1 前言:变量的存放区 #
通常情况下,变量的分配位置一般是下列三个区:
- 全局数据区
- 栈区
- 堆区
全局数据区:主要用于全局变量的分配,也即包级别的变量,其生命周期和进程相同。
栈区:主要存储函数内部定义的本地变量,当函数执行完毕,变量即可释放。函数执行时通过栈帧加偏移来访问这些数据。
堆区:主要用于程序运行阶段的动态分配。
内存中的对象存在着相互的引用关系。全局数据区与栈区可能指同堆上的数据,这两个地方的指针是堆内存访问的起点,也就是堆内存访问的根节点(root)。
2 定义 #
垃圾回收(garbage collect)简称gc,主要是释放那些不再需要的分配在堆(heap)上的数据, 以便再次用来进行内存分配。垃圾回收一般分为两个步骤:垃圾识别和垃圾清理。
golang支持垃圾自动回收,主要是降低人的心智负担,从堆(heap)中申请的内存,不需要手动的释放。其采用三色标记法来识别垃圾对象,并使用清除算法进行垃圾清理。
2.1 垃圾识别 #
2.1.1 双色标记法 #
根节点一般为全局变量、栈中的变量,维护根节点集合是可达性分析的前提。可达性分析是指从根对象开始,遍历其引用的子节点对象,直至遍历完毕。凡是能够触达的对象,都视作有效对象,而无法触达的,则视作垃圾对象。
双色标标记法采用可达性分析来标记对象状态;通过对象的可达性近视的认为存活性。
双色标记法看上去简单易用,但却存在着一个比较大的缺点,即整个标记过程必须一次性完成,中间不能有任何停顿。也就是说,在执行过程中,不能让出CPU时间片给其他线程。对于应用程序来说,可能会出现用户线程完全停顿,直至标记过程结束。
双色标记法只能描述对象节点自身是否扫描,而不能描述子节点是否完成。这导致重启标记开始后,很难抉择该如何继续,如果再次从根节点开始,那就意味着上次所做的工作完全被浪费掉了。因此,双色标记在停顿、再次重启过程中,无法完成状态的自描述。
由于新增对象无法确定置为黑色还是白色,因此导致扫描过程不能停顿。对双色标记而言可将新增对象直接标记为黑色,然后到下轮垃圾回收才将本轮新增对象中的垃圾对象(往往是生命周期很短的对象)清除。
2.1.2 三色标记法 #
全局数据区与栈区的指针是堆内存访问的起点, 所以把它们放入一个待扫描队列(工作队列),通过它们可以发现堆上第一批可达数据,发现的可达数据中有指针的加入待扫描队列(灰色节点)扫描完的标为黑色,离开队列,通过扫描灰色节点会发现更多灰色节点,也会产生更多黑色点节点,直到没有待扫描的灰色节点,我们就找到了所有可达数据(黑色节点),剩下的白色节点就是不可达数据不可达自然用不到,也即是可以进行释放。
- 黑色:当基于当前节点的追踪任务完成后,表示为存活数据,后续无需再追踪。
- 灰色:基于当前节点展开的追踪还未完成。
- 白色:当追踪完成后,代表可回收的对象。
问题:黑色对象如果指向白色对象,会导致白色对象被错误回收。
原因: 并发执行,如果将白色对象写入黑色对象,同时没有其它未扫描的路径,可抵达该白色对象,它就不会被扫描携程发现,继而被误判为垃圾。
当gc使用三色标记法与用户程序并发执行的时候,可能让黑色对象重新引用了白色对象,且无其他灰色对象引用了这个白色对象。导致白色对象错误回收。(用户程序和垃圾收集器可以在交替工作的)
处理措施:
有两种方法来避免:
- 强三色:黑色对象只能引用灰色对象。
- 弱三色:所有被黑色对象引用的白色对象都处于灰色保护状态.
引入写屏障:就是在执行写操作时,额外做些标记工作(把数据对象的修改通知到垃圾回收器),避免垃圾误判。
分为两种,一种是插入写屏障,一种是删除写屏障。
- 插入写屏障
