1 前言 #
从程序的角度来看, 我们定义个变量,需要知道存储此变量所需的内存大小,以及申请一块内存,并返回内存的首地址;后续变量名与此地址就绑定起来,方便后续操作。
细化下上述所说的内容,主要包含如下:
- 怎么评估变量所需的内存大小?
- 如何申请一块内存。是每次申请时都向操作系统直接申请吗?还是先向操作系统申请一大块内存,在程序内部进行管理,当都用完时,才继续向操作系统进行申请呢?
- 如果第二点都使用后者的方式,那么如何进行管理?
2 评估内存大小 #
2.1 内存对齐 #
- what
什么是内存对齐呢?官方解释是:xxxx
- why 为什么需要进行内存对齐呢? 主要是当前的内存限制的原因。
3 分配内存 #
没有内存管理,每次申请都直接向操作系统申请
通过程序级别的内存管理
因程序运行起来所需要分配的内存块有大有小,而分散的、大小不一的碎片化内存,一方面会降低内存的使用率,另一方面要找到大小合适的内存块的代价会因碎片化而增加,为降低碎片化内存给程序性能造成的不良影响,
3.1 Tcmalloc #
golang采用了类似谷歌的Tcmalloc算法来解决碎片化问题:
Tcmalloc:
- 按照一组预置的大小规格把内存页划分成块,相同的块串联在一个空闲链表中。
- 程序申请内存时,会先根据要申请的内存大小,找到最匹配的规格,然后从对应空闲链表中分配一个空闲块。
4 golang内存管理 #
4.1 内存结构 #
golang把内存大小分为四种级别,分别为:Arena, Page, Span,内存块。
注:下文讨论的都是在amd64架构的Linux环境下.
Arena:golang将堆地址空间划分为一个个arena区,arena区域起始地址定义在arenaBaseOffset,每个arena的大小是64MB,起始地址也对齐到64MB
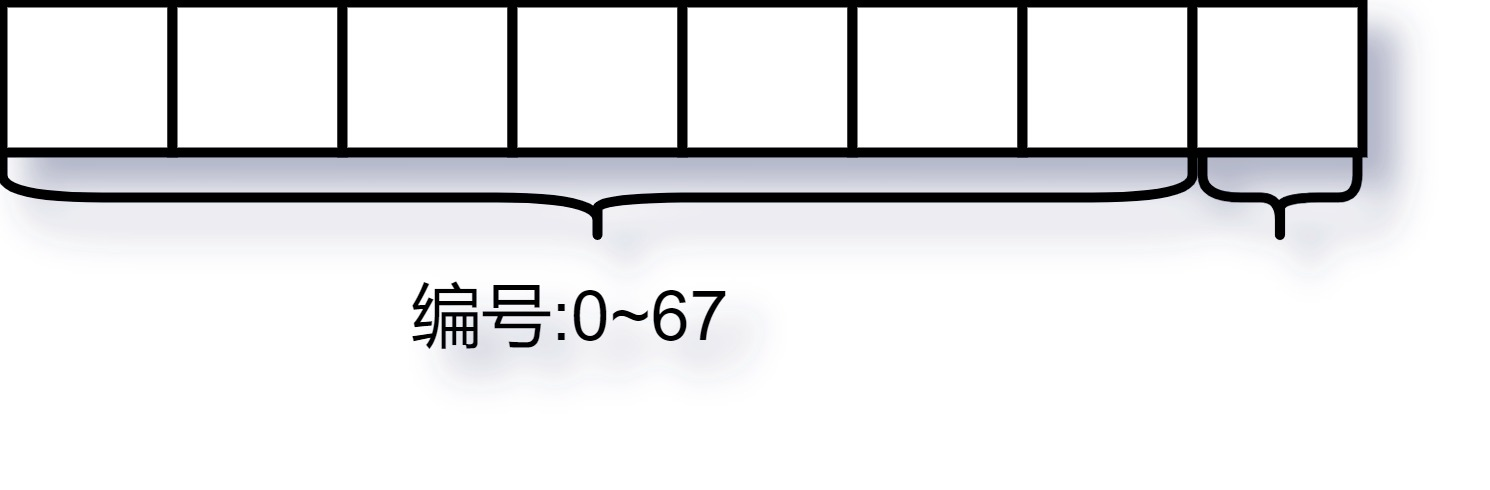
Page:每个arena包含8192个page,所以每个page大小为8KB。
Span:包含一个或多个页大小的内存。golang给出了67种预置的大小规格,最小8Byte,最大32KB,所以在划分整整齐齐的arena中,又会按需划分出不同的Span,每个Span包含一组连续的Page,
| 类别(class) | 内存块对象大小(bytes/obj) | Span大小(bytes/span) | Span中内存块对象个数(objects) | 尾部浪费(tail waste) | 最大浪费百分比(max waste) |
|---|---|---|---|---|---|
| 1 | 8 | 8192 | 1024 | 0 | 87.50% |
| 2 | 16 | 8192 | 512 | 0 | 43.75% |
| 3 | 24 | 8192 | 341 | 8 | 29.24% |
| 4 | 32 | 8192 | 256 | 0 | 21.88% |
| … | |||||
| 66 | 28672 | 57344 | 2 | 0 | 4.91% |
| 67 | 32768 | 32768 | 1 | 0 | 12.50% |
- 内存块:并且按照特定规格划,在Span中分成了等大的内存块。
arena,span,page,内存块就组成了堆内存。
创造span的概念从业务和代码隔离的角度来看,这样做是有意义的。当与外部系统(操作系统可以看作Go程序的外部系统)交互时,创建独立的业务概念可以隔离外部概念(例如Page)对后续业务带来的影响。即使Page的业务形态发生变化,也只需要修改Span与Page之间的交互即可。
因Span中最终存储的是程序要求分配的对象,它们有大有小,如果不在其上划分逻辑等级,会增加分配时的竞争压力,而把对象划分为一定的等级,将相近大小的对象存储到同一级别的Span中,这样在分配时就能分散竞争压力,也尽量避免了空间的浪费。
4.2 内存管理结构 #
golang堆内存由上述的内存结构组成,同样也有对应的管理结构。
- mheap管理整个golang堆内存。
- heapArena管理一个arena。
- mspan管理一个span。
4.2.1 mspan #
mspan管理着span中一组连续的page。
mspan 类的源码位于 runtime/mheap.go 文件中
type mspan struct {
next *mspan
prev *mspan
// next和prev是指定后续和前导的Span。这代表Span的存在形式并非孤立的一个对象,而是一个双向链表。
nelems uintptr
//当前Span中存储的对象数量
startAddr uintptr
npages uintptr
//startAddr(页数) 和 npages(起始地址) — 确定该结构体管理的多个页所在的内存,每个页的大小都是 8KB;
freeindex uintptr
//freeindex — 扫描页中"空闲对象"的初始索引;
allocCache uint64
//allocCache — allocBits 的补码,可以用于快速查找内存中未被使用的内存;
allocBits *gcBits
gcmarkBits *gcBits
//allocBits 和 gcmarkBits — 分别用于标记内存块的占用和回收情况;
spanclass spanClass
// 标识 mspan 等级,包含 class 和 noscan 两部分信息
// type spanClass uint8
}
- nelem记录着当前Span共划分成了多少个内存块
- freelndex记录着下个空闲内存块的索引
mspan这里的位图标记,面向的是划分好的内存块单元
- allocBits用于标记哪些内存块已经被分配了
- gcmarkBits是当前Span的标记位图,在GC标记阶段会对这个位图进行标记,一个二进制位对应Span中的一个内存块,到gc清扫阶段会释放掉旧的allocBits,然后把标记好的gcmarkBits用作allocBits,这样未被gc标记的内存块就能回收利用了,当然会重新分配一段清零的内存给gcmarkBits位图
- spanclass
前面提到Span被划分为 67 种等级(1-67,实际上还有一种隐藏的 0 级,用于处理更大的对象,上不封顶)
| 类别(class) | 内存块对象大小(bytes/obj) | Span大小(bytes/span) | Span中内存块对象个数(objects) | 尾部浪费(tail waste) | 最大浪费百分比(max waste) |
