1.系统监控 #
这个是main goroutine执行的主函数,此函数之后会调用用户定义main函数,我们在初始化一章已经提过main goroutine执行的主函数
它的里面可以看到调用了newm函数生成新M,且新M将执行sysmon函数
func main() {
//...
if GOARCH != "wasm" { // no threads on wasm yet, so no sysmon
systemstack(func() {
newm(sysmon, nil)
})
}
//...
}
sysmon #
可以看到sysmon里面是一个for循环,它会一直运行,因为这个M没有关联P,所以不允许写屏障 逻辑比较简单,延时睡眠,调用retake
// Always runs without a P, so write barriers are not allowed.
//
//go:nowritebarrierrec
func sysmon() {
lock(&sched.lock)
sched.nmsys++ //增加记录系统线程的值的个数
checkdead()
unlock(&sched.lock)
lasttrace := int64(0)
idle := 0 // how many cycles in succession we had not wokeup somebody
delay := uint32(0)
for {
if idle == 0 { // start with 20us sleep...
delay = 20
} else if idle > 50 { // start doubling the sleep after 1ms...
delay *= 2
}
if delay > 10*1000 { // up to 10ms
delay = 10 * 1000
}
usleep(delay)
//...
// retake P's blocked in syscalls
// and preempt long running G's
// 抢占被系统调用阻塞的P和抢占长期运行的G
if retake(now) != 0 {
idle = 0
} else {
idle++
}
//...
}
}
retake #
retake是怎么区分是否是本次调度一直在运行?
- 通过p结构体里面的sysmontick,快照p结构体中schedtick,所以下次再比较两者,参见下面的16-31行
type sysmontick struct {
schedtick uint32
schedwhen int64
syscalltick uint32
syscallwhen int64
}
retake怎么判断是否应该抢断?
- 只有P是
_Prunning/_Psyscall状态,才会进行抢占 - 一种是用户代码运行太久会被抢占(参见下方的25行):如果
pd.schedwhen ~ now这个时间段大于阀值forcePreemptNS,就会调用preemptone函数做抢断准备 - 一种是进入了系统调用的抢占:主要思想是如果P接下来没有其他工作可做(本地G队列为空了),这时候抢占它没有意义,但为了防止sysmon线程深度睡眠(上文有分析retake的返回参数能决定sysmon的睡眠时长)
retake函数判断不进行系统剥夺抢占逻辑,由第50行代码决定: runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now
- _p_的本地运行队列没有Gs; runqempty(p)返回true
- 有空闲的P,或者有正在自旋状态的M(正在偷其他P队列的Gs); atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0返回true
- 上次观测到的系统调用还没有超过10毫秒; pd.syscallwhen+1010001000 > now返回true
所以当程序没有工作需要做,且系统调用没有超过10ms就不进行系统调用抢占; 上式前两项说明这个程序没有工作需要做; 最后一项说明系统调用还没超过10ms
func retake(now int64) uint32 {
n := 0
// Prevent allp slice changes. This lock will be completely
// uncontended unless we're already stopping the world.
lock(&allpLock)
// We can't use a range loop over allp because we may
// temporarily drop the allpLock. Hence, we need to re-fetch
// allp each time around the loop.
for i := 0; i < len(allp); i++ { //遍历所有的P
_p_ := allp[i]
if _p_ == nil {
// This can happen if procresize has grown
// allp but not yet created new Ps.
continue
}
pd := &_p_.sysmontick // 最后一次被sysmon观察到的tick
s := _p_.status
sysretake := false
if s == _Prunning || s == _Psyscall { //只有当p处于 _Prunning 或 _Psyscall 状态时才会进行抢占
// Preempt G if it's running for too long.
t := int64(_p_.schedtick) // _p_.schedtick:每发生一次调度,调度器对该值加一
if int64(pd.schedtick) != t { // 监控线程监控到一次新的调度,所以重置跟sysmon相关的schedtick和schedwhen变量
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now { // 1. 没有进第一个if语句内,说明:pd.schedtick == t; 说明(pd.schedwhen ~ now)这段时间未发生过调度;
preemptone(_p_) // 2. 但是这个_P_上面的某个Goroutine被执行,一直在执行这个Goroutiine; 中间没有切换其他Goroutine,因为如果切会导致_P_.schedtick增长,导致进入第一个if语句内;
// In case of syscall, preemptone() doesn't // 3. 连续运行超过10毫秒了,设置抢占请求.
// work, because there is no M wired to P.
sysretake = true // 需要系统抢占
}
}
if s == _Psyscall { // P处于系统调用之中,需要检查是否需要抢占
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
t := int64(_p_.syscalltick) // 用于记录系统调用的次数,主要由工作线程在完成系统调用之后加一
if !sysretake && int64(pd.syscalltick) != t { // 不相等---说明已经不是上次观察到的系统调用,开始了一个新的系统调用,所以重置一下
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
// On the one hand we don't want to retake Ps if there is no other work to do,
// but on the other hand we want to retake them eventually
// because they can prevent the sysmon thread from deep sleep.