writePointer(slot, ptr): // ⚠️:slot现在指向的还是旧对象
shade(ptr) //shade函数尝试改变指针的颜色-->改变ptr的颜色
*slot = ptr
- 删除写屏障: 会在老对象的引用被删除时,将白色的老对象涂成灰色。
writePointer(slot, ptr) // ⚠️:slot现在指向的还是旧对象
shade(*slot) //shade函数尝试改变指针的颜色-->改变(*slot)的颜色--->注意这个是*slot(旧对象),slot保存着它原先的保存的地址。
*slot = ptr
引入新问题:只有插入写屏障,但是这需要对所有堆、栈的写操作都开启写屏障,程序性能会受到影响,代价太大。为了改善这个问题,改为忽略协程栈上的写屏障,只在标记结束阶段重新扫描那些被激活的栈帧。但是Go语言通常会有大量活跃的协程,这就导致第二次STW时重新扫描协程栈的时间太长。
- 混合写屏障
把指向的旧对象标记成灰色; 如果当前正在标记的goroutine栈没有完成标记完(标记完,它栈上的对象应该都是黑色的,如果还未有开始当时goroutine栈标记,它的栈应该还是灰色的)则将新对象也标记成灰色。
writePointer(slot, ptr): // ⚠️:slot现在指向的还是旧的对象
shade(*slot) //旧对象标记为灰色。
if current stack is grey: // The insertion part of the barrier is necessary while the calling goroutine's stack is grey.
shade(ptr)
*slot = ptr
shade(*slot)主要是防止用户程序把只有堆上唯一指向的*slot转移到通过栈来唯一指向,从而导致错误回收。
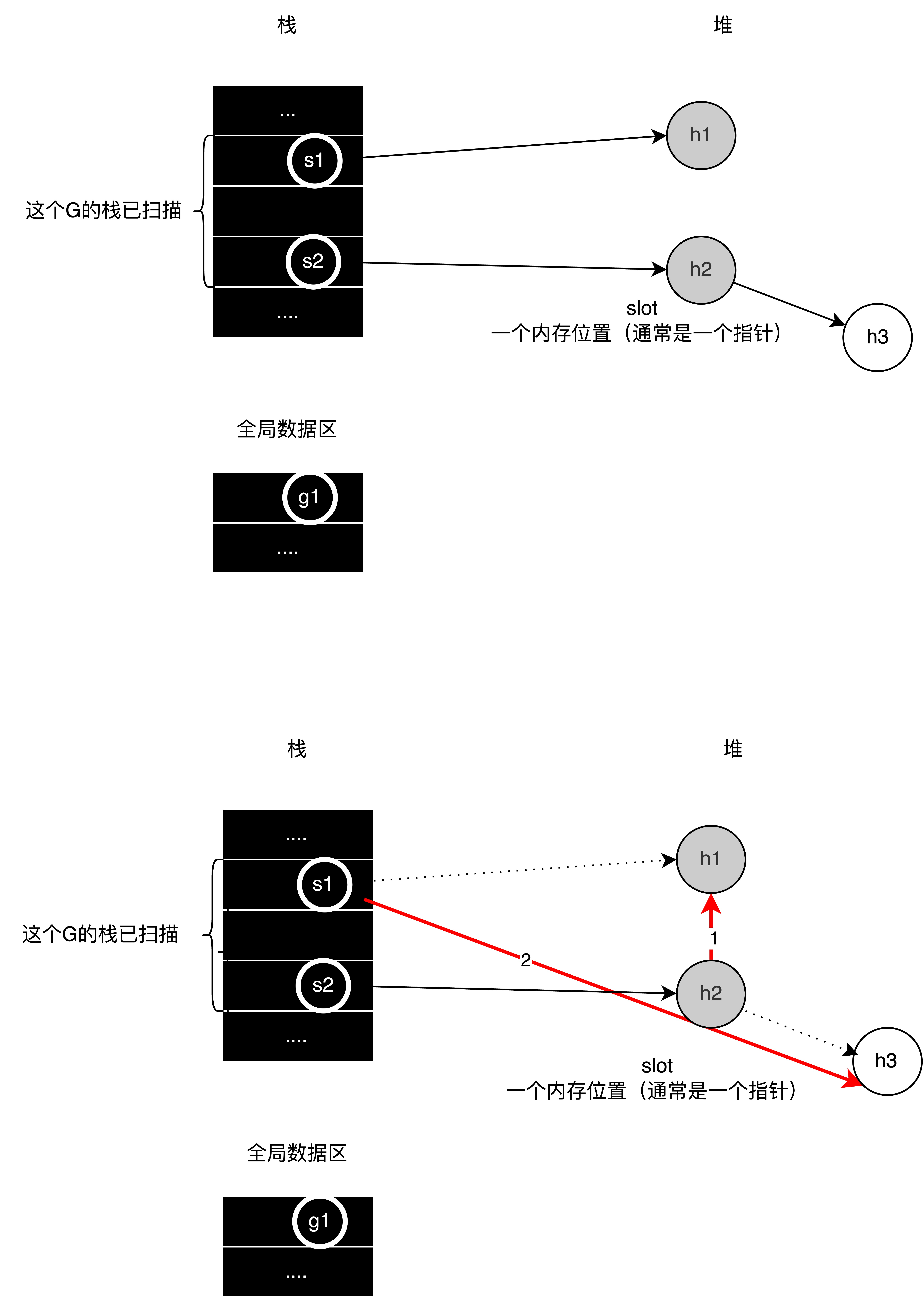
shade(ptr)主要是防止用户程序把只有栈上唯一指向的ptr转移到通过堆来唯一指向,从而导致错误回收。
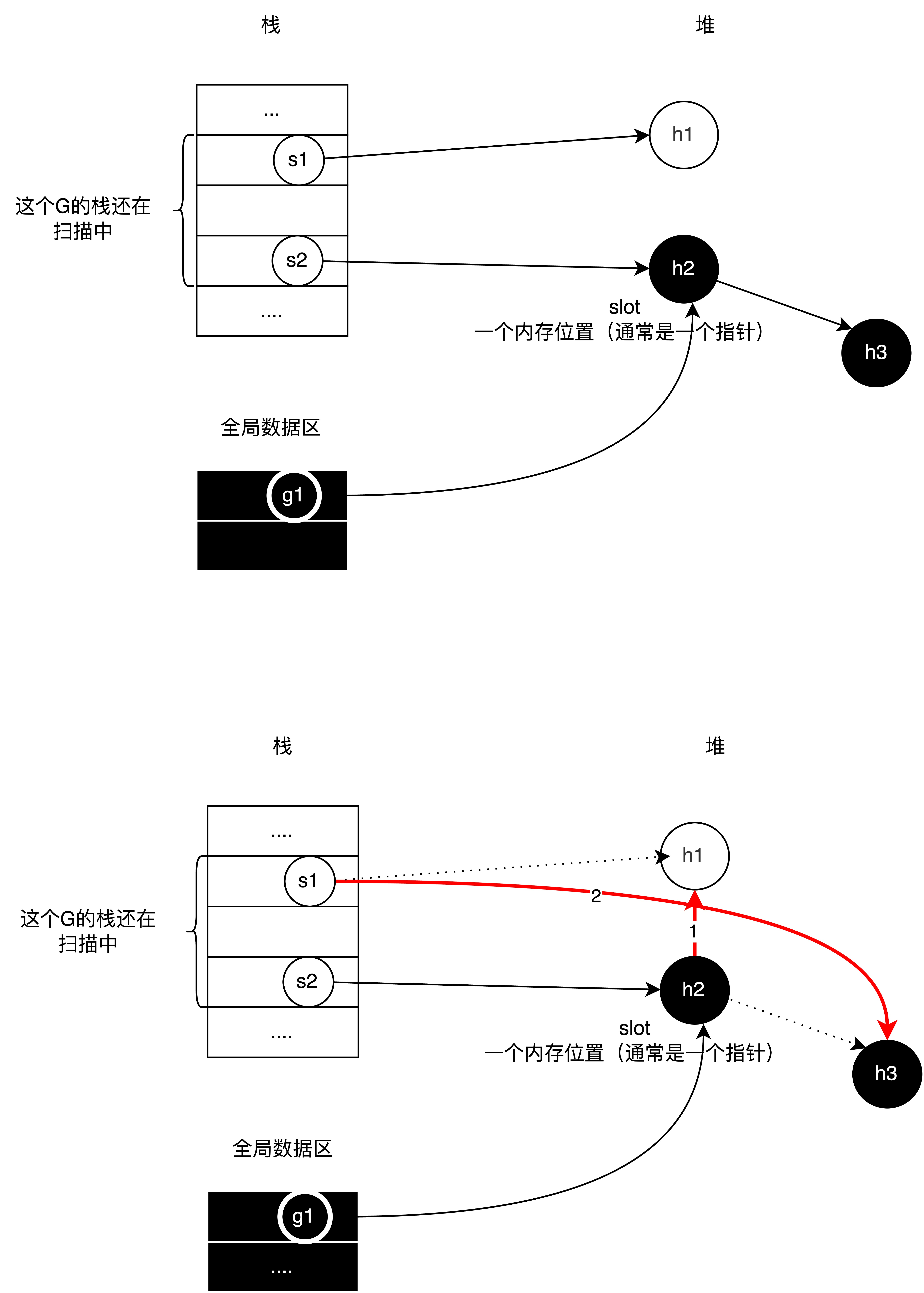
shade(ptr)通过将对象从栈移动到堆来防止隐藏对象,但这需要首先在栈上隐藏一个指针。在堆栈被扫描后,它只指向灰色对象,所以它不会隐藏任何东西。故只有if current stack is grey的才进行shade(ptr)
既可忽略当前栈帧的写屏障,(不管是插入写屏障,还是删除写屏障)又不需要在第二次STW的时,重新扫描所有活跃G的栈帧。
3 golang垃圾回收 #
3.1 三色标记法 #
在golang内存分配器一章中已讲述如何根据内存地址找到对象的所有管理单元以及重要的标志位,在heapArena中就有gc会用到的标志位:
| 颜色 | 含义 | golang具体表示 |
|---|---|---|
| 白色 | 代表未标记也未扫描的对象 | 白色对象就是那些gcMarkBits中标记为0的对象。 |
| 灰色 | 表示已标记但未进行扫描的对象 | 着为灰色对应的操作就是把指针对应的gcmarkBits标记位置为1并加入工作队列 |
| 黑色 | 表示已标记但已扫描的对象 | 着为黑色对应的操作就是移出工作队列,并把指针对应的gcmarkBits标记位置为1 |
这里的工作队列,指的是实现了灰色对象指针的生产者-消费者模型的缓冲队列。
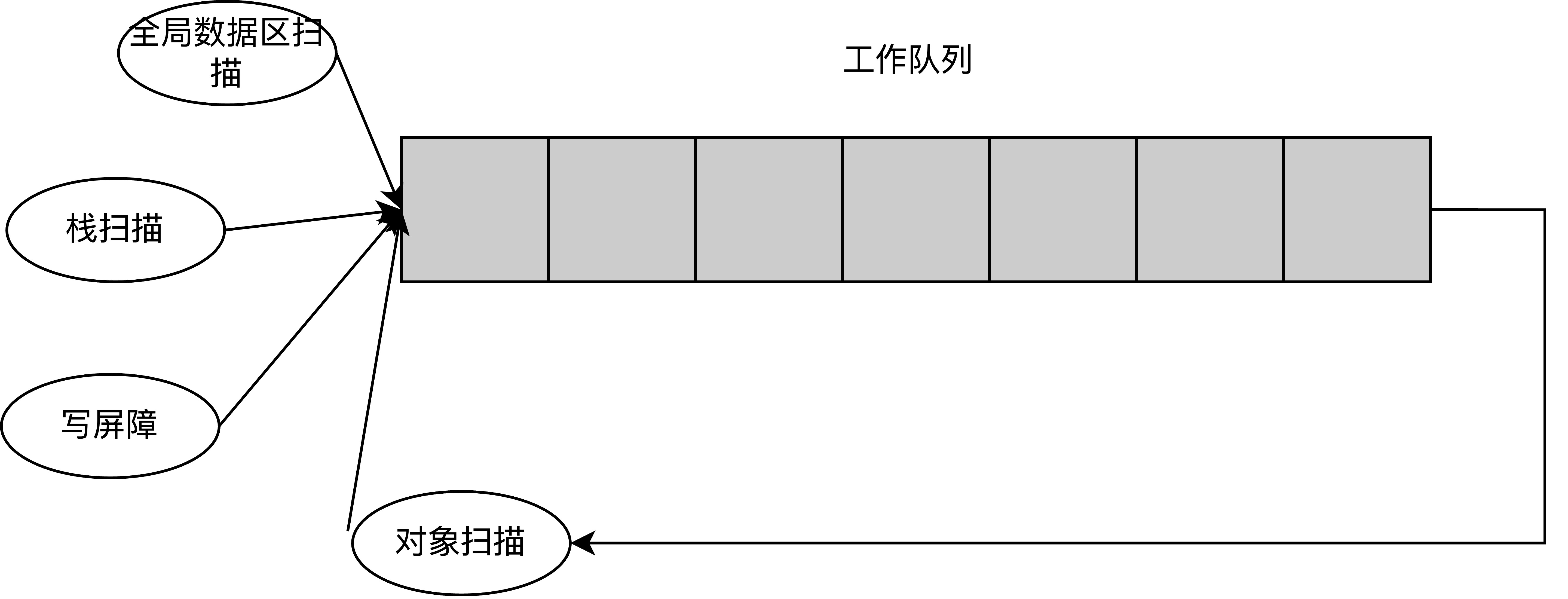
gcWork数据结构源代码如下所示:
type gcWork struct {
wbuf1, wbuf2 *workbuf
// ...
