1.同步&异步/阻塞&非阻塞 #
同步/异步、阻塞/非阻塞可从字面上理解。
同步是指相同的步调,既然是相同,必然涉及比较,那至少是关于两者或以上的比较,同理异步描述的是不同的步调,所以同步、异步描述的是两个对象(模块)之间的"关系"。(最常见的比如:调用方、被调用方)。
阻塞是指卡住了,等待在那里而不能做其他事情了。也即是说,阻塞、非阻塞描述的是自身的一个运行状态。
综上所述:同步、异步描述两者的关系, 阻塞、非阻塞描述的是一者的状态,其两者讲的不同的事情。
1.2 同步异步 #
同步异步是一种涉及两着的关系。
程序处理多任务 #
并发,并行引出来的一种多个任务运行的关系,涉及的关系是任务A与任务B
并发是指在同一时间间隔内同时执行多个任务的能力,这些任务可能会交替执行或部分重叠执行。并发的重点在于在同一时间间隔内最大化完成任务的数量,它通常侧重于提高系统的吞吐量和响应 能力。 并行是指同时执行多个任务,这些任务将被同时分配给不同的计算资源,例如不同的处理器、内核或线程/进程。并行的重点在于尽可能缩短任务的执行时间,它通常侧重于提高系统的性能和效率。
并行∈并发,并发=并行+交错
这里并发包括同步(synchronous)和异步(asynchronous)两种方式: 同步是指任务按照一定的顺序依次执行,每个任务需要等待前一个任务完成后才能执行,任务之间有明显的先后顺序。同步执行的任务需要占用CPU资源,但是其执行结果是可预测的。
异步是指任务在不等待其他任务执行结果的情况下,直接进行下一步操作,任务之间不受顺序限制。异步执行的任务不会占用CPU资源,因为它们不会一直等待其他任务的完成,但是其执行结果不一定是可预测的。
程序与外部交互(可以是外部系统,也可能是操作系统) #
调用方与被调用方的关系。
- web开发最多的HTTP接口同步异步。
需要说明的是接口本身不区分同步和异步。这种区分更在于客户端(调用方)如何与接口进行交互,以及服务端(被调用方)如何处理请求。
- 服务端接口
- 服务端实现:服务端处理请求的方式可以是同步的,也可以是异步的。同步实现可能在处理请求时会阻塞直到完成,而异步实现可能会利用事件驱动或多线程来提高并发性和响应速度。
- 对客户端的透明性:从客户端的角度来看,服务端的实现细节是透明的。客户端并不知道服务端是同步还是异步地处理请求。
- 提供额外的机制来支持异步操作,例如:
- Webhooks/mq:服务端在处理完成后主动通知客户端。
- 回调URL:客户端提供一个回调URL,服务端在处理完成后向该URL发送通知。
- 轮询(Polling):客户端定期检查服务端的状态以获取结果。
- 客户端调用
- 同步调用:客户端发起请求并等待响应完成后再继续执行其他操作。这种方式在编写代码时表现为阻塞调用。
- 异步调用:客户端发起请求后可以立即继续执行其他任务,并在响应返回时通过回调、Promise或其他机制处理结果。
- 操作系统的io操作, 同步io,异步io。
《UNIX Network Programming》(简称UNP)中,通常总结了五种I/O模型,这些模型描述了在UNIX系统中进行网络编程时处理I/O操作的不同方式。
阻塞 I/O 模型(Blocking I/O)
- 描述:这是最简单的I/O模型。在发起I/O操作(如read或recv)时,调用方会阻塞,直到数据准备好并完成操作。
- 优点:实现简单,因为所有操作都是顺序进行的。
- 缺点:在等待数据时,调用方无法执行其他任务,这可能导致资源低效利用。
非阻塞 I/O 模型(Non-blocking I/O)
- 描述:调用方在发起I/O操作时立即返回,即使数据尚未准备好。调用方需要不断地重试操作以检查数据是否可用。
- 优点:调用方在等待数据时可以执行其他任务。
- 缺点:需要实现轮询机制(polling),这可能导致CPU资源浪费。
I/O 复用模型(I/O Multiplexing)
- 描述:使用select、poll或epoll等系统调用来监视多个文件描述符。当一个或多个文件描述符准备好进行I/O操作时,系统调用返回。(可以用来等很多描述符, 但需要阻塞着检查是否可读。对同一个描述符的IO操作也是有序的。)