// 1. _p_的本地运行队列没有Gs; runqempty(_p_)返回true
// 2. 有空闲的P,或者有正在自旋状态的M(正在偷其他P队列的Gs); atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0返回true
// 3. 上次观测到的系统调用还没有超过10毫秒; pd.syscallwhen+10*1000*1000 > now返回true
// - concluing: 当程序没有工作需要做,且系统调用没有超过10ms就不进行系统调用抢占.
// - 1和2说明这个程序没有工作需要做;
// - 3说明系统调用还没超过10ms
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
// Drop allpLock so we can take sched.lock.
unlock(&allpLock)
// Need to decrement number of idle locked M's
// (pretending that one more is running) before the CAS.
// Otherwise the M from which we retake can exit the syscall,
// increment nmidle and report deadlock.
incidlelocked(-1)
if atomic.Cas(&_p_.status, s, _Pidle) { // 需要抢占,则通过使用cas修改p的状态来获取p的使用权
if trace.enabled { // CAS: 工作线程此时此刻可能正好从系统调用返回了,也正在获取p的使用权
traceGoSysBlock(_p_)
traceProcStop(_p_)
}
n++
_p_.syscalltick++
handoffp(_p_) // 寻找一个新的m出来接管P
}
incidlelocked(1)
lock(&allpLock)
}
}
unlock(&allpLock)
return uint32(n)
}
下面两章将分别说说两种不同的剥夺抢占。
- 用户执行过久: 第26行的preemptone函数
- 陷入系统调用: 第67行的handoffp函数
2.用户执行过久 #
preemptone设置抢占 #
继续上文看下preemptone函数,它设置了g.preempt(抢占标示)为true和g.stackguard0为很大的数((1<<(8*sys.PtrSize) - 1) & -1314 ---> 0xfffffffffffffade),使被抢占的goroutine在进行函数调用会去检查栈溢出,然后处理抢占请求
func preemptone(_p_ *p) bool {
mp := _p_.m.ptr()
if mp == nil || mp == getg().m {
return false
}
gp := mp.curg // gp == 被抢占的goroutine
if gp == nil || gp == mp.g0 {
return false
}
gp.preempt = true // 设置抢占信号preempt == true
// (1<<(8*sys.PtrSize) - 1) & -1314 ---> 0xfffffffffffffade, 很大的数
gp.stackguard0 = stackPreempt //stackguard0==很大的数; 使被抢占的goroutine;在进行函数调用会去检查栈溢出;去处理抢占请求
return true
}
触发抢占 #
通过preemptone函数设置抢占后,我们继续来看实际触发抢占的,在前文我们讲述了编译器会在函数的头尾部分添加额外的汇编:编译器加的函数头的部分
设置抢占后,只要执行函数调用就会执行下列函数调用:
morestack_noctxt() -> morestack() -> newstack()
runtime·morestack #
首先来看下runtime·morestack函数:
- 类似于mcall
- 保存调用morestack函数的goroutine(假设为gN)到它的sched成员 -> 将当前工作线程的g0与线程TLS关联 -> 将当前工作线程的g0栈恢复到CPU寄存器
- 在g0栈中call调用传入的参数(mcall)/执行
runtime·newstack(SB)函数(morestack),所以不会影响gN,如果gN下一次被调度起来了,那么执行PC,又会重新到本函数头部执行,从上面分析也可以知道,这里的风险就是,如果执行过程没有调用其他函数,那么无法进行抢占,这个就是基于插入抢占,1.14基于信号抢占。
# morestack but not preserving ctxt.
TEXT runtime·morestack_noctxt(SB),NOSPLIT,$0
MOVL $0, DX
JMP runtime·morestack(SB)
#
# support for morestack
#
# Called during function prolog when more stack is needed.
#
# The traceback routines see morestack on a g0 as being
# the top of a stack (for example, morestack calling newstack
# calling the scheduler calling newm calling gc), so we must
# record an argument size. For that purpose, it has no arguments.
TEXT runtime·morestack(SB),NOSPLIT,$0-0
# 开始是进行一些判断
# Cannot grow scheduler stack (m->g0).
# ...
# Cannot grow signal stack (m->gsignal).
# ...
# 设置m->morebuf的PC,SP,g为相对应的'main'
# Called from f.
# Set m->morebuf to f's caller.
NOP SP # tell vet SP changed - stop checking offsets
MOVQ 8(SP), AX # f's caller's PC # 这里的路径比如我的: 'main'--->'sub_function'。
# 但是抢占了,所以走下面的路径:->morestack_noctxt()->morestack()->newstack()
# 所以这里的f在我这里应该是main.
# 需要注意morestack_noctxt与morestack使用的栈大小都是0,且他们的跳转没用call指令,使用的是JMP
MOVQ AX, (m_morebuf+gobuf_pc)(BX)
LEAQ 16(SP), AX # f's caller's SP
MOVQ AX, (m_morebuf+gobuf_sp)(BX)
get_tls(CX) #...