}
type workbuf struct {
workbufhdr
// obj是uintptr数组,用来存储扫描过程中发现的指针。
obj [(_WorkbufSize - unsafe.Sizeof(workbufhdr{})) / goarch.PtrSize]uintptr
}
const _WorkbufSize = 2048 // 数组obj的容量为253。
type workbufhdr struct {
node lfnode
// nobj记录obj数组已使用的个数;当nobj==0表示缓存区为空,当nobj==缓存区长度时表示已满。
nobj int
}
type lfnode struct {
next uint64
pushcnt uint
}
队列有了,下面来看对象置灰操作,主要是greyobject方法中,置灰分三步:
- 将mspan.gcmarkBits对应bit位置为1
- 将heapArena.pageMarks对应bit位置为1
- 将对象添加到灰色对象缓存队列
func greyobject(obj, base, off uintptr, span *mspan, gcw *gcWork, objIndex uintptr) {
mbits := span.markBitsForIndex(objIndex)
//...
// If marked we have nothing to do.
if mbits.isMarked() {
return
}
// 在其所属的 mspan 中,将对应位置的 gcMark bitmap 位置为 1
mbits.setMarked()
// Mark span.
arena, pageIdx, pageMask := pageIndexOf(span.base())
if arena.pageMarks[pageIdx]&pageMask == 0 {
atomic.Or8(&arena.pageMarks[pageIdx], pageMask)
}
// If this is a noscan object, fast-track it to black nstead of greying it.
if span.spanclass.noscan() {
gcw.bytesMarked += uint64(span.elemsize)
return
}
//...
// Queue the obj for scanning.
// 将对象添加到当前 p 的本地队列
if !gcw.putFast(obj) {
gcw.put(obj)
}
}
3.2 总体流程 #
全局变量
- runtime.gcphase 是垃圾收集器当前处于的阶段,可能处于 _GCoff、_GCmark 和 _GCmarktermination,Goroutine 在读取或者修改该阶段时需要保证原子性;
- runtime.gcBlackenEnabled 是一个布尔值,当垃圾收集处于标记阶段时,该变量会被置为 1,在这里辅助垃圾收集的用户程序和后台标记的任务可以将对象涂黑;
- runtime.writeBarrier 是一个包含写屏障状态的结构体,其中的 enabled 字段表示写屏障的开启与关闭;
- runtime.worldsema 是全局的信号量,获取该信号量的线程有权利暂停当前应用程序;
3.2.1 第一次STW #
垃圾收集在启动过程一定会调用runtime.gcStart函数,主要在标记工作之前做一些准备工作,其工作阶段对应垃圾回收总体流程的第一次STW。我们根据这个函数流程图来介绍该函数的实现:
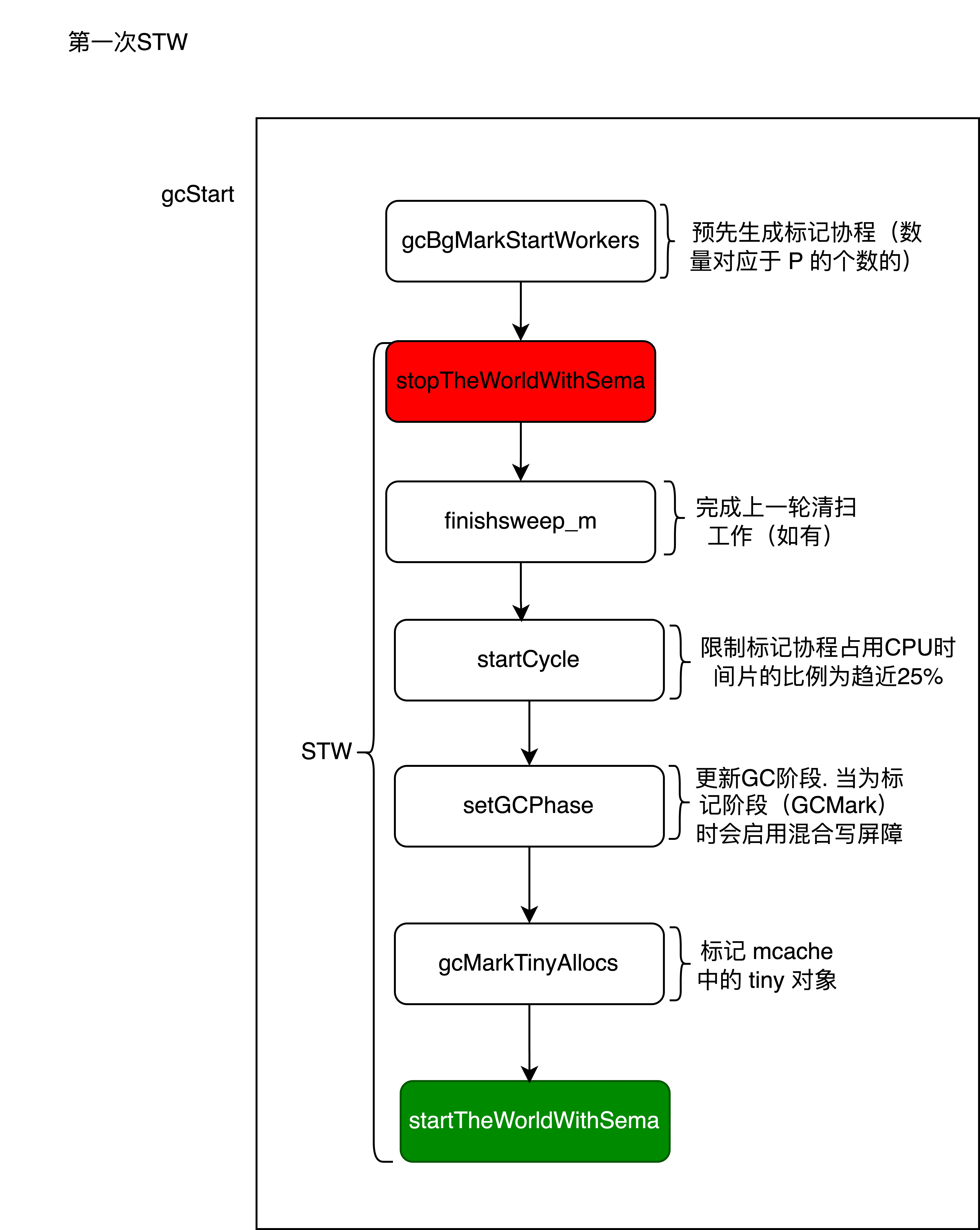
func gcStart(trigger gcTrigger) {
//...
//并发地处理剩余的未清扫/正在清扫的span(完成上一个垃圾收集的收尾工作)。
// 如果我们是在后台模式下调用的,这种情况不应该发生,因为比例清扫应该刚刚完成了所有清扫工作,
// 但四舍五入误差等可能会留下一些未清扫的 span。
// 在强制模式下,这是必要的,因为GC可以在清扫周期的任何点被强制触发。
for trigger.test() && sweepone() != ^uintptr(0) {
sweep.nbgsweep++
}
//...
//加锁
semacquire(&worldsema)
//启动与P的个数相同的标记协程
gcBgMarkStartWorkers()
//...
//1.切换到g0后执行Stop the world操作
systemstack(stopTheWorldWithSema)
//2.在我们开始并发扫描之前完成清扫。
systemstack(func() {
finishsweep_m()
})
//...
//3.限制标记协程占用CPU时间片的比例为趋近25%
gcController.startCycle(now, int(gomaxprocs))
//4.进入并发标记阶段并启用写屏障。
setGCPhase(_GCmark)
//...
//5.标记所有活动的tinyalloc块。
//因为我们正在从这些块中分配内存,所以它们需要像其他分配一样被标记为黑色。另一种选择是在每次从tiny块分配时将其变黑,这会减慢tiny分配器的速度。
gcMarkTinyAllocs()
atomic.Store(&gcBlackenEnabled, 1)
//6.切换至g0,重新start the world
systemstack(func() {
now = startTheWorldWithSema(trace.enabled)
//...
})
//...
semrelease(&worldsema)
//...