- 优点:允许一个线程同时处理多个I/O操作,提高资源利用率。
- 缺点:在监视大量文件描述符时可能存在性能瓶颈。
信号驱动 I/O 模型(Signal-driven I/O)
- 描述:使用信号机制进行I/O操作。当文件描述符准备就绪时,内核向进程发送信号。(不用监视描述符,而且不用阻塞着等待数据到来,被动等待信号通知,由信号处理程序处理。但对同一个描述符的IO操作还是有序的。)
- 优点:减少了轮询的需要,进程可以在信号到达前执行其他任务。
- 缺点:信号处理相对复杂,需要处理信号的异步性。(仍由请求进程将数据从内核读入用户空间(阻塞))
异步 I/O 模型(Asynchronous I/O)
- 描述:调用方发起I/O操作后立即返回,内核在操作完成后通知调用方。
- 优点:调用方无需等待I/O操作完成,真正的异步处理。
- 缺点:实现复杂,支持此模型的系统接口较少。

其中IO复用和信号驱动,在处理业务逻辑上可以说有异步,但在IO操作层面上来说还是同步的。
异步IO,发送IO请求后,不用等了,也不再需要发送IO请求获取结果了。等到通知后,其实是系统帮你把数据读取好了的,你等到的通知也不再是要求你去读写IO了,而是告诉你IO请求过程已经结束了。你要做的就是可以处理数据了。且同一个描述符上可能同时存在很多请求。
注意:一个操作可以是非阻塞的但仍然是同步的,也就是说调用者仍然需要等待操作完成后才能继续执行。
2.协程 #
什么是协程?协程是可以暂停和恢复的函数。
协程恢复:
- 回到调度器——goroutine
- 回到 caller——python yield
- 直接恢复另一个协程
| \ | 对称(灵活) | 非对称(易用) |
|---|---|---|
| 无栈(性能) | python、rust、c#、c++、js | kotlin |
| 有栈(易用) | - | go、java、lua |
对称(Symmetric) vs 非对称(Asymmetric): 对称协程:协程之间可以相互调用和切换,通常通过显式的调用机制实现。这种方式提供更大的灵活性。 非对称协程:通常有一个主协程(调度器)调用其它协程,协程在执行完后返回到主协程(调度器)。它们在设计上更接近于传统的函数调用,易于理解和使用。
无栈(Stackless) vs 有栈(Stackful): 无栈协程:不需要为每个协程维护单独的调用栈。通常实现起来更轻量,性能较高,但也可能限制了某些功能的实现。 有栈协程:为每个协程维护独立的调用栈,允许协程拥有更复杂的控制流,类似于线程。
| 无栈 | 有栈 |
|---|---|
| 定制结构体 | 自定义栈 |
| 显式暂停 | 隐蔽暂停 |
| 内存紧凑 | 内存浪费/爆栈 |
| 深递归慢 | 深递归快 |
2.1 协程和多线程的关系 #
协程和多线程是两个不同的概念,协程可以多线程,也可以单线程。协程强调异步,线程强调并行。没有线程的协程不能并行,但是依旧可以异步。
3.从服务器编程看goroutine #
- 使用阻塞IO编程:在阻塞模型中,I/O 操作(例如读取或写入数据)需要等待操作完成才能继续执行。这意味着当一个 I/O 操作正在进行时,线程会被阻塞,直到该操作完成。其效率较低,特别是在需要同时处理多个连接的情况下,因为每个连接都会占用一个线程或进程。
适用场景:适合简单和连接数量较少的应用程序。
- epoll+非阻塞(Reactor 模式)编程:程序通过epoll等待I/O事件(如连接、数据可读等),当事件发生时,Reactor分发事件到相应的处理器,由处理器执行非阻塞操作。
适用场景:适合高并发网络服务器,如聊天服务器、实时数据处理系统等。
编程复杂度较高,涉及事件循环、回调等机制,导致逻辑执行顺序不直观,难调试、难维护。
- Go的Netpoller和非阻塞I/O