MOVQ g(CX), SI
MOVQ SI, (m_morebuf+gobuf_g)(BX)
# 保存当前的寄存器信息到g->sched中
# Set g->sched to context in f.
MOVQ 0(SP), AX # f's PC
MOVQ AX, (g_sched+gobuf_pc)(SI)
MOVQ SI, (g_sched+gobuf_g)(SI)
LEAQ 8(SP), AX # f's SP
MOVQ AX, (g_sched+gobuf_sp)(SI) #在morestack里面就已经保存了sp的值
MOVQ BP, (g_sched+gobuf_bp)(SI)
MOVQ DX, (g_sched+gobuf_ctxt)(SI)
# 把g0设置为m当前运行的G; 把g0->sched->sp恢复到SP寄存器中;
#Call newstack on m->g0's stack.
MOVQ m_g0(BX), BX
MOVQ BX, g(CX)
MOVQ (g_sched+gobuf_sp)(BX), SP # 把g0的栈SP寄存器恢复到实际的寄存器中。所以下面就使用了g0的栈
# 调用newstack
CALL runtime·newstack(SB)
CALL runtime·abort(SB) #crash if newstack returns
RET
newstack(SB) #
看下高亮出来的代码,主要是判断是否是设置为了需抢占:
| |
gopreempt_m #
主要把被抢占的Goroutine重新放入全局队列:
// gopreempt_m(gp) ---> goschedImpl(gp)
func gopreempt_m(gp *g) {
if trace.enabled {
traceGoPreempt()
}
goschedImpl(gp)
}
goschedImpl我们之前讲过:goschedImpl
栈增长相关代码 #
func newstack() {
//...省略抢占的代码
// Allocate a bigger segment and move the stack.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2 // 新的栈大小直接*2
if newsize > maxstacksize {
print("runtime: goroutine stack exceeds ", maxstacksize, "-byte limit\n")
throw("stack overflow")
}
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack)
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize, true)
if stackDebug >= 1 {
print("stack grow done\n")
}
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)
}
func copystack(gp *g, newsize uintptr, sync bool) {
//...
// allocate new stack
new := stackalloc(uint32(newsize))
//...
}
- stackalloc
// stackalloc allocates an n byte stack.
//
// stackalloc must run on the system stack because it uses per-P
// resources and must not split the stack.
//
//go:systemstack
func stackalloc(n uint32) stack {
// Small stacks are allocated with a fixed-size free-list allocator.
// If we need a stack of a bigger size, we fall back on allocating
// a dedicated span.
var v unsafe.Pointer
if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize {
//小堆栈用固定大小的自由列表分配器进行分配。
} else {
//...
if s == nil {
// 如果我们需要一个更大的堆栈,我们会重新分配一个span.
// Allocate a new stack from the heap.