}
预生成标记协程 #
gcBgMarkStartWorkers预先生成标记协程(数量对应于P的个数)
其中通过 notesleepg与notewake的机制,使得for循环与gcBgMarkWorker内部形成联动节奏,主要是为了缩短当进入标记阶段后,标记携程可开始标记的时间间隔.
note是go runtime实现的一次性睡眠和唤醒机制,一个线程可以通过调用
notesleep(*note)进入睡眠状态,而另外一个线程则可以通过notewakeup(*note)把其唤醒。
func gcBgMarkStartWorkers() {
for gcBgMarkWorkerCount < gomaxprocs {
go gcBgMarkWorker()
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
gcBgMarkWorkerCount++
}
}
gcBgMarkWorker方法中将g包装成一个node天添加到全局的gcBgMarkWorkerPool中,并调用 gopark 方法将当前g挂起,等待被唤醒.
func gcBgMarkWorker() {
gp := getg()
node := new(gcBgMarkWorkerNode)
gp.m.preemptoff = ""
node.gp.set(gp)
node.m.set(acquirem())
// 唤醒外部的 for 循环
notewakeup(&work.bgMarkReady)
for {
// 当前 g 阻塞至此,直到 gcController.findRunnableGCWorker 方法被调用,会将当前 g 唤醒
gopark(func(g *g, nodep unsafe.Pointer) bool {
node := (*gcBgMarkWorkerNode)(nodep)
// ...
// 将当前 g 包装成一个 node 添加到 gcBgMarkWorkerPool 中
gcBgMarkWorkerPool.push(&node.node)
return true
}, unsafe.Pointer(node), waitReasonGCWorkerIdle, traceEvGoBlock, 0)
// ...
}
}
控制标记协程的CPU利用率 #
GC默认的CPU目标使用率为25%,在初始化阶段,根据gomaxprocs*0.25%得出需要启动的标记协程个数,而这有时不为整数,所以需要进行四舍五入(+0.5,然后转化为整形),但是这样的取整会和原目标产生误差,而误差大于0.3时就比较明显了。
9*25%=2.25然后再+0.5取整,等于3误差为:
3/2.25-1=1/3=0.3333333333333
所以,GC把标记协程分成了以下几种工作模式:
- gcMarkWorkerDedicatedMode:专用标记模式。“不会"被调度器抢占
- 会先以可被抢占的模式尝试执行,倘若真的被用户协程抢占,再将标记模式改为不可抢占模式. (减少当前P下用户协程的等待时长,提高用户体验.)
- gcMarkWorkerFractionalMode:分时标记模式. 当标记协程执行时长达到一定比例后,可以被抢占
- gcMarkWorkerIdleMode: 空闲模式. 随时可以被抢占
记录在对应的P结构中,作为它的标记协程的工作模式。
startCycle会根据全局处理器的个数以及垃圾收集的 CPU 利用率计算出 dedicatedMarkWorkersNeeded 和 fractionalUtilizationGoal 以决定不同模式的工作协程的数量。
还是以上面的例子来说明,fractionalUtilizationGoal等于(2.25-2)/procs的个数。
func (c *gcControllerState) startCycle(markStartTime int64, procs int) {
//...
// 计算后台标记利用率目标。总的来说,这可能不会完全准确。
// 我们四舍五入专用工作线程的数量(+0.5,然后强转换为整形),使利用率尽可能接近 25%。
// 对于小的 GOMAXPROCS,这会引入太多误差,因此在这种情况下我们添加分数工作线程。
totalUtilizationGoal := float64(procs) * gcBackgroundUtilization
c.dedicatedMarkWorkersNeeded = int64(totalUtilizationGoal + 0.5)
utilError := float64(c.dedicatedMarkWorkersNeeded)/totalUtilizationGoal - 1
const maxUtilError = 0.3
if utilError < -maxUtilError || utilError > maxUtilError {
// 四舍五入使我们偏离目标超过 30%。对于 gcBackgroundUtilization 为 25%,
// 这发生在 GOMAXPROCS<=3 或 GOMAXPROCS=6 时。启用分数工作线程进行补偿。
if float64(c.dedicatedMarkWorkersNeeded) > totalUtilizationGoal {
// 专用工作线程太多。
c.dedicatedMarkWorkersNeeded--
}
// 计算出每个 P 需要额外执行标记任务的时间片比例
c.fractionalUtilizationGoal = (totalUtilizationGoal - float64(c.dedicatedMarkWorkersNeeded)) / float64(procs)
} else {
c.fractionalUtilizationGoal = 0
}
//...
}
P会记录自己累计执行Fractional worker的时间,
type P struct {
//...
gcFractionalMarkTime int64 // Nanoseconds in fractional mark worker (atomic)
// gcMarkWorkerMode 是下一个标记工作线程运行的模式。
// 也就是说,这用于与由 gcController.findRunnableGCWorker 选定用于立即执行的工作 Goroutine 进行通信。
// 当调度其他 Goroutine 时,这个字段必须设置为 gcMarkWorkerNotWorker。
gcMarkWorkerMode gcMarkWorkerMode
// gcMarkWorkerStartTime 是最近一次标记工作线程开始运行的 nanotime() 时间。
gcMarkWorkerStartTime int64
//...
}
同时全局的gcControllerState会记录后台标记工作线程开始时间。
type gcControllerState struct{
//...
// markStartTime 是后台标记工作线程开始的绝对时间,以纳秒为单位。
markStartTime int64
//...
}
通过检查当前P累计在fractionalt模式下的工作时间与本轮GC已经执行的时间比值,跟fractionalUtilizationGoal相比较就能知道当前标记协程是否可以退出了,从而控制CPU的使用率。
标记tinyalloc块 #
在标记协程与工作协程并发执行时,工作协程每次申请小对象时,需将tiny块标记为黑色,这将会减慢tiny分配器的速度。所以在第一次STW时,直接把所有的tinyalloc块对应的span区域都标记为黑色,这样在标记阶段申请小对象就不需要做额外的标黑动作,加快了分配速度。
func gcMarkTinyAllocs() {
assertWorldStopped()
for _, p := range allp {
c := p.mcache
if c == nil || c.tiny == 0 {
continue
}
_, span, objIndex := findObject(c.tiny, 0, 0)
gcw := &p.gcw
greyobject(c.tiny, 0, 0, span, gcw, objIndex)
}
}
暂停与恢复程序(stop/start the world) #
暂停程序会使用runtime.preemptall抢占所有的处理器,恢复程序时会使用runtime.notewakeup或者runtime.newm唤醒程序中的处理器。
暂停程序过程如下:
| 调用链 | 说明 |
|---|---|
| sched.gcwaiting标识置为1 | 后续的调度流程见其标识,都会阻塞挂起 |
| 调用preemptall() | 发送抢占信息抢占所有 G,后将 p 状态置为 syscall |
| 所有p的状态设置为stop(包括正在运行以及空闲的p) | |
| 倘若部分任务无法抢占,则等待其完成后再进行抢占 |
恢复程序过程如下:
| 调用链 | 说明 |
|---|---|
| runtime.netpoll | 从网络轮询器中获取待处理的任务并加入全局队列 |
| runtime.procresize | 扩容或者缩容全局的处理器 |
| runtime.notewakeup或者runtime.newm | 依次唤醒处理器或者为处理器创建新的线程;如果当前待处理的 Goroutine 数量过多,创建额外的处理器辅助完成任务; |
3.2.2 标记阶段 #
对内存中对象进行扫描和标记
调度标记协程 #
调度器在调度循环runtime.schedule中还可以通过垃圾收集控制器的runtime.gcControllerState.findRunnabledGCWorker获取并执行用于后台标记任务goroutine。
func schedule() {
//...
// 获取一个标记协程
if gp == nil && gcBlackenEnabled != 0 {
gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
if gp != nil {
tryWakeP = true
}
}
//...
// 调度执行标记协程
execute(gp, inheritTime)
}
func (c *gcControllerState) findRunnableGCWorker(_p_ *p) *g {
//...
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node == nil {
return nil
}
//...
gp := node.gp.ptr()
casgstatus(gp, _Gwaiting, _Grunnable)
//...
return gp
}
这里也就呼应了前文创建标记协程,放入后台标记协程池后,如何调度标记协程,继续执行的逻辑
func gcStart(trigger gcTrigger) {
//...
//启动与P的个数相同的标记协程
gcBgMarkStartWorkers()
//...
}
func gcBgMarkStartWorkers() {
for gcBgMarkWorkerCount < gomaxprocs {
go gcBgMarkWorker()
//...
}
}
func gcBgMarkWorker() {
// 将当前g包装成一个node,后续放入后台标记协程池(gcBgMarkWorkerPool)中
gp := getg()
node := new(gcBgMarkWorkerNode)
gp.m.preemptoff = ""
node.gp.set(gp)
node.m.set(acquirem())
for {
gopark(func(g *g, nodep unsafe.Pointer) bool {
node := (*gcBgMarkWorkerNode)(nodep)
// ...
// 添加后台标记协程池(gcBgMarkWorkerPool)中
gcBgMarkWorkerPool.push(&node.node)
return true
}, unsafe.Pointer(node), waitReasonGCWorkerIdle, traceEvGoBlock, 0)
// ...