Go 使用 netpoller 来实现 I/O 多路复用。其是一个跨平台的机制,底层在不同操作系统上使用不同的系统调用来实现,比如在Linux上使用epoll,在BSD系统上使用kqueue,在Windows上使用IOCP。负责在一个线程中高效地监控多个文件描述符的事件(如可读或可写),并将这些事件通知给相应的goroutine。
使用非阻塞I/O是为了避免让操作网络I/O的goroutine陷入到系统调用从而进入内核态,因一旦进入内核态,这个goroutine所在的线程就被操作系统进入了内核态调度,不再执行用户代码,Go的运行时调度器也就失去调度能力,直到线程从内核态退出,重新执行用户代码。
当goroutine使用非阻塞I/O,所操作的文件描述符暂不可读或不可写,不会陷入到内核态,仍在用户态,这时Go运行时调度器会自动将该goroutine挂起,转而执行其他goroutine,当netpoller检测到某个 I/O 事件就绪时,把对应的goroutine放入可执行队列,等待调度器重新调度执行。
高并发性:由于使用了轻量级的 goroutine 和高效的 I/O 多路复用机制,Go 能够同时处理大量的并发连接,而不需要为每个连接创建一个线程。 简单易用:开发者不需要显式管理线程或处理复杂的回调逻辑,Go 的网络库和并发原语使得编写高并发程序变得简单。
- netpoller是异步IO吗,它把数据从内核已经拷贝到用户空间了吗 不是异步IO,重新唤醒goroutine后,goroutine继续执行读/写操作。
- 当进行阻塞IO阻塞后,操作如何恢复的, park —> reRead?
4. GMP模型结构体 #
在Go语言的运行时系统中,GMP模型(Goroutine, Machine, Processor)是用于调度和管理goroutine的核心概念。尽管它们各自只是普通的结构体,但它们协同工作构成了Go语言高效并发模型的基础。
4.1 G结构体 #
g结构体代表一个goroutine,包含了栈、上下文信息以及其他状态信息。
type g struct {
//...
gopc uintptr // 保存创建这个goroutine的代码位置。
startpc uintptr // 保存goroutine绑定的函数的代码地址。
//...
sched struct { // 保存goroutine在切换时的上下文信息,包括栈指针(sp)、程序计数器(pc)、基址指针(bp)。
sp uintptr
pc uintptr
bp uintptr
//...
}
//...
stack stack // 保存goroutine的栈信息。
//...
}
go关键字绑定(gopc、startpc) #
func main() {
// 使用go 关键并发执行一个函数
go fn()
}
func fn(){
fmt.Println("hello world")
}
先来看下上述简单例子,当你用go关键字执行一个函数(fn()函数),在底层会调用newproc函数自动获取一个goroutine,并与待执行的函数(fn())进行绑定G。
func newproc(fn *funcval) {
gp := getg() // 调用者的G
pc := getcallerpc() // go关键字的代码位置(pc)
systemstack(func() {
newg := newproc1(fn, gp, pc) // 真正的绑定过程在这个函数中,绑定完后获得新G
_p_ := getg().m.p.ptr() // 调用者的P
runqput(_p_, newg, true) // 新G放入本地队列,等待调度
})
}
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
//...
newg := gfget(_p_) // 从G的闲置队列获取一个G
//...
newg.gopc = callerpc // **设置go关键字的位置**
newg.startpc = fn.fn // **绑定待被执行的函数fn**
//...
