https://blog.tianfeiyu.com/source-code-reading-notes/go/golang_gpm.html
g结构 #
type g struct {
// 栈相关的两个字段
stack stack
stackguard0 uintptr
stackguard1 uintptr // offset known to liblink
// defer 和 panic
_panic *_panic // 最内侧的 panic 结构体
_defer *_defer // 最内侧的延迟函数结构体
//
m *m
sched gobuf
atomicstatus uint32
goid int64
// 抢占
preempt bool // 抢占信号
preemptStop bool // 抢占时将状态修改成 `_Gpreempted`
preemptShrink bool // 在同步安全点收缩栈
}
type gobuf struct {
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret sys.Uintreg
lr uintptr
bp uintptr // for GOEXPERIMENT=framepointer ------------------------here
}
m结构 #
type m struct {
g0 *g // goroutine with scheduling stack
morebuf gobuf // gobuf arg to morestack
divmod uint32 // div/mod denominator for arm - known to liblink
// Fields not known to debuggers.
procid uint64 // for debuggers, but offset not hard-coded
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
sigmask sigset // storage for saved signal mask
tls [6]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
curg *g // current running goroutine
//...
}
M的创建与销毁 #
M 是 runtime 中的一个对象,代表线程,每创建一个 M 对象同时会创建一个线程与 M 进行绑定,线程的新建是通过执行 clone() 系统调用创建出来的。runtime 中定义 M 的最大数量为 10000 个,用户可以通过debug.SetMaxThreads(n) 进行调整。
在以下两种场景下会新建 M:
- 初始化时创建主线程,主线程是第一个M命名为m0
- 当有新的G创建或者有G从_Gwaiting进入_Grunning,ready函数根据。。。, 判断是否需要调用wakep函数,且还有空闲的P,此时会调用 startm(),首先从全局队列( sched.midle)获取一个 M 和空闲的 P 绑定执行 G,如果没有空闲的 M 则会通过newm() 创建 M
m0是定义的全局变量不需要在堆上分配内存,其他M都是通过new函数创建的对象,其m结构体存放在堆上.
M不会被销毁,当找不到要运行的G或者绑定不到空闲的P时会通过执行stopm()函数进入到睡眠状态:
M的状态 #
M有三种状态:自旋spinning,睡眠sleep,运行runing
M进入到自旋/睡眠状态:
- 当M没法获得可运行的G(全局G队列/绑定的P无可运行的G/不能从其他P窃取可运行的G)时M会尝试先进入自旋状态(spinning),因处于自旋状态的M数量最多为非空闲状态的P数量的一半(
sched.nmspinning < (procs- sched.npidle)/2,procs为初始化时候设置的P个数,sched.npidle为空闲的P个数),所以未进入到自旋状态则会直接进入到睡眠转态, 而自旋状态的M会继续从其他P窃取可执行的G,如果M在自旋状态未窃取到G,还是会进入到睡眠转态 - 当M关联的G进入系统调用时,M会主动和关联的P解绑,当M关联的G执行
exitsyscall()函数退出系统调用时,M会找一个空闲的P进行绑定,如果找不到,M会调用stopm()进入到睡眠状态
在stopm()函数中会将睡眠的M放到全局空闲队列(sched.midle)中.
全局G队列 #
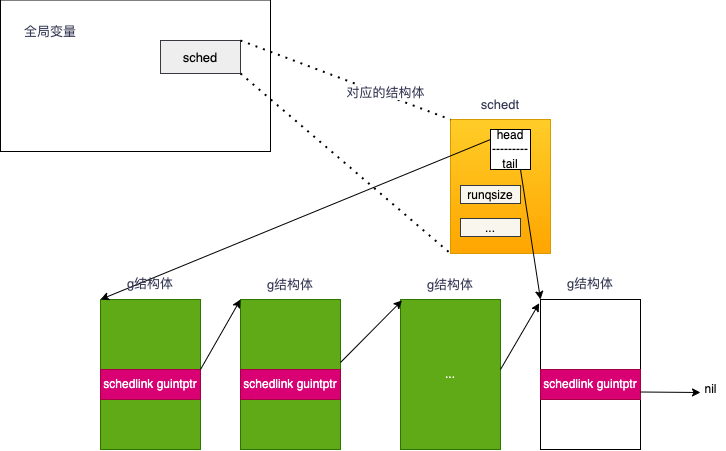
全局运行队列(Global runnable queue),指队列里面的Goroutine的状态都是_Grunnable,可以运行,随时可运行,只要能被调度起来,调度起来就变成了运行中_Grunning.
var (
allglen uintptr
allm *m
allp []*p // len(allp) == gomaxprocs; may change at safe points, otherwise immutable
allpLock mutex // Protects P-less reads of allp and all writes
gomaxprocs int32
ncpu int32
sched schedt
//...
)
type schedt struct {
//...
// Global runnable queue. 全局运行队列
runq gQueue
runqsize int32
//...
}
// A gQueue is a dequeue of Gs linked through g.schedlink. A G can only
// be on one gQueue or gList at a time.
type gQueue struct {
head guintptr
tail guintptr
}
全局可运行队列结构知道了,那么他们是怎么关联的?有头有尾是链表类型.
全局可运行队列关联结构 #
通过globrunqput函数
// Put gp on the global runnable queue.
// Sched must be locked.
// May run during STW, so write barriers are not allowed.
//go:nowritebarrierrec
func globrunqput(gp *g) {
sched.runq.pushBack(gp)
sched.runqsize++
}
// pushBack adds gp to the tail of q.
func (q *gQueue) pushBack(gp *g) {
gp.schedlink = 0
if q.tail != 0 {
q.tail.ptr().schedlink.set(gp)
} else {
q.head.set(gp)
}
q.tail.set(gp)
}
p结构 #
type p struct{
//...