}
}
至此我们知道在调度标记协程后,它应该会继续执行runtime.gcBgMarkWorker函数中剩下的逻辑。
标记协程 #
标记协程执行标记工作,是由runtime.gcBgMarkWorker来承接的,该函数的可分为三个部分:
| 阶段 | 含义 | 备注 |
|---|---|---|
| 初始化 | 将当前处理器和Goroutine打包成runtime.gcBgMarkWorkerNode类型的结构体,并主动进入休眠状态,等待被唤醒。 | 【预生成标记协程】一节已讨论 |
| 扫描&标记 | 根据处理器上设置的gcMarkWorkerMode模式,决定采用哪种策略来执行内存中对象图的扫描和标记任务,最终在gcDrain中进行扫描标记。 | 标记协程工作模式已在【控制标记协程的CPU利用率】一节已讨论 |
| 标记完成 | 当所有标记任务都完成后,调用runtime.gcMarkDone方法,以结束标记阶段的工作。 | 将在后续【第二次STW】一节中讨论 |
标记完成,会重新进入STW,这里我们后面再分析,当前聚焦于扫描&标记。
标记协程被唤醒后,主线又重新拉回到gcBgMarkWorker方法中,此时会根据控制标记协程的CPU利用率一节中讨论的标记模式,调用gcDrain方法开始执行并发标记工作.
func gcBgMarkWorker() {
// 1.预生成标记协程一节已讨论
//...
for {
// 1.预生成标记协程一节已讨论
//...
systemstack(func() {
// 将我们的 goroutine 标记为可抢占状态,以便其堆栈可以被扫描。
// 这让两个标记工作者可以相互扫描(否则,它们将死锁)。
// 我们不能修改 G 堆栈上的任何内容。然而,标记工作者的堆栈收缩是禁用的,
// 因此读取 G 堆栈是安全的。
casgstatus(gp, _Grunning, _Gwaiting)
switch pp.gcMarkWorkerMode {
default:
throw("gcBgMarkWorker: unexpected gcMarkWorkerMode")
case gcMarkWorkerDedicatedMode:
// 先按照可抢占模式执行标记协程,倘若被抢占,则将抢占协程添加到全局队列中,之后再以不可抢占模式执行标记协程。
gcDrain(&pp.gcw, gcDrainUntilPreempt|gcDrainFlushBgCredit)
if gp.preempt {
// 我们被抢占了。这是一个有用的信号,可以将所有g
// 从运行队列中踢出,以便它可以在其他地方运行。
if drainQ, n := runqdrain(pp); n > 0 {
lock(&sched.lock)
globrunqputbatch(&drainQ, int32(n))
unlock(&sched.lock)
}
}
// 重新进入,这次没有抢占。
gcDrain(&pp.gcw, gcDrainFlushBgCredit)
case gcMarkWorkerFractionalMode:
gcDrain(&pp.gcw, gcDrainFractional|gcDrainUntilPreempt|gcDrainFlushBgCredit)
case gcMarkWorkerIdleMode:
gcDrain(&pp.gcw, gcDrainIdle|gcDrainUntilPreempt|gcDrainFlushBgCredit)
}
casgstatus(gp, _Gwaiting, _Grunning)
})
//...
}
}
可以看到都是继续调用了gcDrain函数,由它来扫描根和工作缓冲区中的对象,将灰色对象变黑,直到无法获得更多工作为止。
它可能在GC完成之前返回, 具体根据入参中传递的不同模式来决定;目的是为了平衡其他处理器的工作。
| 标记模式 | 说明 |
|---|---|
| gcDrainUntilPreempt | 当 Goroutine 的 preempt 字段被设置成 true 时返回 (If flags&gcDrainUntilPreempt != 0, gcDrain returns when g.preempt is set.) |
| gcDrainIdle | 调用 runtime.pollWork,当处理器上包含其他待执行 Goroutine 时返回; (If flags&gcDrainIdle != 0, gcDrain returns when there is other work to do.) |
| gcDrainFractional | 调用 runtime.pollFractionalWorkerExit,当 CPU 的占用率超过 fractionalUtilizationGoal 的 20% 时返回; (If flags&gcDrainFractional != 0, gcDrain self-preempts when pollFractionalWorkerExit() returns true. This implies gcDrainNoBlock.) |
| gcDrainFlushBgCredit | 调用 runtime.gcFlushBgCredit 计算后台完成的标记任务量以减少并发标记期间的辅助垃圾收集的用户程序的工作量; (If flags&gcDrainFlushBgCredit != 0, gcDrain flushes scan work credit to gcController.bgScanCredit every gcCreditSlack units of scan work.) |
标记主流程
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
//...
// 1. 在空闲模式(gcDrainIdle)和分时模式(gcDrainFractional)下,会提前设好检查函数(pollWork 和 pollFractionalWorkerExit)在执行下一个自我抢占检查之前的扫描工作量。
// 2. 标记根对象
//...
markroot(gcw, job, flushBgCredit)
//...
// 3. for循环标记堆对象,直到达到退出条件
for !(gp.preempt && (preemptible || atomic.Load(&sched.gcwaiting) != 0)) {
// 尽量保持全局队列上有可用的工作。我们过去常常检查是否有等待的工作者,
// 但最好是保持工作可用,而不是让工作者等待。在最坏的情况下,我们将进行
// O(log(_WorkbufSize)) 不必要的平衡。
if work.full == 0 {
gcw.balance()
}
// 4. 循环从gcw缓存队列中取出灰色对象,执行scanObject方法进行扫描标记
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// 刷新写屏障缓冲区;这可能会创建更多的工作。
wbBufFlush(nil, 0)
b = gcw.tryGet()
}
}
if b == 0 {
// 无法获得工作。
break
}
scanobject(b, gcw)
// 如果我们在本地积累了足够的背景扫描工作信誉,则将其刷新到全局账户中,
// 以便变异体辅助可以从中提取。
if gcw.heapScanWork >= gcCreditSlack {
//...
if checkWork <= 0 {
checkWork += drainCheckThreshold
if check != nil && check() {
break
}
}
}
}
//...
}
3.2.2.1 中止标记协程 #
对应于idle模式的check函数是pollwork,方法中判断P本地队列存在就绪的g或者存在就绪的网络写成,就会对当前标记协程进行中断:
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
//...
// 1. 在空闲模式(gcDrainIdle)和分时模式(gcDrainFractional)下,会提前设好检查函数(pollWork 和 pollFractionalWorkerExit)在执行下一个自我抢占检查之前的扫描工作量。
checkWork := int64(1<<63 - 1)
var check func() bool
if flags&(gcDrainIdle|gcDrainFractional) != 0 {
checkWork = initScanWork + drainCheckThreshold
if idle {
check = pollWork
} else if flags&gcDrainFractional != 0 {
check = pollFractionalWorkerExit
}
}
//...
}
func pollWork() bool {
if sched.runqsize != 0 {
return true
}
p := getg().m.p.ptr()
if !runqempty(p) {
return true
}
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && sched.lastpoll != 0 {
if list := netpoll(0); !list.empty() {
injectglist(&list)
return true
}
}
return false
}
对应于 fractional 模式的check函数是pollFractionalWorkerExit,倘若当前标记协程执行的时间比例大于 1.2 倍的 fractionalUtilizationGoal 阈值(3.4小节中设置),就会中止标记协程.
func pollFractionalWorkerExit() bool {
now := nanotime()
delta := now - gcController.markStartTime
if delta <= 0 {
return true
}
p := getg().m.p.ptr()
selfTime := p.gcFractionalMarkTime + (now - p.gcMarkWorkerStartTime)
return float64(selfTime)/float64(delta) > 1.2*gcController.fractionalUtilizationGoal
}
3.2.2.1 扫描根对象 #
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
//...
// 1. 在空闲模式(gcDrainIdle)和分时模式(gcDrainFractional)下,会提前设好检查函数(pollWork 和 pollFractionalWorkerExit)在执行下一个自我抢占检查之前的扫描工作量。
// 2. 标记根对象
if work.markrootNext < work.markrootJobs {
// 如果我们是可抢占的或者有人想要STW,则停止。
for !(gp.preempt && (preemptible || atomic.Load(&sched.gcwaiting) != 0)) {
//...
markroot(gcw, job, flushBgCredit)
if check != nil && check() {
goto done
}
}
}
//...
}
从gcDrain函数中继续可以看到,使用runtime.markroot扫描根对象,
主要有以下几项:
- .bss段内存中的未初始化全局变量
- .data段内存中的已初始化的变量
- span中的finalizer
- 协程栈
func markroot(gcw *gcWork, i uint32, flushBgCredit bool) int64 {
//...
switch {
//1. 处理已初始化的全局变量
case work.baseData <= i && i < work.baseBSS:
//...
workDone += markrootBlock(datap.data, datap.edata-datap.data, datap.gcdatamask.bytedata, gcw, int(i-work.baseData))
//...
//2. 处理未初始化的全局变量
case work.baseBSS <= i && i < work.baseSpans:
//...
workDone += markrootBlock(datap.bss, datap.ebss-datap.bss, datap.gcbssmask.bytedata, gcw, int(i-work.baseBSS))
//...
