_ == nil {
_p_ = pidleget()
if _p_ == nil {
unlock(&sched.lock)
if spinning {
// The caller incremented nmspinning, but there are no idle Ps,
// so it's okay to just undo the increment and give up.
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("startm: negative nmspinning")
}
}
return
}
}
mp := mget()
unlock(&sched.lock) // 全局空闲M队列
if mp == nil { //从全局的空闲队列没找到M
var fn func()
if spinning {
// The caller incremented nmspinning, so set m.spinning in the new M.
fn = mspinning
}
newm(fn, _p_) //新创建一个M,其中里面也有新g0.
return // 这里如果是新创建的线程,那么直接返回,不需要继续下面的唤醒notewakeup(&mp.park)
}
if mp.spinning {
throw("startm: m is spinning")
}
if mp.nextp != 0 {
throw("startm: m has p")
}
if spinning && !runqempty(_p_) { // _p_它的可运行G队列应该为空 >一种情况是它是从空闲P队列获得的(pidleget()函数)
throw("startm: p has runnable gs")
}
// The caller incremented nmspinning, so set m.spinning in the new M.
// 因为startm的调用者已经把自旋M数量+1,所以这里为了数据一致,必须把这个M设置为自旋状态
mp.spinning = spinning
mp.nextp.set(_p_)
notewakeup(&mp.park) // 到这一步,那么M是从全局空闲M队列获得的Ms,那么需要唤醒.
}mget从全局空闲M队列获取m #
这个全局的空闲M队列,从下面的函数取出,它就是一个链表,通过schedlink指针来串联所有空闲的M.
//尝试从全局的(sched.midle列表中得到一个m)
// Try to get an m from midle list.
// Sched must be locked.
// May run during STW, so write barriers are not allowed.
//go:nowritebarrierrec
func mget() *m {
mp := sched.midle.ptr()
if mp != nil {
sched.midle = mp.schedlink
sched.nmidle--
}
return mp
}
type schedt struct {
//...
midle muintptr // idle m's waiting for work
nmidle int32 // number of idle m's waiting for work
//...
}
// muintptr类型
type muintptr uintptr
//go:nosplit
func (mp muintptr) ptr() *m { return (*m)(unsafe.Pointer(mp)) }
//go:nosplit
func (mp *muintptr) set(m *m) { *mp = muintptr(unsafe.Pointer(m)) }
下面我们回到前面来看另一种情况:直接创建新M
newm创建新的线程与m #
新创建一个M,其中里面也有新g0
func newm(fn func(), _p_ *p) {
//分配一个与任何线程无关的M结构体mp,
// mp.g0=Gorooutine(也是从这里面分配出来的)
mp := allocm(_p_, fn)
mp.nextp.set(_p_) //把M关联上P
mp.sigmask = initSigmask //初始化信号
if gp := getg(); gp != nil && gp.m != nil && (gp.m.lockedExt != 0 || gp.m.incgo) && GOOS != "plan9" {
// We're on a locked M or a thread that may have been
// started by C. The kernel state of this thread may
// be strange (the user may have locked it for that
// purpose). We don't want to clone that into another
// thread. Instead, ask a known-good thread to create
// the thread for us.
//
// This is disabled on Plan 9. See golang.org/issue/22227.
//
// TODO: This may be unnecessary on Windows, which
// doesn't model thread creation off fork.
lock(&newmHandoff.lock)
if newmHandoff.haveTemplateThread == 0 {
throw("on a locked thread with no template thread")
}
mp.schedlink = newmHandoff.newm
newmHandoff.newm.set(mp)
if newmHandoff.waiting {
newmHandoff.waiting = false
notewakeup(&newmHandoff.wake)
}
unlock(&newmHandoff.lock)
return
}
newm1(mp)
}
- newm函数主要是两件事:
- 创建M结构体,G结构体(用于前面m.g0)在stack上开辟空间给g0.stack.
- allocm()
- 创建一个真正的线程,与上面的M结构相关联.
- newm1()方式,
- 直接从当前线程clone出一个新的线程.
- newmHandoff方式 [TODO zxc:可以新开一章来讲解]
- 给一个一直在for循环的创建线程,然后休眠的函数来创建线程,关联上面的M结构体
- newm1()方式,
- 创建M结构体,G结构体(用于前面m.g0)在stack上开辟空间给g0.stack.
allocm函数 #
- 因为函数需要new小对象,需要用到P.mcache,需要判断当前的M是否关联着P,如果没有就要向参数借,但是为什么没有判断如果参数_P_是nil的情况?
- 释放不需要等待的全局的M’s stack资源,这里是防止新生成线程又需要stack空间,所以先释放一些?
- new M, g0结构体,并且给g0分配stack空间.