|---|---|---|---|---|---|
| 1 | 8 | 8192 | 1024 | 0 | 87.50% |
| 2 | 16 | 8192 | 512 | 0 | 43.75% |
| 3 | 24 | 8192 | 341 | 8 | 29.24% |
| 4 | 32 | 8192 | 256 | 0 | 21.88% |
| … | |||||
| 66 | 28672 | 57344 | 2 | 0 | 4.91% |
| 67 | 32768 | 32768 | 1 | 0 | 12.50% |
对上表各列进行解释:
(1)class:标识了Span的级别。级别的值可以是1~67的整数
(2)bytes/obj:指定了该级别的Span中对象的最大大小,例如第1行的8代表1~8字节的对象大小;第2行的16代表9~16字节的对象大小。
(3)bytes/span:指定了该级别的Span中的存储空间大小。例如8192代表了8KB,即1个Page。需要注意的是,多个级别的Span可能有着相同的大小。
(4)object:指定可以在Span中存储多少个对象。Span在分配时,首先会将整个Span切分为objects个数的元素,每个元素存储一个对象。等于 (3)/(2)
(5)tail waste:尾部浪费。理想情况下,Span被全部填满,但在尾部仍然无法避免内存空间浪费。例如,class为1时,单个元素为8字节,单个Span为8KB,8字节可以被8KB整除(8192%8=0),此时不会产生浪费;但当class为3时,单个元素大小为24字节,单个Span为8KB,8192%24=8,代表会产生8字节的尾部浪费。(3)/(2)可能除不尽,于是该项值为(3)%(2)
(6)max waste:最大浪费率。当一个对象的大小刚好超过某个级别的最大值时,该对象将会被存储到下个级别的Span中,此时便容易产生浪费。例如1字节大小的对象会被存入class为1的Span中,但是可能会产生7字节的浪费,此时浪费率为7/8×100%=87.5%;而17字节的对象会被存储到class为3的Span中,产生的最大浪费率为(24−17)/24×100%=29.24%。
再来看看spanclass的实现:
runtime/mheap.go
type spanClass uint8
// uint8 左 7 位为 mspan 等级,最右一位标识是否为 noscan
func makeSpanClass(sizeclass uint8, noscan bool) spanClass {
return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
}
func (sc spanClass) sizeclass() int8 {
return int8(sc >> 1)
}
func (sc spanClass) noscan() bool {
return sc&1 != 0
}
spanclass其实是uint8,也就是8bit,高7位表示了上表的span等级(总共67+1个等级,7个bit足够用了),最低位表示nocan信息(区分是否是否需要扫描)。
4.2.2 heapArena #
mheap中每个arena对应一个HeapArena,记录arena的元数据信息。
代码位于 runtime/mheap.go
type heapArena struct {
spans [pagesPerArena]*mspan
// 实现page到mspan的映射
// const pagesPerArena = 8192
bitmap [heapArenaBitmapBytes]byte
pageInUse [pagesPerArena /8]uint8
pageMarks [pagesPerArena/8]uint8
pageSpecials [pagesPerArena/8]uint8
checkmarks *checkmarksMap
zeroedBase uintptr
}
bitmap:用一位标记这个arena中,一个指针大小的内存单元,到底是指针还是标量(0表示标量,1表示指针),再用一位标记这块内存空间的后续单元,是否包含指针(方便gc时判断是否继续扫描;0表示终止,1表示扫描)。bitmap中用一字节标记Arena中4个指针大小的内存空间。
pagelnUse:是个uint8类型的数组,长度为1024,所以一共8192位,但不是标记哪些页面被使用了,只标记处于使用状态(mSpanInUse)的Span的第一个page。
pageMarks:只标记每个Span的第一个page,在gc标记阶段才修改此位图。在gc清扫阶段会根据这个位图,来释放不含标记对像的span
spans是一个
*mspan类型的数组(大小为8192),用于记录当前arena中每一页对应到哪一个mspan。(看这个mspan的结构可以知道,它有startAddr与npages,说明一个mspan管理多个page)
基于HeapArena记录的元数据信息,我们只要知道一个对象的地址,
就可以根据HeapArena.bitmap信息扫描它内部是否含有指针; 也可以根据对象地址计算出它在哪一页,然后通过HeapArena.spans信息查到该对象存在哪一个mspan中。
4.2.2 mheap #
Go语言的runtime将堆内存用数据结构mheap来管理。 它的主要字段如下:
type mheap struct {
lock mutex
// 堆的全局锁
allspans []*mspan
// 记录了所有的 mspan. 需要知道,所有 mspan 都是经由 mheap,使用连续空闲页组装生成的
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
// 在linux 64位系统下
// 每个heapArena管理的64M大小空间
// 一级数组大小为1
// 二级数组大小为2^22
// 因此理论上,Golang堆上限为2^22*64M=256T
central [numSpanClasses]struct {
mcentral mcentral
// 用于内存地址对齐
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
// 多个 mcentral,总个数为 spanClass 的个数
//...