s = mheap_.allocManual(npage, &memstats.stacks_inuse)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
//...
}
//...
}
3.陷入系统调用 #
handoffp #
handoffp函数:判断是否需要启动工作线程来接管_p_,如果不需要则把_p_放入P的全局空闲队列.
如果当前P的运行队列有任务/全局队列有任务,有gc任务,大概率整个系统有任务待做,或者当前P是最后一个P要用作轮询网络
其中大概率整个系统有任务待做: 由第24行
atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) == 0决定:如果没有P空闲,而且这些没空闲的P连接的M不是处在自旋状态(没有自旋的M),证明其他P都在工作(而不是假装工作实际是在伺机从其他队列偷任务那种),是不是说明整个系统除了当前P外都在做事,所以大概率某些P的运行队列上有任务积压,所以我们应该启动M,让它跟当前P连接,去别的P中偷任务)
| |
其中startm函数我们前面介绍过:startm:
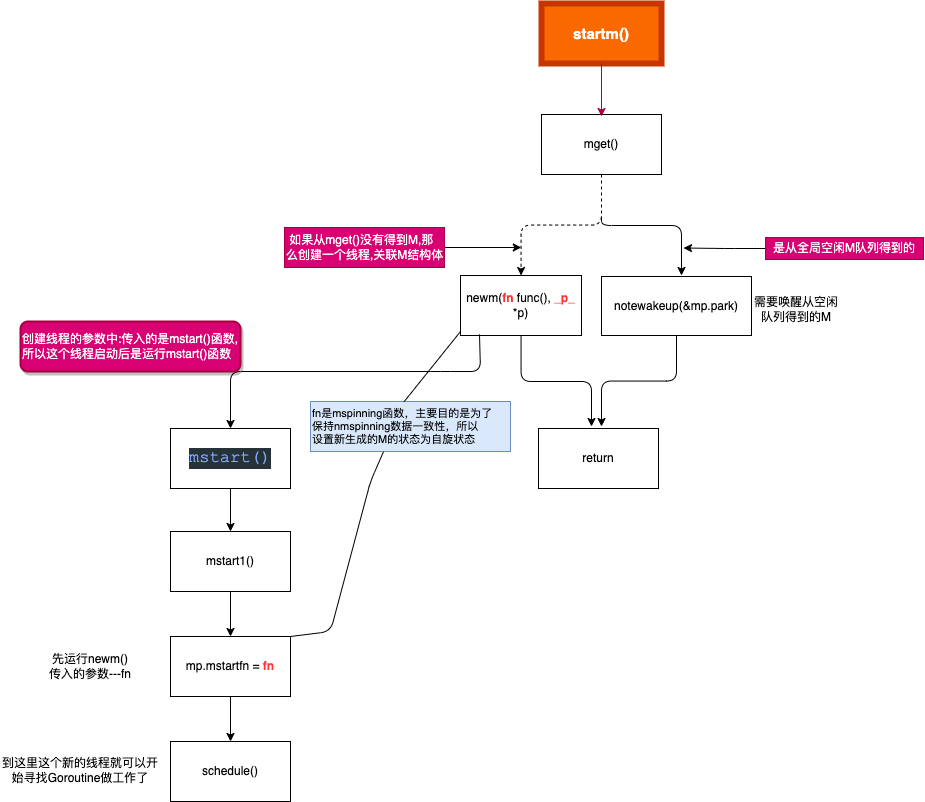
系统调用收尾,如从系统调用返回,如何重新得到P #
main.go
package main
import (
"fmt"
"os"
)
var path = "appss.txt"
func isError(err error) bool {
if err != nil {
fmt.Println(err.Error())
}
return (err != nil)
}
func main() {
var file, err = os.OpenFile(path, os.O_RDWR, 0644)
if isError(err) {
return
}
defer file.Close()
}
// go build -gcflags "-N -l" -o test .
// 准备mcall函数断点的文件gdb
// - list /usr/lib/golang/src/syscall/zsyscall_linux_amd64.go:62
// - list /usr/lib/golang/src/syscall/asm_linux_amd64.s:44
// func Syscall6(trap, a1, a2, a3, a4, a5, a6 uintptr) (r1, r2, err uintptr)
TEXT ·Syscall6(SB),NOSPLIT,$0-80
CALL runtime·entersyscall(SB)
MOVQ a1+8(FP), DI
MOVQ a2+16(FP), SI
MOVQ a3+24(FP), DX
MOVQ a4+32(FP), R10
MOVQ a5+40(FP), R8
MOVQ a6+48(FP), R9
SYSCALL
CMPQ AX, $0xfffffffffffff001
JLS ok6
MOVQ $-1, r1+56(FP)
MOVQ $0, r2+64(FP)
NEGQ AX
MOVQ AX, err+72(FP)
CALL runtime·exitsyscall(SB)
RET
ok6:
MOVQ AX, r1+56(FP)
MOVQ DX, r2+64(FP)
MOVQ $0, err+72(FP)
CALL runtime·exitsyscall(SB)
RET
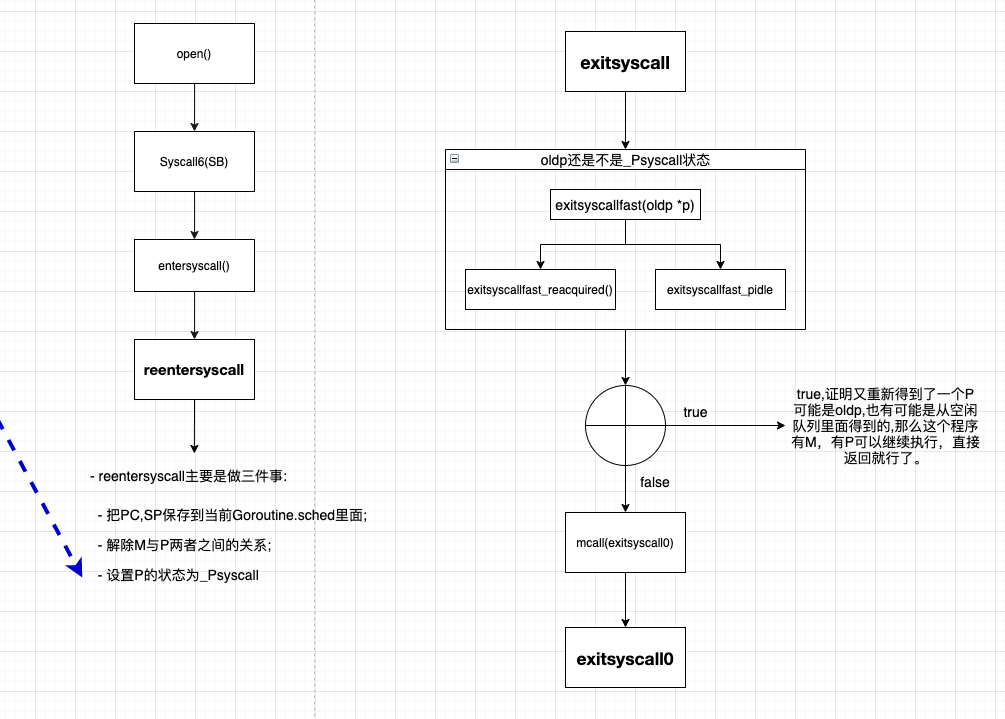
entersyscall #
src/runtime/proc.go
func entersyscall() {
reentersyscall(getcallerpc(), getcallersp()) // 这个是Goroutine的pc, sp,不是g0的,因为还没有切换栈。
}
reentersyscall #
- reentersyscall主要是做三件事:
- 把PC,SP保存到当前Goroutine.sched里面;
- 解除M与P两者之间的关系;
- 设置P的状态为_Psyscall
/*
- 把PC,SP保存到当前Goroutine.sched里面;
- 解除M与P两者之间的关系;
- 设置P的状态为_Psyscall
*/
func reentersyscall(pc, sp uintptr) {
_g_ := getg() // get Goroutine的g
// Disable preemption because during this function g is in Gsyscall status,
// but can have inconsistent g->sched, do not let GC observe it.