return newg
}
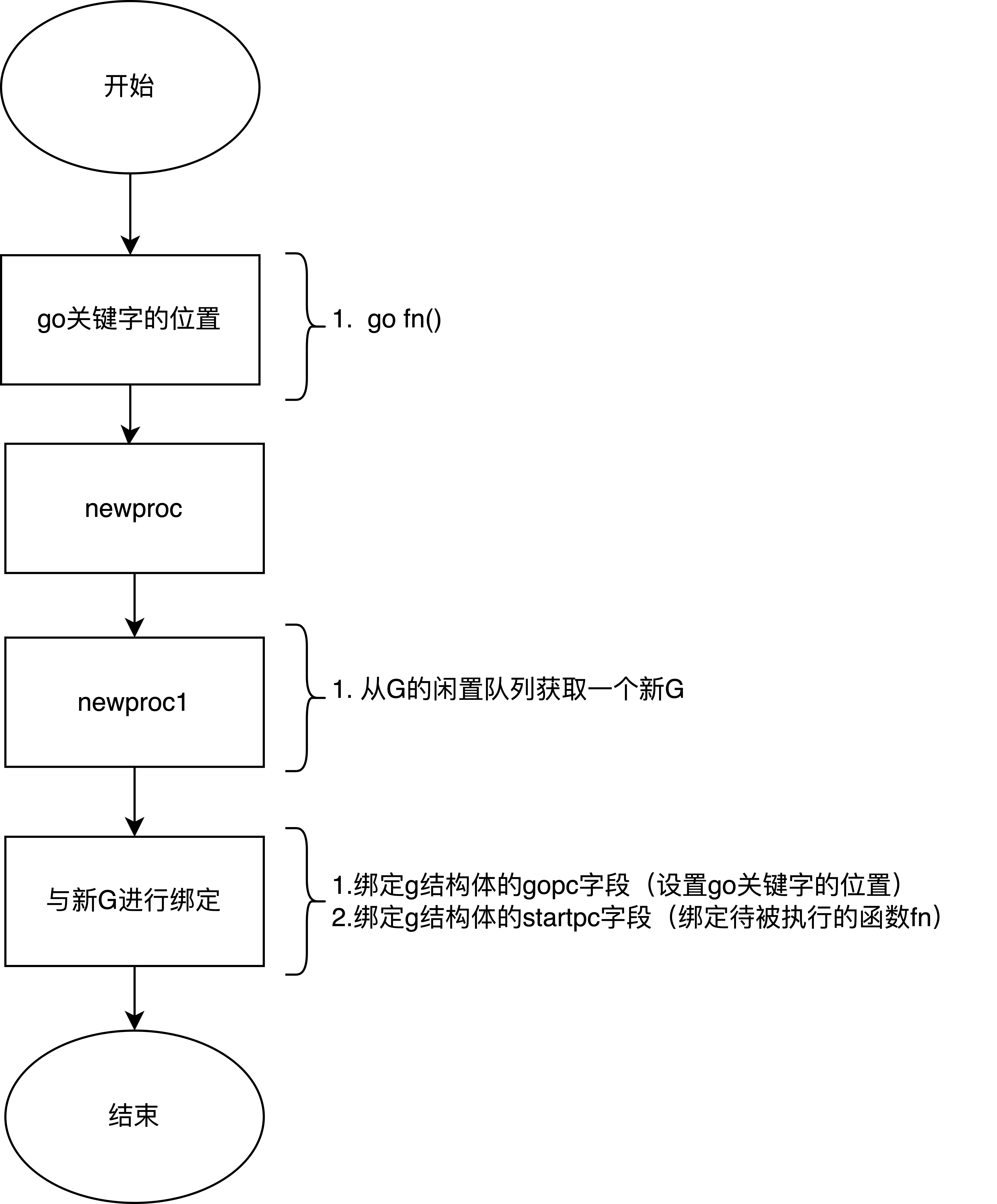
经过上述过程,G和函数就绑定在了一起,而这个绑定在底层也就是设置G的gopc与startpc两个成员变量而已。
type g struct {
//...
gopc uintptr
startpc uintptr
//...