}
4.2.2.1 mcentral #
type mcentral struct {
spanclass spanClass
partial [2]spanSet
// 没有空闲对象(已用尽)的mspan列表
full [2]spanSet
// 有空闲对象(未用尽)的mspan列表
}
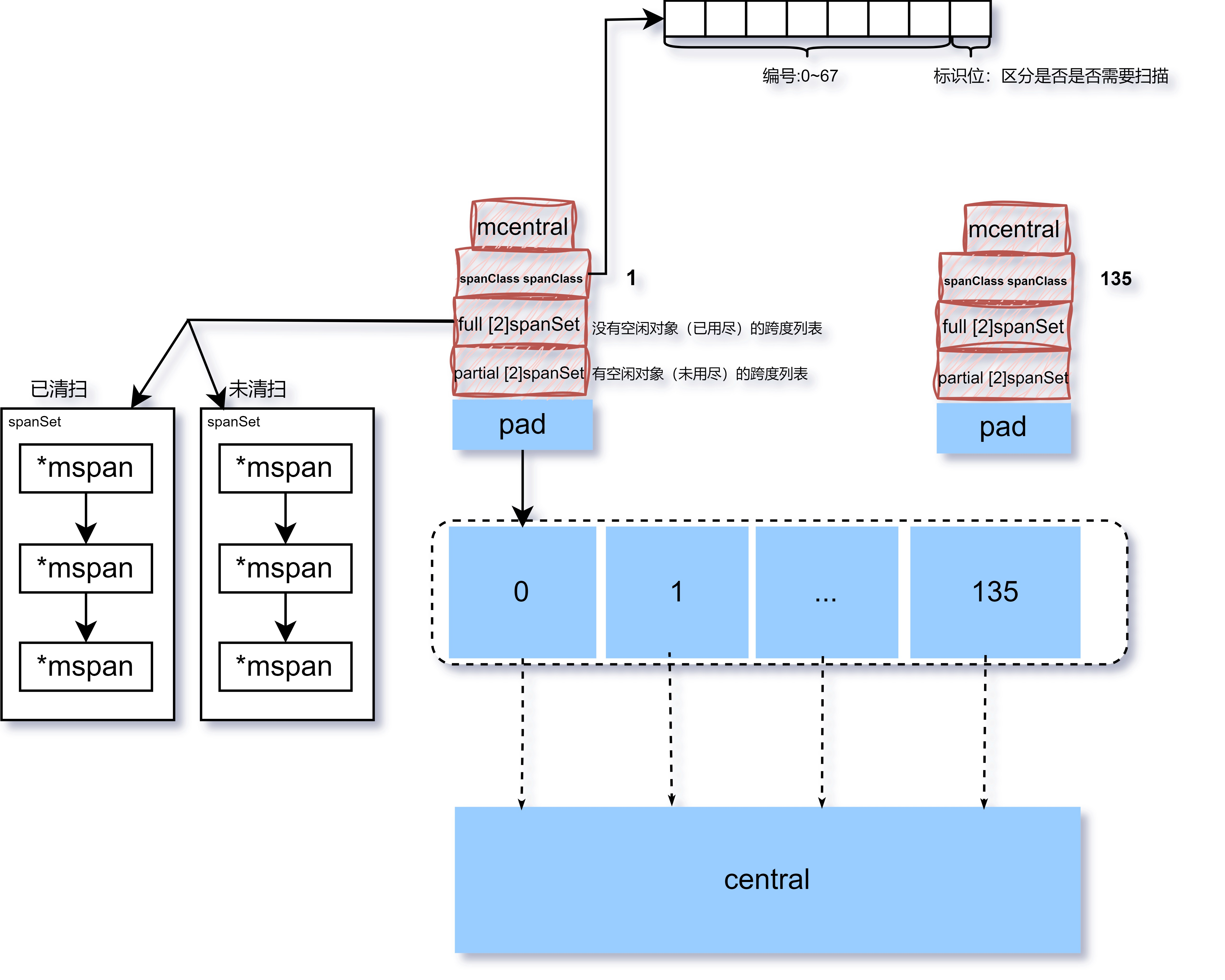
4.2.3 mcache #
全局mspan管理中心,方便取用各种规格类型的mspan,但是为保障多个P之间并发安全,需要频繁加锁、解锁。 为降低多个P之间的竞争性,每个P都有一个本地小对像缓存(mcache)
type mcache struct{
//...
alloc [numSpanclasses]*mspan
// numSpanClasses =_NumSizeClasses << 1
// _NumSizeClasses为Span级别的个数是68,那么numSpanClasses的实际值为136
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
}
alloc:是指已经分配到当前mcache(线程级别)的mspan对象。每个级别都会保存两个Span链表(带有指针和不带指针)。带有指针的Span链表会参与垃圾回收的扫描过程,而不带指针的Span链表则无须进行垃圾回收,从而提高了垃圾回收的效率。
mcache中还有一个处理微小对象(小于16B对象)分配器tiny allocator
(1)tiny,指向当前正在使用的微对象内存块的地址。 (2)tinyoffset,指向为新的微对象分配内存时的起始地址。 (3)tinyAllocs,已经存储了多少微对象。
4.2 内存申请流程 #
Go语言将内存对象的大小分为3类:微对象、小对象和大对象。其大小范围如下: (1)微对象:(0,16)字节。 (2)小对象:[16, 32K]字节。 (3)大对象:32K字节以上。
这3种对象的分配策略不同。大于32KB的对象毕竟是少数,因此会直接在堆内存进行分配。而对于占据程序绝大多数的微对象和小对象,
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if size <= maxSmallSize {
// 小于 32KB 的微、小对象
if noscan && size < maxTinySize {
// 微对象(小于16B且无指针)
// (1) tiny allocator
} else {
// 小对象
// (2) mcache.allocator
} else {
// 大对象(大于32KB)
// (3) large span
}
}
4.2.1 宏观流程 #
从申请过程来看,是直接通过本地mcache与全局mheap配合工作来进行申请:
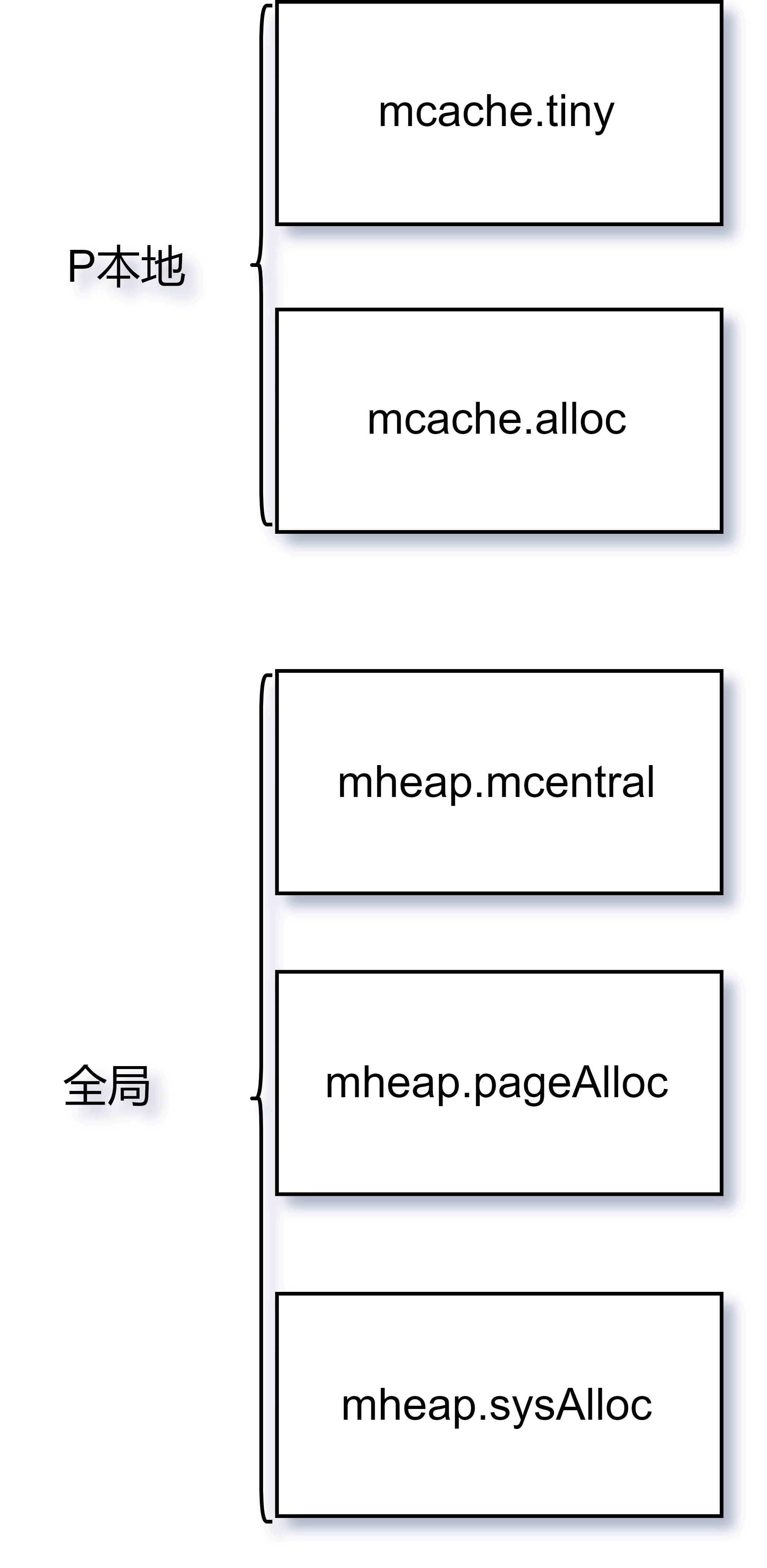
其申请过程由上而下,每一步只要成功则直接返回. 若失败,则由下层方法进行兜底。
整体的分配流程如下:
- 微对象:
- P本地mcache.tiny分配器获取
- P本地mcache.alloc缓存的mspan中获取(根据申请的spanClass)
- 全局mheap.mcentral取mspan填充到对应P本地mcache.alloc,然后从中获取(根据申请的spanClass)
- 全局mheap.pageAlloc(页分配器)取得足够数量连续空闲页组装成mspan填充到mcache
- 全局mheap向操作系统申请内存,更新mheap.pageAlloc(页分配器)的索引信息,然后重复步骤4
第3步需加spanClass粒度锁 第4步需加mheap全局锁
小对象 分配流程只执行第2到第5步骤。
大对象 分配流程只执行第4到第5步骤。
4.2.2 微观流程 #
4.2.2.1 步骤一:mcache.tiny分配 #
每个P独有的mache会有个微对象分配器Tiny allocator,它可以将多个较小的内存分配请求(小于16字节的)合并存入同一个内存块中,只有当内存块中的所有对象都需要被回收时,整片内存才可能被回收。这样做主要是为了减少浪费,例如:如果需要连续分配16次1字节的内存,每次分配时匹配预置的内存规格8字节(最小的spanclass),那么每次都会浪费7字节。
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if size <= maxSmallSize {
// 小于 32KB 的微、小对象
if noscan && size < maxTinySize {
// --------------------------------------------------------------------------------------------------