_g_.m.locks++ // ++就能让GC不能观察到?TODO zxc:
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
_g_.stackguard0 = stackPreempt //进入系统调用前就设置了抢占标志。
_g_.throwsplit = true
// Leave SP around for GC and traceback.
save(pc, sp) //保存寄存器的值到当前Goroutine的sched结构体。
_g_.syscallsp = sp //gc使用
_g_.syscallpc = pc //gc使用
casgstatus(_g_, _Grunning, _Gsyscall) // 修改状态
if _g_.syscallsp < _g_.stack.lo || _g_.stack.hi < _g_.syscallsp {
systemstack(func() {
print("entersyscall inconsistent ", hex(_g_.syscallsp), " [", hex(_g_.stack.lo), ",", hex(_g_.stack.hi), "]\n")
throw("entersyscall")
})
}
if trace.enabled {
systemstack(traceGoSysCall)
// systemstack itself clobbers g.sched.{pc,sp} and we might
// need them later when the G is genuinely blocked in a
// syscall
save(pc, sp)
}
if atomic.Load(&sched.sysmonwait) != 0 {
systemstack(entersyscall_sysmon)
save(pc, sp)
}
if _g_.m.p.ptr().runSafePointFn != 0 {
// runSafePointFn may stack split if run on this stack
systemstack(runSafePointFn)
save(pc, sp)
}
_g_.m.syscalltick = _g_.m.p.ptr().syscalltick //把P的syscalltick,放到m中。
_g_.sysblocktraced = true
_g_.m.mcache = nil
pp := _g_.m.p.ptr()
pp.m = 0 // 解除P与M的关系。
_g_.m.oldp.set(pp) // 把现在的P放到M中的oldp中。
_g_.m.p = 0 // 解除M与P的关系。
atomic.Store(&pp.status, _Psyscall) // 修改P的状态为系统调用。
if sched.gcwaiting != 0 {
systemstack(entersyscall_gcwait)
save(pc, sp)
}
_g_.m.locks-- // --解除锁定。
}
这里需要注意的是:在进入系统调用的时候,它是没有进行自增的,它是在
exitsyscall()函数才开始进行自增的;这个就是为了判断P,在当前Goroutine进入系统调用,到返回的那一段时间,这个P有可能又被其他M关联,然后又进入_Psyscall状态,
_g_.m.syscalltick = _g_.m.p.ptr().syscalltick //把P的syscalltick,放到m中。
exitsyscall #
- 这个退出系统调用:
- 尝试重新绑定oldp,如果没有成功,从全局空闲P队列获得一个P。
- 如果还是失败,mcall–>exitsyscall0(),
- 在这个里面再次从全局空闲P队列中尝试下,如果失败就把Goroutine放入全局空闲G队列;
- M放入全局空闲M队列,休眠M;
- schedule().
/*
这个退出系统调用:
- 尝试重新绑定oldp,如果没有成功,从全局空闲P队列获得一个P。
- 如果还是失败,mcall-->exitsyscall0(),
- 在这个里面再次从全局空闲P队列中尝试下,如果失败就把Goroutine放入全局空闲G队列;
- M放入全局空闲M队列,休眠M;
- schedule().