}
goroutine的上下文信息(sched) #
goroutine的上下文切换是高效并发调度的关键。上下文切换涉及保存当前goroutine的运行状态,并恢复另一个goroutine的运行状态。
goroutine的上下文信息保存在g结构体的sched字段中。这个字段是一个gobuf结构体,包含了栈指针(sp)、程序计数器(pc)、基址指针(bp)等。
type g struct {
//...
sched gobuf // Goroutine的上下文信息
//...
}
// Goroutine的上下文信息
type gobuf struct {
sp uintptr // 栈指针:指向栈顶
pc uintptr // 程序计数器:指向将要执行的指令地址
bp uintptr // 基址指针:指向栈基
//...
}
恢复goroutine上下文到寄存器 #
在调度器(schedule函数)中,当需要切换到另一个可执行的goroutine时,会调用execute函数,该函数最终会调用gogo来恢复goroutine的上下文。
func schedule() {
//...
// 找可执行的g (本地队列、全局队列、netpoll list 读或写就绪的g列表 等)
gp, inheritTime, tryWakeP := findRunnable()
//...
// 调用execute函数执行找到的goroutine
execute(gp, inheritTime)
}
func execute(gp *g, inheritTime bool) {
//...
gogo(&gp.sched) // 恢复上下文
}
// ARM64架构下的gogo函数汇编代码:
TEXT runtime·gogo(SB), NOSPLIT|NOFRAME, $0-8
//...
B gogo<>(SB) // 跳转到gogo<>函数
TEXT gogo<>(SB), NOSPLIT|NOFRAME, $0
//...
MOVD gobuf_sp(R5), R0 // **恢复栈指针**
//...
MOVD gobuf_bp(R5), R29 // **恢复基址指针**
//...
MOVD gobuf_pc(R5), R6 // 恢复程序计数器
//...
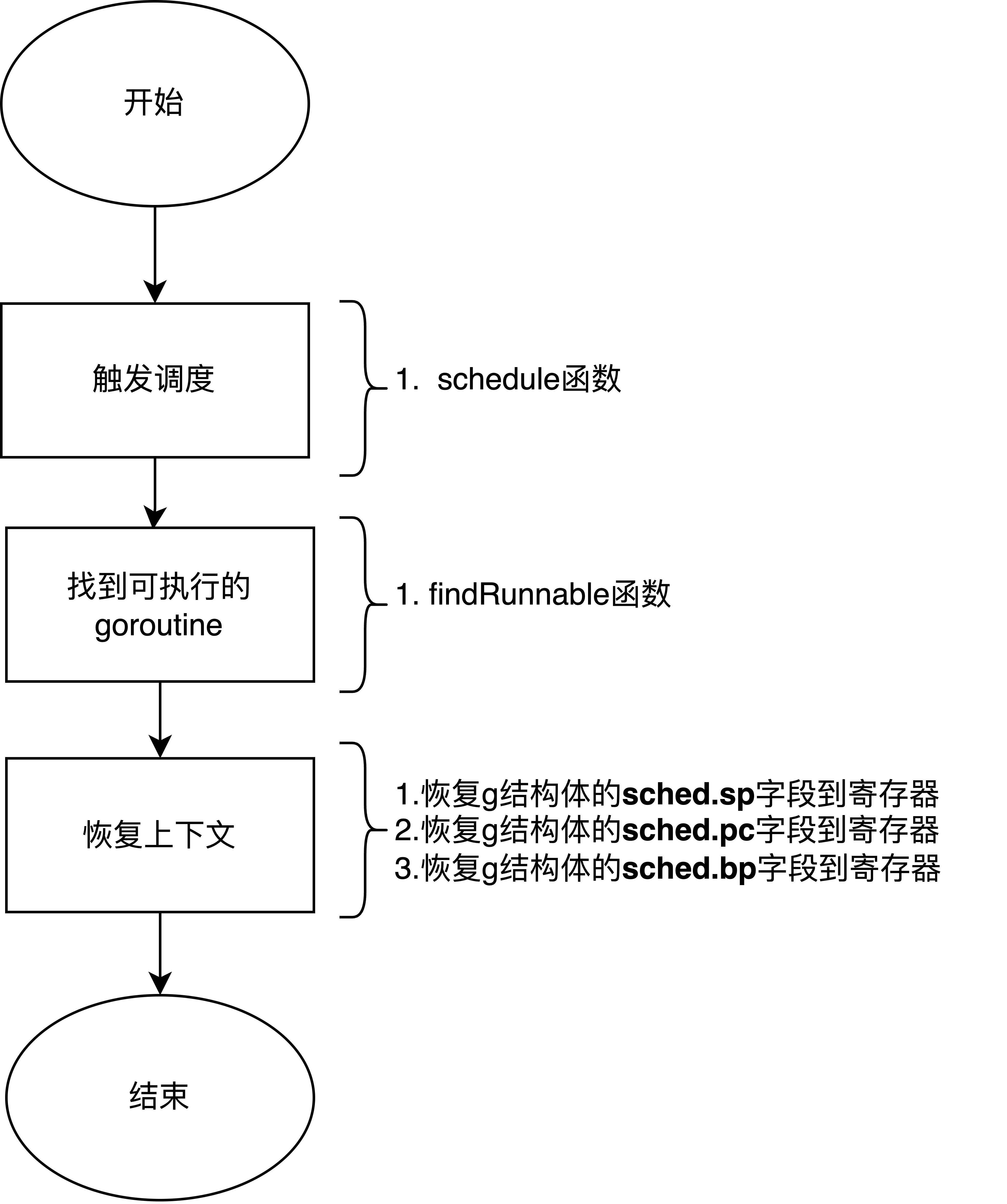
保存寄存器值到goroutine上下文 #
有两个函数会触发保存:
func save(pc, sp uintptr)触发保存上下文func mcall(fn func(*g))触发保存上下文