// 获取mcache的变量tinyoffset,表示Tiny空间空闲的位移
off := c.tinyoffset
// 内存对齐
if size&7 == 0 { // size 在 (0, 16) 范围,如果低三位是0,则跟8位对齐
off = alignUp(off, 8)
} else if goarch.PtrSize == 4 && size == 12 {
// 地址长度是4,字节数是12,也是跟8位对齐
off = alignUp(off, 8)
} else if size&3 == 0 { // size低二位是0,跟4位对齐
off = alignUp(off, 4)
} else if size&1 == 0 { // size低一位是0,跟2位对齐
off = alignUp(off, 2)
}
if off+size <= maxTinySize && c.tiny != 0 {
// 如果对象的大小和off偏移量加起来仍然比16B小,且Tiny空间存在,则当前对象可以从已有的Tiny空间分配
// 在当前的Tiny空间分配,增加相关变量大小
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.tinyAllocs++
mp.mallocing = 0
releasem(mp)
return x // 分配后直接返回
}
// 从当前P的mcache的spanClass为5的mspan中,申请一个新的16B Object的Tiny空间
span = c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 {
v, span, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
// 将申请的16B内存空间置0,16B由两个长度为uint64地址指向
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// 非竞态下,如果申请的内存块分配了新对象后,剩余的空间比当前tiny所持有的空间少,那么需要进行替换
if !raceenabled && (size < c.tinyoffset || c.tiny == 0) {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
// --------------------------------------------------------------------------------------------------
} else {
// 小对象
// (2) mcache.allocator
} else {
// 大对象(大于32KB)
// (3) large span
}
}
4.2.2.2 步骤二:mcache.alloc分配 #
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
if size <= maxSmallSize {
// 小于 32KB 的微、小对象
if noscan && size < maxTinySize {
// 微对象(小于16B且无指针)
// (1) tiny allocator
} else {
//--------------------------------------------------------------------------------------------------
//根据对象大小,映射到其所属的 span 的等级(0~66)
var sizeclass uint8
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[divRoundUp(size, smallSizeDiv)]
} else {
sizeclass = size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]
}
size = uintptr(class_to_size[sizeclass])
//创建spanClass 标识,其中前7位(span 的等级(0~66)),最后一位(标识对象是否是指针,方便后续gc判断是否需要扫描)
spc := makeSpanClass(sizeclass, noscan)
//获取 mcache 中的 span
span = c.alloc[spc]
//从mcache的span中尝试获取空间
v := nextFreeFast(span)
if v == 0 {
//mcache分配空间失败,则通过mheap兜底
v, span, shouldhelpgc = c.nextFree(spc)
}
// 分配空间
x = unsafe.Pointer(v)
// ...