//3. 处理finalizer队列
case i == fixedRootFinalizers:
//...
scanblock(uintptr(unsafe.Pointer(&fb.fin[0])), cnt*unsafe.Sizeof(fb.fin[0]), &finptrmask[0], gcw, nil)
//...
//4. 释放已终止的g的栈
case i == fixedRootFreeGStacks:
systemstack(markrootFreeGStacks)
//5. 扫描mspan中的special
case work.baseSpans <= i && i < work.baseStacks:
markrootSpans(gcw, int(i-work.baseSpans))
default:
// ...
// 获取需要扫描的g
gp := work.stackRoots[i-work.baseStacks]
// ...
// 切回到 g0执行工作,扫描 g 的栈
systemstack(func() {
// ...
//6. 栈扫描
workDone += scanstack(gp, gcw)
// ...
})
}
// ...
return workDone
}
其中全局变量(已初始化/未初始化)主要由markrootBlock来承接,而它最终会调用scanblock函数。
func markrootBlock(b0, n0 uintptr, ptrmask0 *uint8, gcw *gcWork, shard int) int64 {
//...
scanblock(b, n, ptrmask, gcw, nil)
//...
}
同样栈上最终也会调用到scanblock函数。
func scanstack(gp *g, gcw *gcWork) int64 {
// ...
scanframe := func(frame *stkframe, unused unsafe.Pointer) bool {
scanframeworker(frame, &state, gcw)
return true
}
// ...
}
func scanframeworker(frame *stkframe, state *stackScanState, gcw *gcWork) {
// ...
// 扫描局部变量
if locals.n > 0 {
//...
scanblock(frame.varp-size, size, locals.bytedata, gcw, state)
}
// 扫描函数参数
if args.n > 0 {
scanblock(frame.argp, uintptr(args.n)*goarch.PtrSize, args.bytedata, gcw, state)
}
// ...
}
接下来我们来细看下scanblock函数:
func scanblock(b0, n0 uintptr, ptrmask *uint8, gcw *gcWork, stk *stackScanState) {
// 使用原始参数的本地副本,便于调试时查看原始块的基址和范围
b := b0
n := n0
for i := uintptr(0); i < n; {
// 获取下一个字的位图
bits := uint32(*addb(ptrmask, i/(goarch.PtrSize*8)))
if bits == 0 {
i += goarch.PtrSize * 8
continue
}
for j := 0; j < 8 && i < n; j++ {
if bits&1 != 0 {
// 与 scanobject 中的工作相同;参见那里的注释
p := *(*uintptr)(unsafe.Pointer(b + i))
if p != 0 {
if obj, span, objIndex := findObject(p, b, i); obj != 0 {
greyobject(obj, b, i, span, gcw, objIndex)
//...
}
}
bits >>= 1
i += goarch.PtrSize
}
}
}
ptrmask存储着位图信息, 用于指示哪些位置是指针,一个bit位对应了一个指针大小(8B)的位置的标识信息,指明当前位置是否是指针, 当指示的位置非指针(ptrmask中存储的是0),则直接跳过扫描,加速扫描的进度。
- 变量初始化:使用本地变量b和n来保存原始块的基址和长度,这样可以在调试时更容易查看这些值。
- 主循环:
- 外层循环通过i遍历整个内存块,步长为
goarch.PtrSize * 8。 - 内层循环通过j遍历每个字的位图,步长为
goarch.PtrSize。
- 位图处理,从位图中提取每个字的位信息bits:
- 如果bits为0,表示这一字没有指针,直接跳过。
- 如果bits不为0,进一步检查每个位是否为1,如果是,表示对应位置是指针。
当找到了指针对象,就进行标记工作。关于greyobject,在3.1 三色标记法一节已经进行过讨论了。
3.2.2.3 标记堆对象 #
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
//...
// 1. 在空闲模式(gcDrainIdle)和分时模式(gcDrainFractional)下,会提前设好检查函数(pollWork 和 pollFractionalWorkerExit)在执行下一个自我抢占检查之前的扫描工作量。
// 2. 标记根对象
// 3. for循环标记堆对象,直到达到退出条件
for !(gp.preempt && (preemptible || atomic.Load(&sched.gcwaiting) != 0)) {
//...
// 4. 循环从gcw缓存队列中取出灰色对象,执行scanObject方法进行扫描标记
//...
// 刷新写屏障缓冲区;这可能会创建更多的工作。
wbBufFlush(nil, 0)
scanobject(b, gcw)
// 如果我们在本地积累了足够的背景扫描工作信誉,则将其刷新到全局账户中,
//...
scanobject从入参(必须指向堆对象或对象片段的开始位置)开始扫描对象,将指针添加到gcw。
扫描过程中,通过heapArena中的bitmap记录的信息,加速遍历过程,并将遍历到的对象,将其置灰,并添加到队列中。
关于位图标记前面已有讨论,这里不再赘述。
func scanobject(b uintptr, gcw *gcWork) {
//...
// 找到 b 的位图信息和 b 处对象的大小。
//
// b 要么是对象的开始,要么指向对象片段的开始,
// 在这种情况下,我们会在下面计算扫描的大小。
hbits := heapBitsForAddr(b)
s := spanOfUnchecked(b)
n := s.elemsize
//...
var i uintptr
for i = 0; i < n; i, hbits = i+goarch.PtrSize, hbits.next() {
// 加载一次位图信息。
bits := hbits.bits()
if bits&bitScan == 0 {
break // 这个对象中没有更多指针
}
if bits&bitPointer == 0 {
continue // 不是指针
}
obj := *(*uintptr)(unsafe.Pointer(b + i))
// 此时我们已经提取了下一个可能的指针。
// 快速筛选出空指针和指向当前对象的指针。
if obj != 0 && obj-b >= n {
// 检查 obj 是否指向 Go 堆中,如果是,则标记对象。
// 注意,如果 obj 指向一个刚分配的堆对象,findObject 可能会失败,
// 因为与增加堆空间的操作存在竞争。在这种情况下,我们知道对象刚刚分配,因此会在分配时标记对象。
if obj, span, objIndex := findObject(obj, b, i); obj != 0 {
greyobject(obj, b, i, span, gcw, objIndex)
}
}
}
//...
}
置黑新分配对象 #
分配黑色对象:在垃圾收集期间分配内存时,将对象标记为黑色。(黑色对象表示已经扫描过的对象,在当前GC周期不会再次扫描)
当系统分配一块新的内存时,所有新分配的内存槽位都被初始化为nil,这意味着这些槽位中没有有效的指针。初始化为nil的目的是为了确保新分配的内存不会包含垃圾数据或悬空指针。
不需要扫描的原因为:所有新分配的内存槽位都被初始化为nil,我们可以确定这些槽位中不包含任何指针。因此,GC不需要对这些槽位进行扫描。这可以减少GC的工作量,提高内存分配和垃圾收集的效率。
// 在垃圾回收期间分配黑色对象。
// 所有槽位都持有 nil,因此不需要扫描。
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// ...
if gcphase != _GCoff {
gcmarknewobject(span, uintptr(x), size, scanSize)
}
// ...
}
gcmarknewobject将一个新分配的对象标记为黑色。待标记的对象必须不包含任何非nil的指针。
func gcmarknewobject(span *mspan, obj, size, scanSize uintptr) {
//...
// 标记对象。
objIndex := span.objIndex(obj)
span.markBitsForIndex(objIndex).setMarked()
// 标记跨度。
arena, pageIdx, pageMask := pageIndexOf(span.base())
//pageMarks指示哪些跨度(spans)上有任何已标记的对象。
// 像pageInUse 一样,只有每个跨度的第一个页面对应的位被使用。
if arena.pageMarks[pageIdx]&pageMask == 0 {
atomic.Or8(&arena.pageMarks[pageIdx], pageMask)
}
gcw := &getg().m.p.ptr().gcw
gcw.bytesMarked += uint64(size)
//...
}
辅助标记 #
在并发标记阶段,由于用户协程和标记协程共同工作,可能存在用户协程分配对象的速度快于标记协程标记对象的速度,从而导致标记阶段无法结束的极端场景。为了规避这个问题,Golang 引入了辅助标记策略,建立了一个兜底机制:在最坏情况下,一个用户协程分配了多少内存,就需要完成对应量的标记任务。
信用值的存取模型如下:
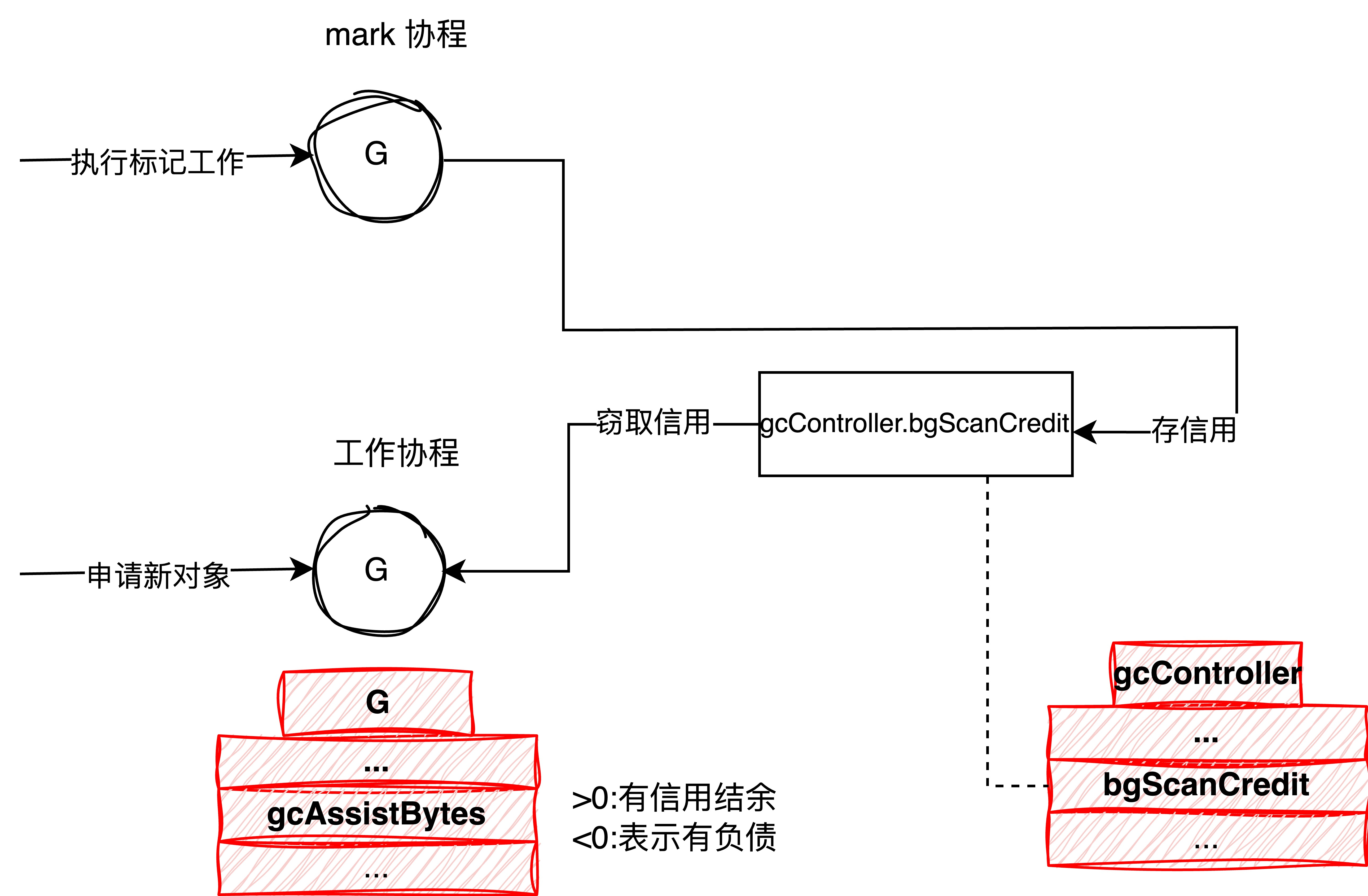
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// ...
var assistG *g
if gcBlackenEnabled != 0 {
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// 每个 g 会有资产
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
gcAssistAlloc(assistG)
}
}
}
func gcAssistAlloc(gp *g) {
// Step 1: 确定负债额度
debtBytes := -gp.gcAssistBytes
// Step 2: 计算预期需要扫描的大小
scanWork := debtBytes * assistWorkPerByte
// Step 3: 检查预期扫描工作量是否低于最小扫描工作量
if scanWork < gcOverAssistWork {
scanWork = gcOverAssistWork
}
// 后续代码:执行实际的扫描工作
// ...
}
- 信用兑换比率
这里详细解释下assistWorkPerByte和assistBytesPerWork:在 Go 的垃圾收集器(GC)中,辅助标记策略是确保用户协程分配内存时能够按预期完成相应的标记任务。两个关键比率 assistWorkPerByte 和 assistBytesPerWork 在这一过程中起到了重要作用。
- assistWorkPerByte
- 定义:assistWorkPerByte 是一个 float64 类型的值,表示每分配一字节内存空间应该相应地执行多少扫描工作。
- 意义:它是一个比率,用于计算在分配一定量的内存时需要完成的扫描工作量。
- 存取:尽管是 float64 类型,gcController 会将其转换为 uint64 进行原子性存取,以确保线程安全。
- assistBytesPerWork
- 定义:assistBytesPerWork 是 assistWorkPerByte 的倒数,表示完成一字节的扫描工作后可以分配多大的内存空间。
- 意义:它也是一个比率,用于计算在完成一定量的扫描工作后可以分配的内存量。
这两个比率在每轮垃圾收集开始时计算,并随着堆扫描的进度一起更新。
- 计算预期扫描工作量的步骤
- 确定负债额度
在 mallocgc 函数中,如果 gp.gcAssistBytes 小于 0,说明当前协程有标记负债,需要进行辅助标记。这时会调用 gcAssistAlloc 来执行辅助标记。
if gp.gcAssistBytes < 0 {
debtBytes := -gp.gcAssistBytes
}
这里,debtBytes 是负债额度,等于 gp.gcAssistBytes 的绝对值。
- 计算预期需要扫描的大小
预期需要扫描的大小等于 debtBytes 乘以 assist WorkPerByte。
scanWork := debtBytes * assistWorkPerByte
debtBytes:负债额度,表示需要补偿的内存分配量。 assistWorkPerByte:每分配一字节内存空间应该相应地做多少扫描工作,这是一个比率。
- 检查预期扫描工作量是否低于最小扫描工作量
如果预期的扫描工作量小于 gcOverAssist Work,则取 gcOverAssist Work 的值。gcOverAssist Work 是一个预定义的最小扫描工作量,目前被定义为 64KB。
if scanWork < gcOverAssistWork {
scanWork = gcOverAssistWork
}
gcOverAssistWork:最小扫描工作量,被定义为 64KB。
- 信用窃取
如果全局信用额度足够抵消当前协程的扫描工作量,那么当前协程就不需要进行实际的扫描任务。这在垃圾收集器(GC)的实现中非常重要,因为它可以提高内存分配和扫描工作的效率。 如果信用资产不够,则会通过systemstack方法切换至g0,并在gcAssistAlloc1方法内调用 gcDrainN方法,进行并发标记。
func gcAssistAlloc(gp *g) {
//...
// Step 4: 尝试从全局的可用资产中偷取信用额度
bgScanCredit := atomic.Loadint64(&gcController.bgScanCredit)
stolen := int64(0)
if bgScanCredit > 0 {
if bgScanCredit < scanWork {
stolen = bgScanCredit
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(stolen))
} else {
stolen = scanWork
gp.gcAssistBytes += debtBytes
}
atomic.Xaddint64(&gcController.bgScanCredit, -stolen)
scanWork -= stolen
// 全局资产够用,则无需辅助标记,直接返回
if scanWork == 0 {
return
}
}
//...
}
3.2.3 第二次STW #
让我们继续回到gcBgMarkWorker函数:
func gcBgMarkWorker() {
// 1.预生成标记协程一节已讨论
//...
for {
// 1.预生成标记协程一节已讨论
//...
// 2.标记协程
//...
// 3.标记终止
if incnwait == work.nproc && !gcMarkWorkAvailable(nil) {
// ...
gcMarkDone()
}
}
}
gcMarkDone函数的主要作用是确定是否已完成所有可达对象的标记,并在合适的时间点将GC状态从标记阶段转换到标记终止阶段。这个函数负责确保所有灰色对象(未完全标记的对象)都已被处理,并且没有新的灰色对象在此过程中产生。一旦确认所有对象都已被正确标记,它将进入标记终止阶段,准备进行垃圾回收。
func gcMarkDone() {
// 确保只有一个线程在运行
semacquire(&work.markDoneSema)
top:
// 重新检查过渡条件
//...
// 获取 worldsema 信号量
semacquire(&worldsema)
// 刷新所有本地缓冲区并收集flushedWork标志
//...
systemstack(func() {
gp := getg().m.curg
casgstatus(gp, _Grunning, _Gwaiting)
forEachP(func(_p_ *p) {
wbBufFlush1(_p_)
_p_.gcw.dispose()
if _p_.gcw.flushedWork {
atomic.Xadd(&gcMarkDoneFlushed, 1)
_p_.gcw.flushedWork = false
}
})
casgstatus(gp, _Gwaiting, _Grunning)
})
// 重新检查过渡条件
if (gcMarkDoneFlushed != 0) {
semrelease(&worldsema)
goto top
}
// 进入标记终止阶段
//...
//第二次STW
systemstack(stopTheWorldWithSema)
// 检查是否有残留工作需要处理,如果有,返回,重新STW
//...
// 禁用GC助力和后台工作线程
atomic.Store(&gcBlackenEnabled, 0)
// 唤醒所有被阻塞的线程
gcWakeAllAssists()
//...
// 允许用户goroutine重新执行
schedEnableUser(true)
// 结束GC周期并进行标记终止
//...
gcMarkTermination(nextTriggerRatio)
}
- 确保单线程执行并检查过渡条件
- 首先,通过获取信号量markDoneSema,确保只有一个线程能够执行标记完成的操作,避免竞争条件。然后,检查是否满足从标记阶段过渡到标记终止阶段的条件。如果条件不满足,释放markDoneSema信号量并返回。
- 刷新本地工作缓冲区并处理残留工作
- 通过调用forEachP函数,遍历所有处理器(P),刷新写屏障缓冲区和GC工作缓冲区。如果发现有新的工作被刷新出来,增加gcMarkDoneFlushed计数。然后,重新检查条件,如果有新的灰色对象被发现,则释放worldsema信号量并跳回到top,重新开始检查。
- 进入标记终止阶段并结束GC周期
- 记录当前时间,更新相关的工作变量,并调用stopTheWorldWithSema停止所有用户goroutine的执行。再次检查所有处理器的GC工作缓冲区,如果发现有残留工作,则重新启动世界并返回顶部重新检查。禁唤醒所有被阻塞的助力线程,并允许用户goroutine重新执行。最后,进行标记终止。
标记终止 #
gcMarkTermination方法包括几个核心步骤:
- 设置GC标志为:标记终止(
_GCmarktermination)。 - 设置GC标志为:标记关闭(
_GCoff)。 - 唤醒后台清扫协程,开始进行标记清扫(
gcSweep函数)。 - 切换至g0,执行gcControllerCommit方法,设置触发下一轮GC的内存阈值。
- 切换至g0,调用startTheWorldWithSema方法,恢复运行。
func gcMarkTermination() {
//1.设置GC标志为:标记终止
setGCPhase(_GCmarktermination)
//...
systemstack(func() {
//...
//2.设置GC标志为:标记关闭
setGCPhase(_GCoff)
//3.唤醒后台清扫协程,开始进行标记清扫
gcSweep(work.mode)
})
//4.提交下一轮GC的内存阈值
systemstack(gcControllerCommit)
//...
// 第二次STW后【start the world】
systemstack(func() { startTheWorldWithSema(true) })
//...
}
3.2.3.1.唤醒清扫协程 #
func gcSweep(mode gcMode) {
//...
// Background sweep.
lock(&sweep.lock)
if sweep.parked {
weep.parked = false
ready(sweep.g, 0, true)
}
unlock(&sweep.lock)
}
func main() {
// ...
gcenable()
// ...
}
func gcenable() {
// ...
go bgsweep(c)
<-c
// ...
}
func bgsweep(c chan int) {
// 1. 获取g对象存入sweep中
sweep.g = getg()
lockInit(&sweep.lock, lockRankSweep)
lock(&sweep.lock)
sweep.parked = true
c <- 1
// 2. 进行休眠
goparkunlock(&sweep.lock, waitReasonGCSweepWait, traceEvGoBlock, 1)
// 3. 唤醒后继续执行
for {
// 3.1. 进行循环中持续清扫对象
for sweepone() != ^uintptr(0) {
sweep.nbgsweep++
// 3.2. 每轮完成一个mspan的清扫工作后调用Gosched方法,主动让渡P的执行权
Gosched()
}
//...
}
}
3.2.4 清扫阶段 #
记得是还未清扫完的msapn是不会进行分配的,存放在mcenter中的dirty spanSet中
3.2.4.1. 清扫工作 #
sweepone方法每次清扫一个协程,清扫逻辑核心位于sweepLocked.sweep方法中,正是将mspan的gcmarkBits赋给allocBits,并创建出一个空白的bitmap作为新的gcmarkBits。
func sweepone() uintptr {
// ...
sl := sweep.active.begin()
// ...
for {
// 查找到一个待清扫的 mspan
s := mheap_.nextSpanForSweep()
// ...
if s, ok := sl.tryAcquire(s); ok {
npages = s.npages
// 对一个mspan进行清扫!!!
if s.sweep(false) {
// 增加信用值
mheap_.reclaimCredit.Add(npages)
} else {
npages = 0
}
break
}
}
sweep.active.end(sl)
// ...
return npages
}
func (sl *sweepLocked) sweep(preserve bool) bool {
//...
s.allocCount = nalloc
s.freeindex = 0 // 设置指向下一个空闲对象的索引为0
s.freeIndexForScan = 0
//...
// gcmarkBits赋给allocBits
// 生成新的gcmarkBits,为下一次GC做准备
s.allocBits = s.gcmarkBits
s.gcmarkBits = newMarkBits(s.nelems)
// Initialize alloc bits cache.
s.refillAllocCache(0)
// ...
}
其中设置指向下一个空闲对象的索引为0(s.freeindex = 0),后续可配合alloc,来找到下一个空闲的对象索引(具体可参见内存管理一章的mspan.nextFreeIndex()函数)。
刷新本地工作缓冲区并处理残留工作
进入标记终止阶段并结束GC周期
FQA #
p的个数是固定的吗,可以比机器CPU个数多吗
知道为什么一个gcWorker一个p了,因为gcWorker不会被抢占,它会一直占有一个p?
如果有多个P,那么会不会存在有一个p一直不回被执行的?
新申请的对象是标记为黑色还是标记为灰色呢?
为什么gc也要扫描栈,不是都在堆上面吗? #
因为堆上的地址,可能保存在栈上某个变量里,所以需要扫描。
混合写屏障 #
问:我就是觉得混合写屏障好像也没法 解决重新扫描栈的问题
现在有 A, B, C三个对象,A(黑色,栈上),B(灰色,栈上),C(白色,堆上); 当前引用关系是:
A(黑) -> nil
B(灰) -> C(白)
现在应用程序赋值修改,把A指向C:
A(黑) -> C(白)
B(灰) -> nil
由于A,B是栈上的对象,栈上对象赋值这里可是没有写屏障的;那么岂不是黑色对象指向白色对象了,C会回收了,就悬挂指针了?
答:Goroutine 栈扫描的过程需要 STW,所以你描述的这种状况是不存在的,栈上的对象要么全白要么全黑
- 你说的“栈上的对象要么全白,要么全黑“ ,这个只是对一个 goroutine 栈来说的(golang 暂停业务扫描栈也是一个一个来的)。如果场景是 A 在 Goroutine1,B在Goroutine2呢?这种情况就是A是黑色,B是白色或者灰色。这样会不会就有我说的原本那个问题呢?
- 除了从一个Goroutine通过chan发送/生成一个新Goroutine
- 如果两个Goroutine 栈只要有一个是灰色的,那么就会有
shade(ptr)- 新生成的Goroutine栈都是黑色的(由前面的条件保证),如果父Goroutine是灰色的,那么需使用
shade(ptr)
Golang中GC支持增量与并发式回收怎么理解 #
增量和并发,一个是横向一个是纵向,gc与mutator交替与运行。
- 横向:增量垃圾收集(增量地标记和清除垃圾,降低应用程序暂停的最长时间)
- 纵向:并发垃圾收集(利用多核的计算资源,在用户程序执行时并发标记和清除垃圾)
- 因为增量和并发两种方式都可以与用户程序交替运行,所以我们需要使用屏障技术保证垃圾收集的正确性.
为什么要使用混合写屏障 #
使用混合写屏障的原因是缩短gc暂停的时间。
- 因为栈上使用写屏障,会导致耗时太多。但是如果栈上不使用写屏障,等到第二次STW重新扫描栈空间,goroutine数目多,需要扫描的stack耗时也多。
忽略协程栈的写屏障;其他的使用删除写屏障,插入写屏障。
为什么需要STW #
如果没有任何STW的时间,也就是说垃圾回收程序与用户程序完全并发执行,其代价与实现难度可能都会高于短暂的STW。例如标记——清扫回收器中,若完全抛弃STW,那么垃圾回收开始的消息便很难准确及时地通知到所有线程,可能导致某些线程开启写屏障的动作有所延迟而无法保障双方执行的正确性。
为什么清扫阶段不需要屏障了呢? #
当标记完成了,那么它白色的对象都是不可达的对象,是可以删除的对象,程序不可能再找到已经不可达的对象。所以放心的清除。
并发GC如何缓解内存分配压力? #
借贷偿还机制。也可以偷。
总结 #
为什么golang需要GC #
what: #
- gc主要是释放那些不再需要的分配在堆(heap)上的数据
why: #
- 降低人的心智负担,从堆(heap)中申请的内存,不需要手动的释放。
how: #
- 一般判断对象是否存活是使用:是把可达性近视的认为存活性.
- 可把栈(stack),数据段(data segment、 bss)的数据对象作为root