// Allocate a new m unassociated with any thread. // Can use p for allocation context if needed. // fn is recorded as the new m's m.mstartfn. // // This function is allowed to have write barriers even if the caller // isn't because it borrows _p_. // //go:yeswritebarrierrec /* */ func allocm(_p_ *p, fn func()) *m { _g_ := getg() acquirem() // disable GC because it can be called from sysmon /* func acquirem() *m { _g_ := getg() _g_.m.locks++ return _g_.m } TODO zxc: 这里很奇怪的,只是把M结构体里面的locks字段++1; 后面的releasem又把这个locks--? func releasem(mp *m) { _g_ := getg() mp.locks-- if mp.locks == 0 && _g_.preempt { // restore the preemption request in case we've cleared it in newstack _g_.stackguard0 = stackPreempt } } */ if _g_.m.p == 0 { //如果当前m的P不存在,acquirep(_p_)关联_p_和当前的M;只是用于小对象的分配到堆上? TODO zxc: 这里P.mcahce,就是M.mcache acquirep(_p_) // temporarily borrow p for mallocs in this function } // Release the free M list. We need to do this somewhere and // this may free up a stack we can use. if sched.freem != nil { lock(&sched.lock) var newList *m for freem := sched.freem; freem != nil; { if freem.freeWait != 0 { // if == 0, 安全释放g0并删除m; 这里如果不等于0,就说明需要等待,还不能立即释放,所以这个if里面就好像链表反转算法,转移到新链表. next := freem.freelink freem.freelink = newList //freem.freelink = newList(nil); so, freem.freelink == nil newList = freem // newList.freelink == nil; freem == newList freem = next // continue } stackfree(freem.g0.stack) // 说明freem.freeWait==0;可以立即g0 stack释放 freem = freem.freelink // freem等于它的next指针 } sched.freem = newList //这里就把不能释放的重新放入全局释放列表 unlock(&sched.lock) } mp := new(m) // new一个M结构体 mp.mstartfn = fn mcommoninit(mp) // In case of cgo or Solaris or illumos or Darwin, pthread_create will make us a stack. // Windows and Plan 9 will layout sched stack on OS stack. if iscgo || GOOS == "solaris" || GOOS == "illumos" || GOOS == "windows" || GOOS == "plan9" || GOOS == "darwin" { mp.g0 = malg(-1) } else { mp.g0 = malg(8192 * sys.StackGuardMultiplier) //约等于1024*8=8192 ==> 8k } mp.g0.m = mp if _p_ == _g_.m.p.ptr() { //如果是借P来进行malloc,那么需要恢复原样. releasep() } releasem(_g_.m) // TODO zxc: locks ? return mp }为什么需要locks–?
newm1 #
newm1先关闭信号,防止clone时候被打断.
func newm1(mp *m) { if iscgo { // 暂时忽略. //... } execLock.rlock() // Prevent process clone. newosproc(mp) //准备去clone. execLock.runlock() } func newosproc(mp *m) { stk := unsafe.Pointer(mp.g0.stack.hi) /* * note: strace gets confused if we use CLONE_PTRACE here. */ if false { print("newosproc stk=", stk, " m=", mp, " g=", mp.g0, " clone=", funcPC(clone), " id=", mp.id, " ostk=", &mp, "\n") } // Disable signals during clone, so that the new thread starts // with signals disabled. It will enable them in minit. // 在clone,关闭信号,所以创建出来的thread信号都是关闭的,minit函数再打开. var oset sigset sigprocmask(_SIG_SETMASK, &sigset_all, &oset) ret := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(funcPC(mstart))) sigprocmask(_SIG_SETMASK, &oset, nil) if ret < 0 { print("runtime: failed to create new OS thread (have ", mcount(), " already; errno=", -ret, ")\n") if ret == -_EAGAIN { println("runtime: may need to increase max user processes (ulimit -u)") } throw("newosproc") } }clone函数最后一个实参是我们熟悉的mstart函数,clone后的子线程将会执行它,而父线程将直接返回
这个clone函数位于