// --------------------------------------------------------------------------------------------------
}
} else {
// 大对象(大于32KB)
// (3) large span
}
}
nextFreeFast: 这个函数返回Span上可用的地址,如果找不到则返回0
func nextFreeFast(s *mspan) gclinkptr {
// 计算s.allocCache从低位起有多少个0
theBit := sys.Ctz64(s.allocCache) // Is there a free object in the allocCache?
if theBit < 64 {
result := s.freeindex + uintptr(theBit)
if result < s.nelems {
freeidx := result + 1
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
//更新bitmap、可用的slot索引
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
s.allocCount++
//返回找到的内存的地址
return gclinkptr(result*s.elemsize + s.base())
}
}
return 0
}
nextFree:如果在cached span里面找到未使用的object,则返回,否则调用refill 函数,从mheap.central中获取对应classsize的span,然后重新查找
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
//先查找mcache中对应规格的span
s = c.alloc[spc]
shouldhelpgc = false
//在当前span中找到合适的index索引
freeIndex := s.nextFreeIndex()
if freeIndex == s.nelems {
// freeIndex == nelems 时,表示当前span已满
// 调用refill函数,从 mcentral 中获取可用的span,并替换掉当前 mcache里面的span
//...
// 再次到新的span里面查找合适的index
freeIndex = s.nextFreeIndex()
}
//...
//计算出来 内存地址,并更新span的属性
v = gclinkptr(freeIndex*s.elemsize + s.base())
s.allocCount++
//...
return
}
4.2.2.3 步骤三:mheap.mcentral分配 #
mcache中mspan空间不足,会调用mcache.refill,向更上层的mheap.mcentral获取mspan。
func (c *mcache) refill(spc spanClass) {
s := c.alloc[spc]
// ...
// 从 mcentral 当中获取对应等级的 span
s = mheap_.central[spc].mcentral.cacheSpan()
// ...
// 将新的 span 添加到 mcahe 当中
c.alloc[spc] = s
}
mcentral.cacheSpan:会先加上sweepLocker锁(spanClass级别的),然后从partial和full中尝试获取有空间的mspan:
func (c *mcentral) cacheSpan() *mspan {
// ...
var sl sweepLocker
// ...
sl = sweep.active.begin()
if sl.valid {
for ; spanBudget >= 0; spanBudget-- {
s = c.partialUnswept(sg).pop()
// ...
if s, ok := sl.tryAcquire(s); ok {
// ...
sweep.active.end(sl)
goto havespan
}
// 通过 sweepLock,加锁尝试从 mcentral 的非空链表 full 中获取 mspan
for ; spanBudget >= 0; spanBudget-- {