*/
func exitsyscall() {
_g_ := getg()
_g_.m.locks++ // see comment in entersyscall 防止GC? TODO zxc:
if getcallersp() > _g_.syscallsp {
throw("exitsyscall: syscall frame is no longer valid")
}
_g_.waitsince = 0
oldp := _g_.m.oldp.ptr() //重新取出oldp
_g_.m.oldp = 0
if exitsyscallfast(oldp) { //如果返回true,那么M与P在这个里面已经重新关联了。
if _g_.m.mcache == nil {
throw("lost mcache")
}
if trace.enabled {
if oldp != _g_.m.p.ptr() || _g_.m.syscalltick != _g_.m.p.ptr().syscalltick {
systemstack(traceGoStart)
}
}
// There's a cpu for us, so we can run.
_g_.m.p.ptr().syscalltick++ //系统调用完成,syscalltick自增。
// We need to cas the status and scan before resuming...
casgstatus(_g_, _Gsyscall, _Grunning)
// Garbage collector isn't running (since we are),
// so okay to clear syscallsp.
_g_.syscallsp = 0
_g_.m.locks--
if _g_.preempt {
// restore the preemption request in case we've cleared it in newstack
_g_.stackguard0 = stackPreempt
} else {
// otherwise restore the real _StackGuard, we've spoiled it in entersyscall/entersyscallblock
_g_.stackguard0 = _g_.stack.lo + _StackGuard //在entersyscall里面我们设置_g_.stackguard0 = stackPreempt //进入系统调用前就设置了抢占标志。这里要恢复。
}
_g_.throwsplit = false
if sched.disable.user && !schedEnabled(_g_) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}
_g_.sysexitticks = 0
if trace.enabled {
// Wait till traceGoSysBlock event is emitted.
// This ensures consistency of the trace (the goroutine is started after it is blocked).
for oldp != nil && oldp.syscalltick == _g_.m.syscalltick {
osyield()
}
// We can't trace syscall exit right now because we don't have a P.
// Tracing code can invoke write barriers that cannot run without a P.
// So instead we remember the syscall exit time and emit the event
// in execute when we have a P.
_g_.sysexitticks = cputicks()
}
_g_.m.locks--
// Call the scheduler.
mcall(exitsyscall0)
if _g_.m.mcache == nil {
throw("lost mcache")
}
// Scheduler returned, so we're allowed to run now.
// Delete the syscallsp information that we left for
// the garbage collector during the system call.
// Must wait until now because until gosched returns
// we don't know for sure that the garbage collector
// is not running.
_g_.syscallsp = 0
_g_.m.p.ptr().syscalltick++
_g_.throwsplit = false
}
exitsyscallfast #
//go:nosplit
func exitsyscallfast(oldp *p) bool {
_g_ := getg()
// Freezetheworld sets stopwait but does not retake P's.
if sched.stopwait == freezeStopWait {
return false
}
// Try to re-acquire the last P.
if oldp != nil && oldp.status == _Psyscall && atomic.Cas(&oldp.status, _Psyscall, _Pidle) {
/*
- 查看老的P的状态是否是正处于_Psyscall;
- 从reentersyscall里面的三个步骤,当它设置为_Psyscall, 它这个时候是没有与任何M相关联。
- 所以这里如果发现P又处于_psyscall,直接关联。
*/
// There's a cpu for us, so we can run.
wirep(oldp) // 关联M和P;当前的M和这个oldp。
exitsyscallfast_reacquired()
return true
}
// Try to get any other idle P.
if sched.pidle != 0 {
var ok bool
systemstack(func() {
ok = exitsyscallfast_pidle()
if ok && trace.enabled {
if oldp != nil {
// Wait till traceGoSysBlock event is emitted.
// This ensures consistency of the trace (the goroutine is started after it is blocked).
for oldp.syscalltick == _g_.m.syscalltick {
osyield()
}
}
traceGoSysExit(0)
}
})
if ok {
return true
}
}
return false
}
exitsyscallfast_reacquired #
func exitsyscallfast_reacquired() {
_g_ := getg()
if _g_.m.syscalltick != _g_.m.p.ptr().syscalltick { // 如果他们两者不相等,那么说明该p被收回,然后再次进入syscall(因为_g_.m.syscalltick变了)
if trace.enabled {
// The p was retaken and then enter into syscall again (since _g_.m.syscalltick has changed).
// traceGoSysBlock for this syscall was already emitted,
// but here we effectively retake the p from the new syscall running on the same p.
systemstack(func() {
// Denote blocking of the new syscall.
traceGoSysBlock(_g_.m.p.ptr())
// Denote completion of the current syscall.
traceGoSysExit(0)
})
}
_g_.m.p.ptr().syscalltick++ // 这里又开始自增了--->因为它在进入reentersyscall()函数是不能增加这个值的。只有当退出exitsyscall()函数才会自增,所以如果
}
}
mcall(exitsyscall0) #
// exitsyscall slow path on g0.
// Failed to acquire P, enqueue gp as runnable.
//
//go:nowritebarrierrec
func exitsyscall0(gp *g) {
_g_ := getg()
casgstatus(gp, _Gsyscall, _Grunnable) //从系统调用状态转变为可运行状态
dropg() //断开M与G之间的关系
lock(&sched.lock) //要修改全局的sched,先加锁
var _p_ *p
if schedEnabled(_g_) {
_p_ = pidleget() //从全局空闲P队列获取一个P
}
if _p_ == nil {
globrunqput(gp) //如果没有获取P,那么把Goroutine放入全局空闲g队列。
} else if atomic.Load(&sched.sysmonwait) != 0 {
atomic.Store(&sched.sysmonwait, 0)
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
if _p_ != nil { //如果有获取到P。
acquirep(_p_) // 关联P与M
execute(gp, false) // Never returns. 直接执行
}
if _g_.m.lockedg != 0 { // TODO zxc: 我记得是这个某个g,必须运行在某个线程上面,比如,main.main.
// Wait until another thread schedules gp and so m again.
stoplockedm()
execute(gp, false) // Never returns.
}
stopm() //停止M。
schedule() // Never returns.
}
syscalltick #
这个syscalltick;发现不是每次系统调用一次,才增加一次。
在我们这里,
- entersystem
- g.m.syscalltick = g.m.p.ptr().syscalltick
- existsystem
- exitsyscall主函数里面有一次;
- exitsyscallfast_reacquired函数又增加了一次.
// To ensure that traceGoSysExit is emitted strictly after traceGoSysBlock, // we remember current value of syscalltick in m (g.m.syscalltick = g.m.p.ptr().syscalltick), // whoever emits traceGoSysBlock increments p.syscalltick afterwards; // and we wait for the increment before emitting traceGoSysExit. // Note that the increment is done even if tracing is not enabled, // because tracing can be enabled in the middle of syscall. We don’t want the wait to hang.
// 为了确保traceGoSysExit严格在traceGoSysBlock之后发出。 // 我们记住m中syscalltick的当前值(g.m.syscalltick = g.m.p.ptr().syscalltick)。 // 不管是谁发出traceGoSysBlock,都会在之后增量p.syscalltick。 // 我们等待增量后再发出 traceGoSysExit。 // 注意,即使没有启用跟踪,增量也会被完成。 // 因为跟踪可以在syscall中间启用。我们不希望等待被挂起。
在这个解释里面,发现跟踪的时候也会syscalltick
4.验证 #
定义程序 #
main.go
package main
import "fmt"
func call_some_job() {
fmt.Println("complete this job")
}
func main() {
for i:=0; i<100000; i++{
i=i
}
call_some_job()
}
gdb调试前准备 #
编译程序 #
编译一下源代码: go build -gcflags "-N -l" -o test ..
准备mcall函数断点的文件 #
- gdb
list /usr/lib/golang/src/runtime/proc.go:267list /tmp/kubernets/test_preempt/main.go:1list /usr/lib/golang/src/runtime/asm_amd64.s:454
gdb调试自定义函数 #
define zxc
info threads
info register rbp rsp pc
end
gdb #
[root@gitlab test_preempt]# gdb ./test
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-119.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /tmp/kubernets/test_preempt/test...done.
Loading Go Runtime support.
(gdb) list
1 package main
2
3 import "fmt"
4
5 func call_some_job() {
6
7 fmt.Println("complete this job")
8 }
9
10 func main() {
(gdb)
11 call_some_job()
12 }
(gdb) b 10
Breakpoint 1 at 0x48cf90: file /tmp/kubernets/test_preempt/main.go, line 10.
(gdb) run
Starting program: /tmp/kubernets/test_preempt/./test
Breakpoint 1, main.main () at /tmp/kubernets/test_preempt/main.go:10
10 func main() {
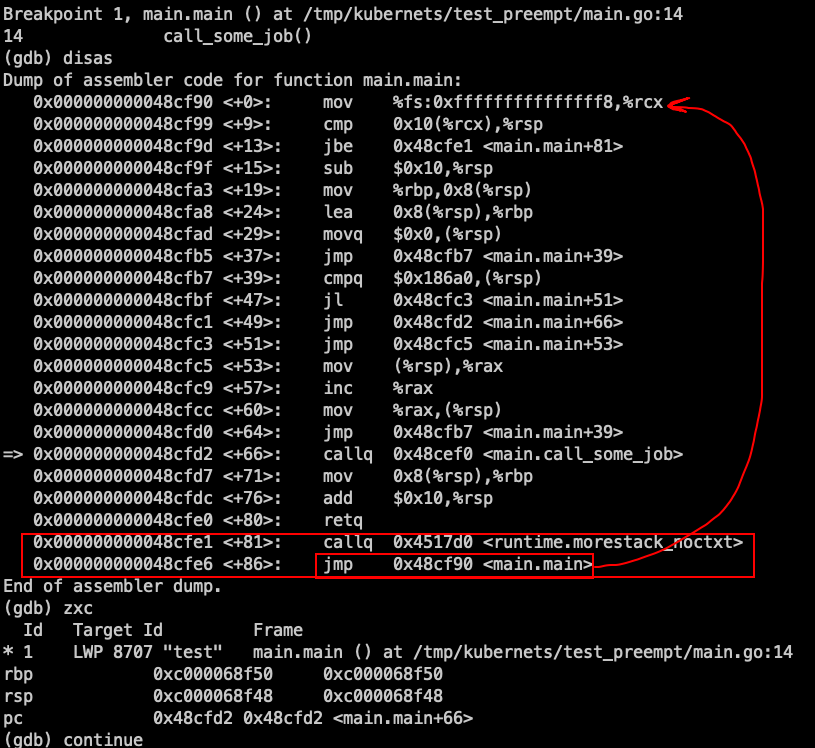
(gdb) disas
Dump of assembler code for function main.main:
=> 0x000000000048cf90 <+0>: mov %fs:0xfffffffffffffff8,%rcx --------------------------------here
0x000000000048cf99 <+9>: cmp 0x10(%rcx),%rsp --------------------------------here
0x000000000048cf9d <+13>: jbe 0x48cfb9 <main.main+41>
0x000000000048cf9f <+15>: sub $0x8,%rsp
0x000000000048cfa3 <+19>: mov %rbp,(%rsp)
0x000000000048cfa7 <+23>: lea (%rsp),%rbp
0x000000000048cfab <+27>: callq 0x48cef0 <main.call_some_job>
0x000000000048cfb0 <+32>: mov (%rsp),%rbp
0x000000000048cfb4 <+36>: add $0x8,%rsp
0x000000000048cfb8 <+40>: retq
0x000000000048cfb9 <+41>: callq 0x4517d0 <runtime.morestack_noctxt> --------------------------------here
0x000000000048cfbe <+46>: jmp 0x48cf90 <main.main>
End of assembler dump.
上面三个--------------------------------here,前面我们说的很清楚,就是g.stack.stackguard0与sp寄存器进行比较,如果sp小于g.stack.stackguard0
就跳转到runtime.morestack_noctxt;而我们前面设置preempt:gp.stackguard0 = stackPreempt //stackguard0==很大的数; 使被抢占的goroutine;在进行函数调用会去检查栈溢出;去处理抢占请求,它必定比sp要大,所以肯定跳转到了runtime.morestack_noctxt
MOVQ 0(SP), AX // f's PC,就是caller’s pc是因为它的rbp在那一步还没有保存到callee‘s stack空间.
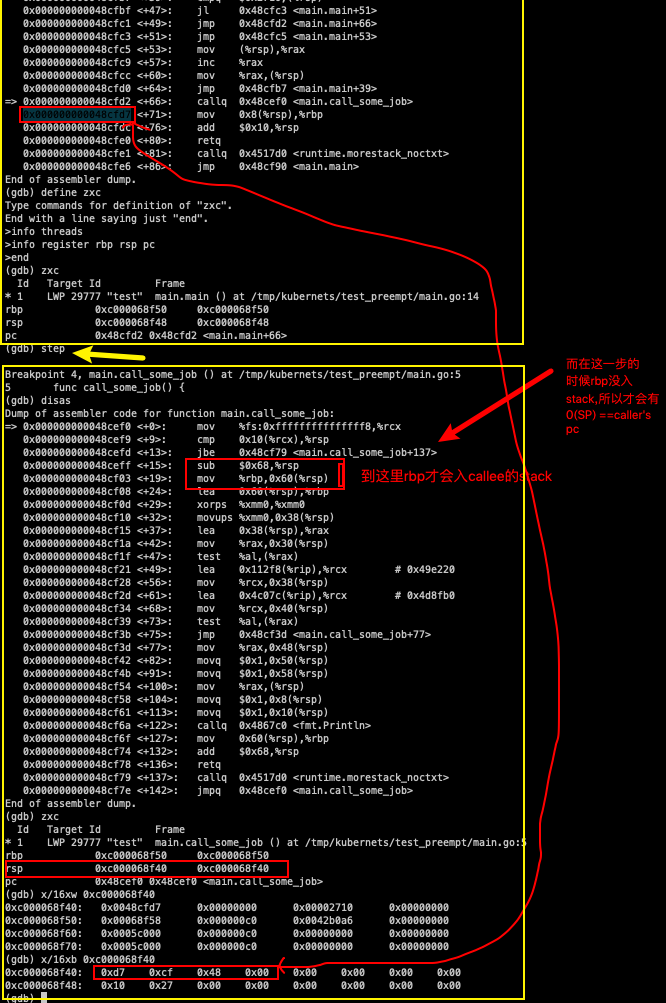
那继续来看如果如果调用<runtime.morestack_noctxt>,它的下一个PC就是jmp 0x48cf90 <main.main>又重新跳回来了.
看这个