src/runtime/sys_linux_amd64.s// int32 clone(int32 flags, void *stk, M *mp, G *gp, void (*fn)(void)); TEXT runtime·clone(SB),NOSPLIT,$0 // Linux系统调用约定,这四个参数需要分别放入rdi, rsi,rdx和r10寄存器中 MOVL flags+0(FP), DI MOVQ stk+8(FP), SI MOVQ $0, DX MOVQ $0, R10 // Copy mp, gp, fn off parent stack for use by child. // Careful: Linux system call clobbers CX and R11. // Linux系统调用会污染CX和R11; 所以我们参数不放在那里面 MOVQ mp+16(FP), R8 MOVQ gp+24(FP), R9 MOVQ fn+32(FP), R12 MOVL $SYS_clone, AX // 系统调用了; 返回值放入AX寄存器里面. SYSCALL // In parent, return. CMPQ AX, $0 // 如果返回值是0,证明是子进程返回 JEQ 3(PC) MOVL AX, ret+40(FP) // 父进程返回,返回到父进程的AX不等于0 RET // In child, on new stack. MOVQ SI, SP // sp = stk+8(FP); 就是设置子线程的栈顶; // If g or m are nil, skip Go-related setup. CMPQ R8, $0 // m JEQ nog CMPQ R9, $0 // g JEQ nog // Initialize m->procid to Linux tid MOVL $SYS_gettid, AX SYSCALL MOVQ AX, m_procid(R8) // 设置m.proc_id = sys_gettid() // Set FS to point at m->tls. LEAQ m_tls(R8), DI // 不取引用,所以是DI=&m.tls[0];把m.tls[0]地址给DI寄存器. CALL runtime·settls(SB) // FS寄存器里的值:就是m.tls[0]的地址. // In child, set up new stack get_tls(CX) // CX = &m.tls[0] MOVQ R8, g_m(R9) MOVQ R9, g(CX) // gp+24(FP) == R9; g(CX)---> *CX; m.tls[0]=g0; CALL runtime·stackcheck(SB) nog: // Call fn CALL R12 // It shouldn't return. If it does, exit that thread. MOVL $111, DI MOVL $SYS_exit, AX SYSCALL JMP -3(PC) // keep exiting
// list /tmp/kubernets/clone_test/main.go:1 // list /usr/lib/golang/src/runtime/sys_linux_amd64.s:540 // gdb调试自定义函数 // define zxc // info threads // info register rbp rsp pc // end [New LWP 32548] [Switching to LWP 32548] Breakpoint 3, runtime.clone () at /usr/lib/golang/src/runtime/sys_linux_amd64.s:562 //这一行的确是没必要,clone完后,系统会把子线程的sp寄存器设置为传入参数stk(m.stack.hi) 562 MOVQ SI, SP (gdb) zxc Id Target Id Frame * 2 LWP 32548 "test" runtime.clone () at /usr/lib/golang/src/runtime/sys_linux_amd64.s:562 1 LWP 32547 "test" runtime.clone () at /usr/lib/golang/src/runtime/sys_linux_amd64.s:556 rbp 0x7fffffffe3b0 0x7fffffffe3b0 rsp 0xc000044000 0xc000044000 pc 0x455568 0x455568 <runtime.clone+56> (gdb) info register sp sp 0xc000044000 0xc000044000 (gdb) step 565 CMPQ R8, $0 // m (gdb) info register sp sp 0xc000044000 0xc000044000
notewakeup唤醒m #
notewakeup在不同操作系统有不同的实现,一种是用futex,一种是用
// src/runtime/lock_futex.go
//go:build dragonfly || freebsd || linux
func notewakeup(n *note) {
old := atomic.Xchg(key32(&n.key), 1)
if old != 0 {
print("notewakeup - double wakeup (", old, ")\n")
throw("notewakeup - double wakeup")
}
futexwakeup(key32(&n.key), 1)
}
// If any procs are sleeping on addr, wake up at most cnt.
//go:nosplit
func futexwakeup(addr *uint32, cnt uint32) {
ret := futex(unsafe.Pointer(addr), _FUTEX_WAKE_PRIVATE, cnt, nil, nil, 0)
if ret >= 0 {
return
}
// I don't know that futex wakeup can return
// EAGAIN or EINTR, but if it does, it would be
// safe to loop and call futex again.
systemstack(func() {
print("futexwakeup addr=", addr, " returned ", ret, "\n")
})
*(*int32)(unsafe.Pointer(uintptr(0x1006))) = 0x1006
}
// src/runtime/lock_sema.go
//go:build aix || darwin || netbsd || openbsd || plan9 || solaris || windows
func notewakeup(n *note) {
var v uintptr
for {
v = atomic.Loaduintptr(&n.key)
if atomic.Casuintptr(&n.key, v, locked) {
break
}
}
// Successfully set waitm to locked.
// What was it before?
switch {
case v == 0: // 我们从上面知道 v 等于 note.key; note.key为M结构体的指针; 如果是0,那么这个note是无效的,不需要唤醒.
// Nothing was waiting. Done.
case v == locked:
// Two notewakeups! Not allowed.
throw("notewakeup - double wakeup") // 不能调用这个函数两次, locked的值是1,唤醒一次,这个note.key就变成1了,下次再调用就报错.
default:
// Must be the waiting m. Wake it up.
semawakeup((*m)(unsafe.Pointer(v))) //从这个semawakeup(mp *m)需要的参数,可以知道note.key字段是一个M的指针.
}
}
附录 #
所以这里必须为子线程指定其使用的栈,否则父子线程会共享同一个栈从而造成混乱,从上面的newosproc函数可以看出,新线程使用的栈为m.g0.stack.lo~m.g0.stack.hi这段内存,而这段内存是newm函数在创建m结构体对象时从进程的堆上分配而来的。
- TODO
- 删除的时候可以连着删除

1000000个数,白天只查,晚上更新
一个无序的数组长度为1001 ,数组内的元素值在[1,1000]间,只用基本数据结构找出1001中唯一重复的元素 — (不能用map)
将IPv4(192.168.1.1)转换成longl诶行
一个程序 接收1亿个数 最后返回前100个最大的数