s = c.fullUnswept(sg).pop()
// ...
if s, ok := sl.tryAcquire(s); ok {
// ...
sweep.active.end(sl)
goto havespan
}
// ...
}
}
// ...
}
// ...
// mcentral中也没有可用的mspan了,则需要从mheap中获取,最终会调用mheap_.alloc方法
s = c.grow()
// ...
// 执行到此处时,s 已经指向一个存在 object 空位的 mspan 了
havespan:
// ...
return
}
4.2.2.4 步骤四:mheap.pageAlloc分配 #
当从mcentral中的partial和full链表中也找不到对应的mspan,则调用mcentral的grow方法:
func (c *mcentral) grow() *mspan {
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
s := mheap_.alloc(npages, c.spanclass)
// ...
// ...
return s
}
func (h *mheap) alloc(npages uintptr, spanclass spanClass) *mspan {
var s *mspan
systemstack(func() {
// ...
s = h.allocSpan(npages, spanAllocHeap, spanclass)
})
return s
}
func (h *mheap) allocSpan(npages uintptr, typ spanAllocType, spanclass spanClass) (s *mspan) {
gp := getg()
base, scav := uintptr(0), uintptr(0)
// 注意此处存在从每个P的页缓存pageCache中获取空闲页组装mspan
// 加上堆全局锁
lock(&h.lock)
if base == 0 {
// 通过基数树索引快速寻找满足条件的连续空闲页
base, scav = h.pages.alloc(npages)
// ...
}
// ...
unlock(&h.lock)
HaveSpan:
// 把空闲页组装成 mspan
s.init(base, npages)
// 将这批页添加到 heapArena 中,建立由页指向 mspan 的映射
h.setSpans(s.base(), npages, s)
// ...
return s
}
4.2.2.5 步骤五:mheap.sysAlloc分配 #
mheap也找不到所需的空闲page,调用mmap,向系统申请新内存空间:
5 对象的位图标记 #
通过上述的内存申请流程,知道如何为对象申请一块内存。假设我们已经知道了对象的地址,根据地址来串联golang的内存管理单元(heapArena、mspan),进而窥探golang垃圾回收阶段-进行对象扫描所依赖的底层内存结构。
heapArena 结构包含一个 spans 数组,用于从页到 mspan 的映射。
type heapArena struct { spans [pagesPerArena]*mspan }
- 根据堆内存地址找到管理它的heapArean
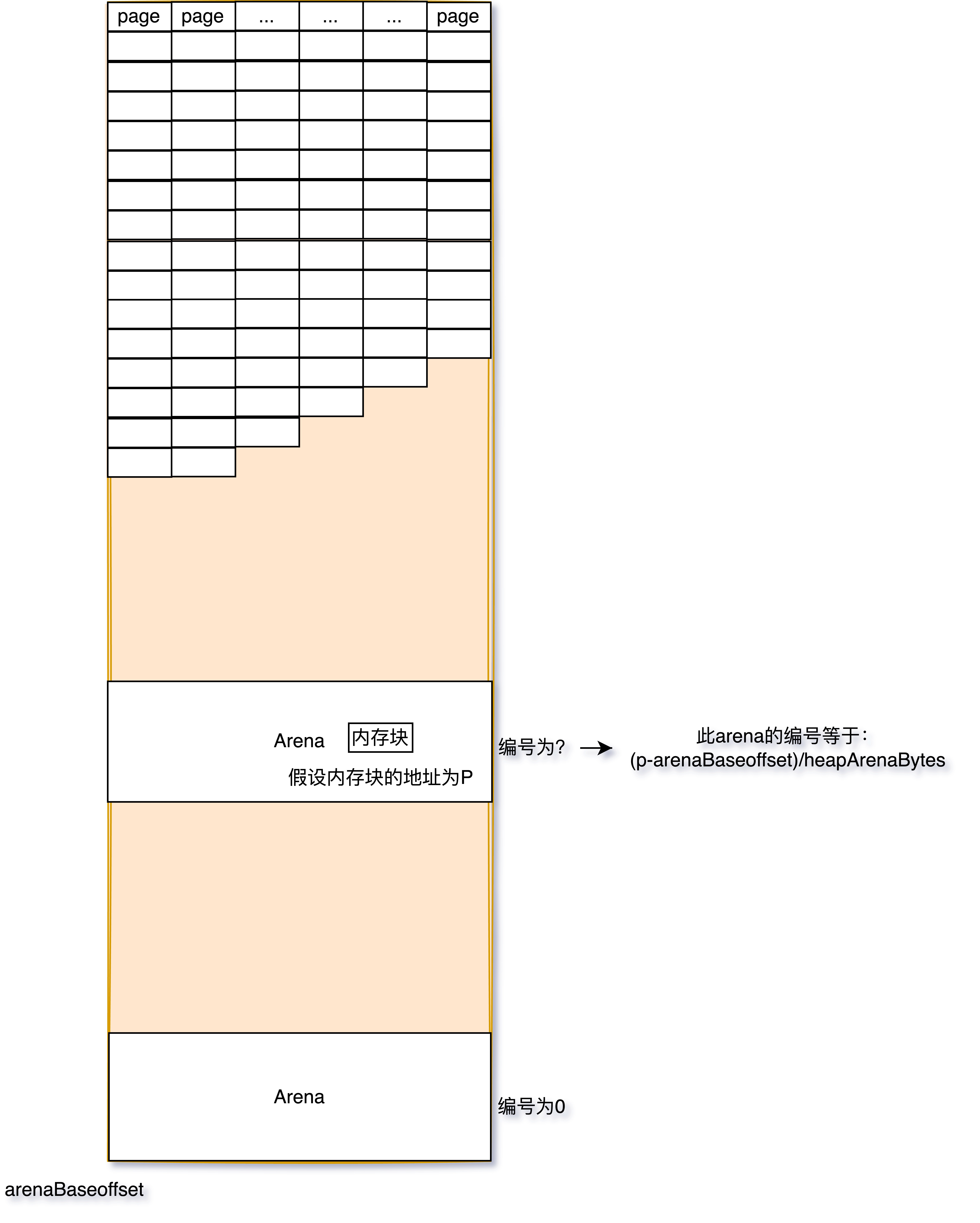
此arena的编号等于:(p-arenaBaseoffset)/heapArenaBytes
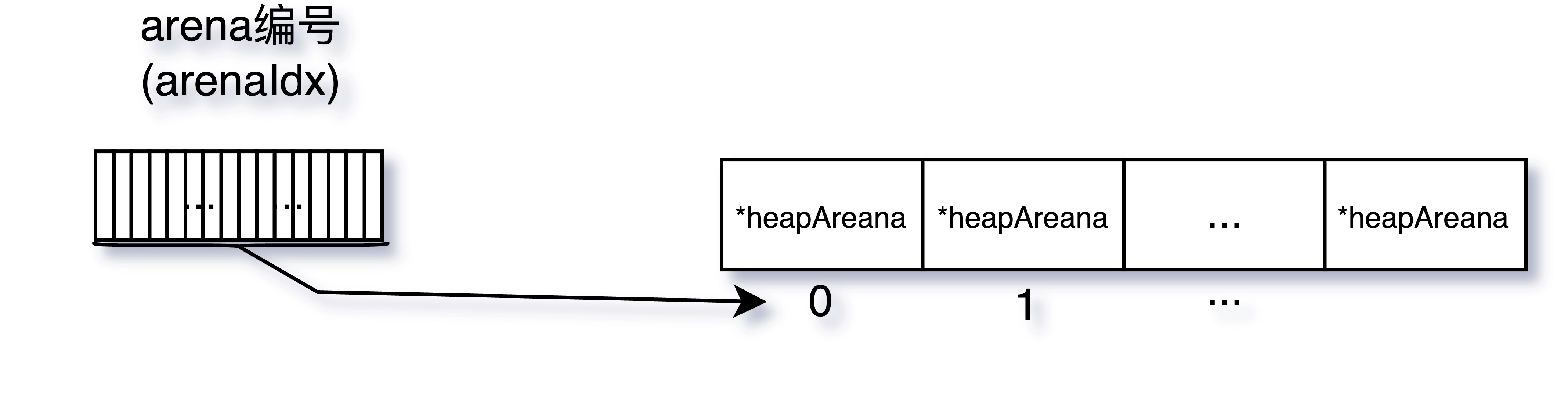
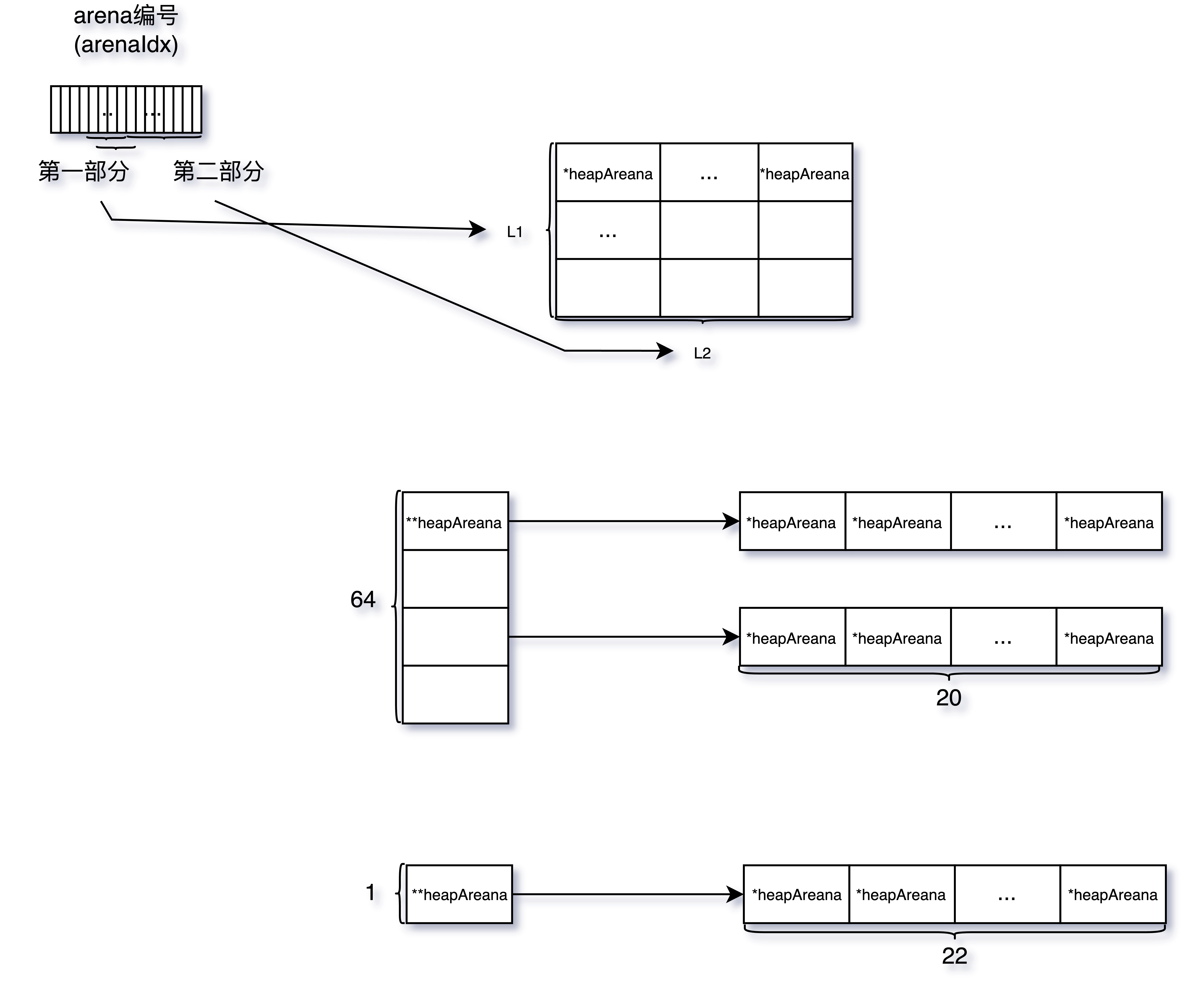
- 根据堆内存地址找到管理它的mspan结构

最后,来看下具体的代码,与上述表述做一个对照:
findObject函数通过调用spanOf函数找到对象p所属的mspan。spanOf函数首先计算对象p所在的arena索引,然后从全局mheap中获取该arena,接着获取具体的heapArena,最后从heapArena中的spans数组中获取具体的mspan。
func findObject(p, refBase, refOff uintptr) (base uintptr, s *mspan, objIndex uintptr) {
s = spanOf(p)
// ...