下面分别来讲述。
- 当协程进入系统调用后,用调用save来保存寄存器的值
// 进入系统调用
func entersyscall() {
reentersyscall(getcallerpc(), getcallersp())
}
func reentersyscall(pc, sp uintptr) {
_g_ := getg()
//...略...
// 保存上下文
save(pc, sp) //调用save函数
_g_.syscallsp = sp
_g_.syscallpc = pc
casgstatus(_g_, _Grunning, _Gsyscall)
//...略...
}
func save(pc, sp uintptr) { // <--- (1)
_g_ := getg()
//...
_g_.sched.pc = pc // 保存代码执行位置
_g_.sched.sp = sp // 保存栈指针
//...
}
getcallerpc, getcallersp 函数返回的是调用者的调用者, 在下面的例子中也就是main函数。
func f(arg1, arg2, arg3 int) {
pc := getcallerpc() // returns the program counter (PC) of its caller's caller. 调用者的调用者,在这里也就是main函数。
sp := getcallersp() // returns the stack pointer (SP) of its caller's caller. 调用者的调用者,在这里也就是main函数。
}
func main(){
//...
f(1,2,3)
//...
}
- 而调用macll函数的场景就比较多,分别为:
- goexit1():goroutine执行完成时
- Gosched():触发协作&抢占式式调度时
- gopark:g从运行状态转换为等待状态时
- exitsyscall():退出系统调用时
TEXT runtime·mcall<ABIInternal>(SB), NOSPLIT|NOFRAME, $0-8 // <--- (2)
//...
MOVD R0, (g_sched+gobuf_sp)(g) // 保存当前g的栈指针
MOVD R29, (g_sched+gobuf_bp)(g) // 保存当前g的基指针
MOVD LR, (g_sched+gobuf_pc)(g)// 保存当前g的下一个待执行指令的位置 PC计数器
//...