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
runnext guintptr
//...
}
TODO zxc
为什么需要P?
p的创建与销毁 #
程序初始化时优先设置为环境变量GOMAXPROCS,如环境变量不存在就设置为系统CPU核数,后续也可在用户代码调用runtime.GOMAXPROCS()来修改.
在 IO 密集型场景下,可以适当调高 P 的数量,因为 M 需要与 P 绑定才能运行,而 M 在执行 G 时某些操作会陷入系统调用,此时与 M 关联的 P 处于等待状态,如果系统调用一直不返回那么等待系统调用这段时间的 CPU 资源其实是被浪费的,虽然 runtime 中有 sysmon 监控线程可以抢占 G,此处就是抢占与 G 关联的 P,让 P 重新绑定一个 M 运行 G,但 sysmon 是周期性执行抢占的,在 sysmon 稳定运行后每隔 10ms 检查一次是否要抢占 P,操作系统中在 10ms 内可以执行多次线程切换,如果 P 处于系统调用状态还有需要运行的 G,这部分 G 得不到执行其实CPU资源是被浪费的。在一些项目中能看到有修改 P 数量的操作,开源数据库项目https://github.com/dgraph-io/dgraph 中将 GOMAXPROCS 调整到 128 来增加 IO 处理能力。
程序运行过程中如果没有调整 GOMAXPROC,未使用的 P 会放在调度器的全局队列 schedt.pidle ,不会被销毁。若调小了 GOMAXPROC,通过 p.destroy() 会将多余的 P 关联的资源回收掉并且会将 P 状态设置为 _Pdead,此时可能还有与 P 关联的 M 所以 P 对象不会被回收。
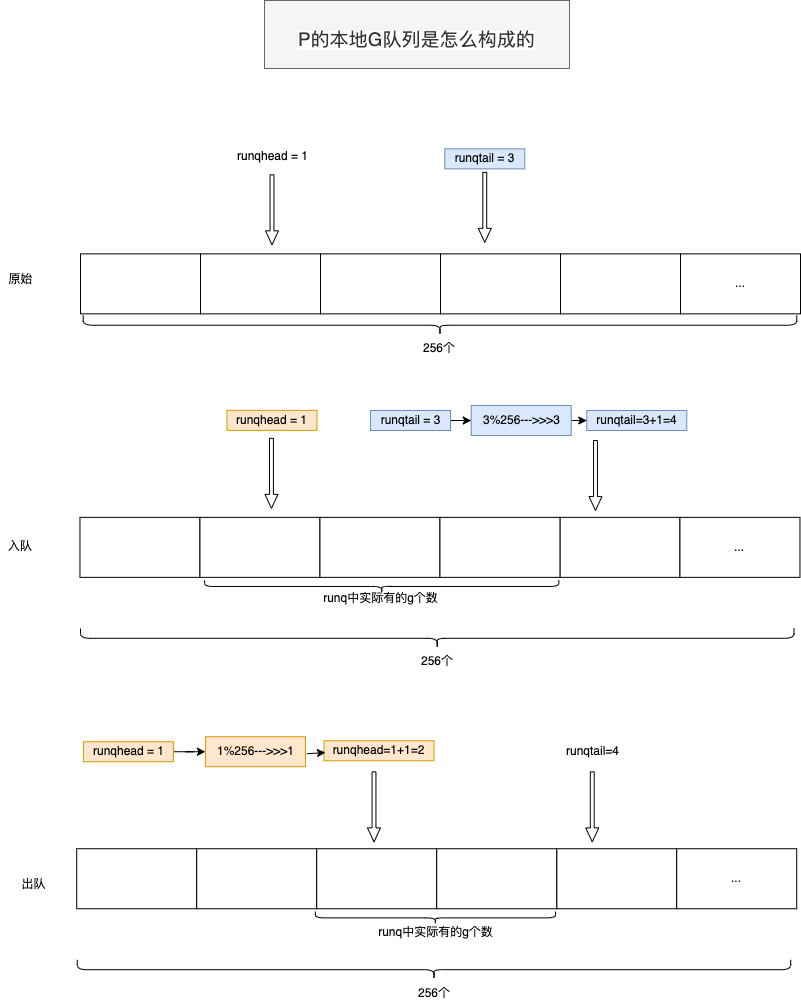
P的本地G队列 #
- 本地运行队列其实分为两个部分:
- 一部分是由P的
runq、runqhead和runqtail这三个成员组成的一个无锁循环队列,该队列最多可包含256个Goroutine; - 另一部分是P的
runnext成员,它是一个指向g结构体对象的指针,它最多只包含一个Goroutine.
- 一部分是由P的
type p struct{
//...
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
runnext guintptr
//...
}
本地可运行队列关联结构 #
通过这两个函数:runqget与runqput,来看下它们是怎么运作的,我们先列出入队和出队的代码,来看一下。
/*
----------------here: 这里是入队,把Goroutine放入本地运行队列
*/
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
t := _p_.runqtail
if t-h < uint32(len(_p_.runq)) {
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumption,runqhead不动,runqtail加一.
return
}
//----------------------------------------------------------------------------------------------------------
for {
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumers
t := _p_.runqtail
if t == h { // 如果头等于尾,证明是队列是空的
return nil, false
}
gp := _p_.runq[h%uint32(len(_p_.runq))].ptr()
if atomic.CasRel(&_p_.runqhead, h, h+1) { // cas-release, commits consume,runqhead加一,runqtail不动.
return gp, false
}
}
- 入队
- runqhead不动,runqtail加一
- 出队
- runqhead加一,runqtail不动.