return
}
func spanOf(p uintptr) *mspan {
// 计算对象所在的 arena 索引
ri := arenaIndex(p)
// 从全局 mheap 中获取该 arena
l2 := mheap_.arenas[ri.l1()]
// 获取该 arena 中的具体 heapArena
ha := l2[ri.l2()]
// 从 heapArena 中的 spans 数组中获取具体的 mspan
return ha.spans[(p/pageSize)%pagesPerArena]
}
- 根据堆内存地址找到对象所对应的结构是否存在指针
接着遍历这块内存对应的位图(heapArena.bitmap),就可以知道对象是否存在引用着其他对象。
- 相关的标记位 span.gcmarkBits表示对应的obj是否被gc标记。 heapArena.pageMarks记录的是哪些span中存在被标记过的对象。
treap #
https://go.dev/play/p/Ya7VlebyNw7
nextfreeindex #
https://go.dev/play/p/DCeEXbirbqe
P #
// https://github.com/golang/go/blob/41d8e61a6b9d8f9db912626eb2bbc535e929fefc/src/runtime/runtime2.go#L576
type p struct {
id int32
status uint32 // one of pidle/prunning/...
link puintptr
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
pcache pageCache
raceprocctx uintptr
pageCache
https://zhuanlan.zhihu.com/p/487455942
areaHint #
src/runtime/malloc.go:434
https://go.dev/play/p/brDHCCSwCoI
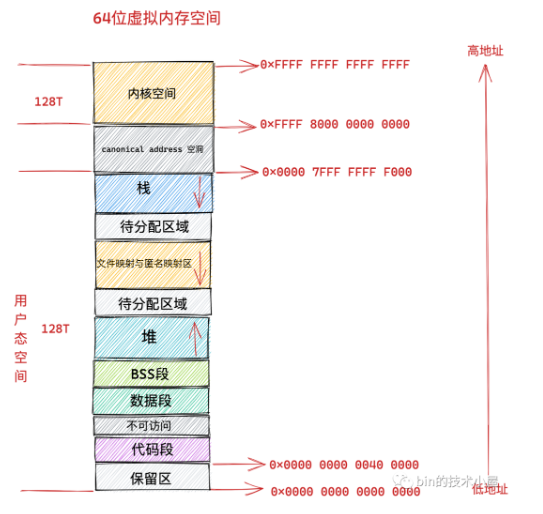
0x00007FFF FFFFFFFF
p:0x00007f0130000000
p:7e0130000000
===================10000000000
p:7d0130000000
===================10000000000
p:7c0130000000
从上面可以看出,系统是从下半段区域开始扩展的,至于原因:在 64 位机器上,Go 选择从内存地址空间的中间开始分配堆内存,目的是避免和其他映射冲突,并且使得在调试时 Go 堆内存地址更容易识别。同时,在 gccgo 等编译器中,栈扫描仍然是保守的,这意味着要确保内存地址与其他数据区分开来。
https://go.dev/play/p/yuEbw87oeLP?v=goprev
https://mp.weixin.qq.com/s?__biz=Mzg2MzU3Mjc3Ng==&mid=2247486732&idx=1&sn=435d5e834e9751036c96384f6965b328&chksm=ce77cb4bf900425d33d2adfa632a4684cf7a63beece166c1ffedc4fdacb807c9413e8c73f298&scene=178&cur_album_id=2559805446807928833#rd
areas #
对于那些不由 Go 堆支持的地址空间区域,arena 映射表包含 nil
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
获取其所在 L2 映射; 如果 L2 映射不存在,则创建一个新的 L2 映射。
检查该 arena 是否已经初始化; 如果已经初始化,则抛出异常。
为该 arena 分配元数据; 如果从 heapArenaAlloc 分配失败,则使用 persistentalloc 进行分配。
将该 arena 添加到 allArenas 列表中; 如果 allArenas 列表已满,则分配一个新的更大的 backing array。
nextFreeFast #
// nextFreeFast returns the next free object if one is quickly available.
// Otherwise it returns 0.
func nextFreeFast(s *mspan) gclinkptr {
theBit := sys.Ctz64(s.allocCache) // Is there a free object in the allocCache?
if theBit < 64 {
result := s.freeindex + uintptr(theBit)
if result < s.nelems {
freeidx := result + 1
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
s.allocCount++
return gclinkptr(result*s.elemsize + s.base())
}
}
return 0
}
https://go.dev/play/p/MrAAyDAassZ
arm64 #
https://www.zhihu.com/question/28638698
16 8 4 2 1
1 1 1 1 1
5位的系统,只使用了4位的虚拟地址,所以虚拟空间只是占用两头,而中间没有使用到,总共占用2^4=16个地址空间。
11111
11110
11101
11100
11011
11010
11001
11000
-----
10111
.....
01000
-----
00111
00110
00101
00100
00011
00010
00001
00000
+--------------------+ 111
| |
| |
| |
| |
| |
| |
| |
|--------------------| 11000
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|--------------------- 00111
| |
| |
| |
| |
| |
| |
| |
+--------------------+
需要把这两块地址空间串联起来,高位地址空间距离00000的偏移量为11000,所以减去11000(非符号位取反+1,符号位不变;注意这里没有符号位,00111+1=01000);从而得到两块地址空间如下:
00111
00110
00101
00100
00011
00010
00001
00000
01111
01110
01101
01100
01011
01010
01001
01000
其实我们应该换个角度来看问题,还记得计算机组成原理里面无处不在的局部性原理么?
每个进程都有 4GB 的虚拟地址空间,而显然对于大多数程序来说,其使用到的空间远未达到 4GB,因为会存在部分对应的页表项都是空的,根本没有分配,对于已分配的页表项,如果存在最近一定时间未访问的页表,在物理内存紧张的情况下,操作系统会将页面换出到硬盘,也就是说不会占用物理内存。
如果使用了二级分页,一级页表就可以覆盖整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。做个简单的计算,假设只有 20% 的一级页表项被用到了,那么页表占用的内存空间就只有 4KB(一级页表) + 20% * 4MB(二级页表)= 0.804MB,这对比单级页表的 4MB 是不是一个巨大的节约?
那么为什么不分级的页表就做不到这样节约内存呢?
我们从页表的性质来看,保存在内存中的页表承担的职责是将虚拟地址翻译成物理地址。假如虚拟地址在页表中找不到对应的页表项,计算机系统就不能工作了。所以页表一定要覆盖全部虚拟地址空间,不分级的页表就需要有 100 多万个页表项来映射,而二级分页则只需要 1024 个页表项(此时一级页表覆盖到了全部虚拟地址空间,二级页表在需要时创建)。
结构 #
on-heap 和 off-heap 的区别是这个对象占用的内存是否支持垃圾自动回收
off-heap的对象,必须只能手动管理,比如heapArena,mspan等runtime中的数据结构
type mheap struct {
_ sys.NotInHeap
// lock must only be acquired on the system stack, otherwise a g
// could self-deadlock if its stack grows with the lock held.
lock mutex
pages pageAlloc // page allocation data structure
pageAlloc:页面分配器把整个虚拟地址空间划分(假想的)成一个个8KB对齐的大小为8KB的页面,分配器采用位图管理页面分配情况。因为虚拟地址空间过于庞大,所以对位图做了划分,每512个页面,使用一个位图。
2^13 * sizeof(pallocData)
2^13*(16*8)=2^13*128=2^(13+7)=2^20=1M
2^13*2^13*512*8*2^10=256*2^40=2^48=256T
由于每个 runtime.heapArena 都会管理 64MB 的内存,整个堆区最多可以管理 256TB 的内存,这比之前的 512GB 多好几个数量级。
mheap.allocSpan函数利用pageAlloc来分配mspan 都是在mspan的基础之上来进一步分配的;
golang对象分配采用的是:
- sequential allocation
- sequential allocation 的实现方式非常简单,只需要把维护的空间直接分配出去就好,每次分配以后挪动指针,指向剩余空闲的位置的首地址,runtime off-heap object allocator一节中介绍的
persistent allocator采用的就是sequential allocation这个方式。
- sequential allocation 的实现方式非常简单,只需要把维护的空间直接分配出去就好,每次分配以后挪动指针,指向剩余空闲的位置的首地址,runtime off-heap object allocator一节中介绍的
- free-list allocation
- free list allocation 这种分配方式相对sequential allocation这种方式没能更好的利用上缓存的空间局部性原理,并且分配的时候速度慢,虽然有first fit 、next fit、best fit三种寻找空闲块的策略 ,但是多少还是会造成外部碎片。但是free list allocation 可以支持立马把释放的空间放到list中用于后续的分配。
- segregated-fit allocator
- 设置K个size class ,各自的大小是s1,s2…sk (从小到大排队),当程序需要S大小空间的时候,给其分配sn这么多的空间(
sn<=S<sn+1),每种size class都有一个分配器,专门分配这个大小,这样相比 free list allocation 可以免去寻找合适内存块的过程。但是会造成更多的浪费,因为对象的大小不一定正好等于slot的大小。调整size class 的个数和每个的大小是减少浪费的关键。 - segregated-fit allocation 还有一个好处是可以非常方便的处理指向对象内部的指针,这可以为垃圾回收提供便利,对于任何一个指针,可以很轻松的找到这个指针所指向的对象的首地址。
- 设置K个size class ,各自的大小是s1,s2…sk (从小到大排队),当程序需要S大小空间的时候,给其分配sn这么多的空间(
struct mm_struct: memory manage struct vm_area_struct: vma: Virtual memory area
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <unistd.h>
#define handle_error(msg) \
do { perror(msg); exit(EXIT_FAILURE); } while (0)
int
main(int argc, char *argv[])
{
int fd;
char *addr;
off_t offset, pa_offset;
size_t length;
ssize_t s;
struct stat sb;
if (argc < 3 || argc > 4) {
fprintf(stderr, "%s file offset [length]\n", argv[0]);
exit(EXIT_FAILURE);
}
fd = open(argv[1], O_RDONLY);
if (fd == -1)
handle_error("open");
if (fstat(fd, &sb) == -1) /* To obtain file size */
handle_error("fstat");
offset = atoi(argv[2]);
pa_offset = offset & ~(sysconf(_SC_PAGE_SIZE) - 1);
/* offset for mmap() must be page aligned */
if (offset >= sb.st_size) {
fprintf(stderr, "offset is past end of file\n");
exit(EXIT_FAILURE);
}
if (argc == 4) {
length = atoi(argv[3]);
if (offset + length > sb.st_size)
length = sb.st_size - offset;
/* Can't display bytes past end of file */
} else { /* No length arg ==> display to end of file */
length = sb.st_size - offset;
}
addr = mmap(NULL, length + offset - pa_offset, PROT_READ,
MAP_PRIVATE, fd, pa_offset);
if (addr == MAP_FAILED)
handle_error("mmap");
s = write(STDOUT_FILENO, addr + offset - pa_offset, length);
if (s != length) {
if (s == -1)
handle_error("write");
fprintf(stderr, "partial write");
exit(EXIT_FAILURE);
}
munmap(addr, length + offset - pa_offset);
close(fd);
exit(EXIT_SUCCESS);
}
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <unistd.h>
#define handle_error(msg) \
do { perror(msg); exit(EXIT_FAILURE); } while (0)
int
main(int argc, char *argv[])
{
char *v=0x7f216f308000;
int n = 20
p := mmap(v, n, PROT_NONE, MAP_ANON|MAP_PRIVATE, -1, 0)
if (p == MAP_FAILED)
handle_error("mmap");
munmap(addr, 20);
exit(EXIT_SUCCESS);
}