G-M:
存在的问题:
- 每个M都会关联一个内存分配缓存mcache(堆分配),造成了大量的内存开销,实际上只有执行代码的M才真地需要mcache,而阻塞在系统调用的M是不需要也不会去申请堆内存。
在 Go 1.2 版本前调度器使用的是 GM 模型,将mcache 放在了 M 里,但发现存在诸多问题,期中对于内存这一块存在着巨大的浪费。每个M 都持有 mcache 和 stack alloc,但只有在 M 运行 Go 代码时才需要使用的内存(每个 mcache 可以高达2mb),当 M 在处于 syscall 或 网络请求 的时候是不需要的,再加上 M 又是允许创建多个的,这就造成了很大的浪费。所以从go 1.3版本开始使用了GPM模型,这样在高并发状态下,每个G只有在运行的时候才会使用到内存,而每个 G 会绑定一个P,所以它们在运行只占用一份 mcache,对于 mcache 的数量就是P 的数量,同时并发访问时也不会产生锁。
G-P-M:
P:它抽象了CPU的调度能力,P的数量通常与CPU核心数相同,确保每个P都能有效地利用系统资源。指的是资源,一组资源。
- 内存分配缓存资源。
- p是g 的存储容器,其自带一个本地 g 队列,为M提供了用于待执行的Goroutine资源。
type p struct {
//...
m muintptr // back-link to associated m (nil if idle)
mcache *mcache // mcache
//...
runq [256]guintptr // 本地runq的队列
runqhead uint32 // 本地runq的队首
runqtail uint32 // 本地runq的队尾
runnext guintptr // 下一个待调度的g(本地runq中的优先q)
}
总结 #
golang GMP概念
what: 是golang内部自己实现的调度器,由’‘G’’,“M”,“P"用来调度goruntine,被称为"GMP模型”。
- GMP
- G:为了调度方便,保存寄存器,栈地址等->
对应cpu切换[1.cpu寄存器的值;2.stack地址] - M:与系统线程一一对应
- P:一些上下文,比如局部P,防止锁,局部P的heap,也能防止加锁的导致的资源损耗。
- G:为了调度方便,保存寄存器,栈地址等->
- GMP
why:
单进程时代不需要调度器
- 1.单一的执行流程,计算机只能一个任务一个任务处理。
- 2.进程阻塞所带来的CPU时间浪费。
多进程/线程时代有了调度器需求
- 1.解决了阻塞的问题
- 2.CPU有很大的一部分都被浪费在进程调度
- 设计会变得更加复杂,要考虑很多同步竞争等问题,如锁、竞争冲突等。
协程(用户线程)来提高CPU利用率(减少CPU浪费在进程调度上)
- 为什么。
- 线程和进程有很多相同的控制权。线程有自己的信号掩码,可以分配CPU时间,可以放入cgroups,可以查询它们使用了哪些资源。所有这些控制都增加了一些功能的开销,而这些功能对于Go程序如何使用goroutine来说是根本不需要的,而且当你的程序中有10万个线程时,它们很快就会增加。
- Go调度器可以做出只在它知道内存是一致的点进行调度的决定。
- 如何进行调度。
- 一种是N:1,即在一个操作系统线程上运行几个用户空间线程。这样做的好处是上下文切换非常快,但不能利用多核系统的优势。
- 另一种是1:1,一个执行线程匹配一个OS线程。它可以利用机器上所有的核心,但是上下文切换很慢,因为它要通过OS进行切换。
- M:N调度器。你可以得到快速的上下文切换,你可以利用系统中所有的核心。这种方法的主要缺点是它增加了调度器的复杂性。
- 摆脱上下文(在这里P就是上下文)?
不行。我们使用上下文的原因是,如果正在运行的线程由于某些原因需要阻塞,我们可以将它们移交给其他线程。- 以前就只有一个全局的P,也可以运行。必须要有P(上下文),是有什么值保存在里面?
- why:
- threads get a lot of the same controls as processes. Threads have their own signal mask, can be assigned CPU affinity, can be put into cgroups and can be queried for which resources they use. All these controls add overhead for features that are simply not needed for how Go programs use goroutines and they quickly add up when you have 100,000 threads in your program.
- Go调度器可以做出只在它知道内存是一致的点进行调度的决定。
- how:
- One is N:1 where several userspace threads are run on one OS thread. This has the advantage of being very quick to context switch but cannot take advantage of multi-core systems.
- Another is 1:1 where one thread of execution matches one OS thread. It takes advantage of all of the cores on the machine, but context switching is slow because it has to trap through the OS.
- M:N scheduler. You get quick context switches and you take advantage of all the cores in your system. The main disadvantage of this approach is the complexity it adds to the scheduler.
- get rid of contexts?
- Not really. The reason we have contexts is so that we can hand them off to other threads if the running thread needs to block for some reason.
这个也就说明了
N-M的基础,用户线程的各自栈空间其实就是放在公共的堆(heap)上。每个系统线程都有一个唯一的m0, g0与之对应,想想为什么?(g0的栈空间与其他的不同,它是放在系统线程的栈空间,**应该是进程的栈空间?**TODO,线程的栈空间)
每个线程有自己的栈空间(而这个g0就在这个栈上)。但是是与其他的线程公用的
代码段,数据段,堆空间,所以当创建其他的goroutine的时候,把它的协裎栈在堆上,所以它可以被其他的M调用。
how:
- Go调度本质是把大量的goroutine分配到少量系统线程上去执行,并利用多核并行,实现更强大的并发。
- 通过这一点去记住,把大量goroutine分配到小量线程去尽快执行
- 复用
- 并发
- 防止饥饿
- 全局G
- 通过这一点去记住,把大量goroutine分配到小量线程去尽快执行
- 调度器的有两大思想:
1
- 压榨系统线程:协程本身就是运行在一组线程之上,不需要频繁的创建、销毁线程,而是对线程的复用。在调度器中复用线程还有2个体现:
- work stealing(不让它休息),当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程。
- hand off(阻塞了,那就换一个压榨),当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
- 利用并行:GOMAXPROCS设置P的数量,当GOMAXPROCS大于1时,就最多有GOMAXPROCS个线程处于运行状态,这些线程可能分布在多个CPU核上同时运行,使得并发利用并行。另外,GOMAXPROCS也限制了并发的程度,比如GOMAXPROCS = 核数/2,则最多利用了一半的CPU核进行并行。
- golang并发和并行:Rob Pike一直在强调Go是并发,不是并行,因为Go做的是在一段时间内完成几十万、甚至几百万的工作,而不是同一时间同时在做大量的工作。并发可以利用并行提高效率,调度器是有并行设计的。
- 压榨系统线程:协程本身就是运行在一组线程之上,不需要频繁的创建、销毁线程,而是对线程的复用。在调度器中复用线程还有2个体现:
- 调度器的两小策略:
- 抢占:在coroutine中要等待一个协程主动让出CPU才执行下一个协程,在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutine的一个地方。
- 全局G队列:在新的调度器中依然有全局G队列,但功能已经被弱化了,当M执行work stealing从其他P偷不到G时,它可以从全局G队列获取G。
- Go调度本质是把大量的goroutine分配到少量系统线程上去执行,并利用多核并行,实现更强大的并发。
202104月总结
- 没有按照what,why, how顺序来说:
- what里面没有阐述G,M,P的实际是什么.
- why里面没有把握调度这个思想.
- 单进程里面不需要调度,但是可能进程阻塞。
- 多线程需要调度,解决了阻塞,
- 但是调度在内核态,调度花费时间长,
- 线程笨重,有自己的信号掩码,。。。// TODO
- 用户态调度,需要调度, 比如协程,goroutine.
- 由协程与系统线程的关联比例,可以分为
[1 : N] [N : 1] [M : N].
- 由协程与系统线程的关联比例,可以分为
- how里面要点出主旨:把大量的goroutine高效的分配给少量的系统线程。
- 二个策略:
- 压榨系统线程:
- M执行P队列中的G完了,不让它销毁或者停止,从别的地方拿
- 当陷入系统调用中,让M-G关联,P重新拿一个M执行剩下的G.
- P的策略,可控制程序的并行数量,[与实际机器的CPU核数]
- 压榨系统线程:
- 两个小策略:
- 防止饥饿;
- 保留一个全局P,当局部P满了,可以放入全局P中。
- 二个策略:
- 没有按照what,why, how顺序来说: