数据结构 #
- 这些数据结构的底层是怎么实现的,比如array,它就是一个指针,指向第一个元素的地址.
- 然后就是一个细节,如果要实现这个数据结构的一些功能,比如chan读写,map的添加删除等,它们是怎么利用数据结构里面底层的field来实现这些功能?
引用 #
通常意义上来说,引用就是某块内存的别名, 我们常常拿指针与引用进行比较, 那么看看引用在底层是怎么实现的:
一种是c++里的引用实现,它其实是一个语法糖,经过编译器编译后,汇编代码引用就是指针,只不过是const指针,初始化的时候就需要赋值,且以后不能再更改[ c++里的引用实现;且两者地址相同。 特别说明由于引用只是指针包装, 也存在风险:
int *a = new int;
int &b = *a;
delete a;
b = 12; // 对已经释放的内存解引用
另-种是用结构体来包装一层,它的里面是实际内容的指针
type slice struct {
array unsafe.Pointer
len int
cap int
}
string #
string类型的底层结构.它的大小是几个字节?
指针和字节大小

0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
package main
import (
"fmt"
"reflect"
"unicode/utf8"
"unsafe"
)
func String2Bytes(s string) []byte {
sh := (*reflect.StringHeader)(unsafe.Pointer(&s))
bh := reflect.SliceHeader{
Data: sh.Data,
Len: sh.Len,
Cap: sh.Len,
}
return *(*[]byte)(unsafe.Pointer(&bh))
}
func Bytes2String(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
func main(){
var str = "hello 就是"
fmt.Println("--->", len(str))
fmt.Println("--->", len([]rune(str)))
// 报错cannot convert str (type string) to type []int64
//fmt.Println("--->", len([]int64(str)))
//golang中的unicode/utf8包提供了用utf-8获取长度的方法
fmt.Println("RuneCountInString:", utf8.RuneCountInString(str))
}
/*
string 的底层就是uint8的数组指针+长度
预期想得到一个字符串的长度而不是字符串底层占得字节长度:
1。 utf8.RuneCountInString()函数
2。 []rune(stringxxx) or []int32(stringxxx)
*/
单引号 #
单引号,表示byte类型或rune类型,对应 uint8和int32类型,默认是 rune 类型。byte用来强调数据是raw data,而不是数字;而rune用来表示Unicode的code point。
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
//String in double quotes
x := "tit\nfor\ttat"
fmt.Println("Priting String in Double Quotes:")
fmt.Printf("x is: %s\n", x)
//String in back quotes
y := `tit\nfor\ttat`
fmt.Println("\nPriting String in Back Quotes:")
fmt.Printf("y is: %s\n", y)
//Declaring a byte with single quotes
var b byte = 'a'
fmt.Println("\nPriting Byte:")
//Print Size, Type and Character
fmt.Printf("Size: %d\nType: %s\nCharacter: %c\n", unsafe.Sizeof(b), reflect.TypeOf(b), b)
//Declaring a rune with single quotes
r := '£'
fmt.Println("\nPriting Rune:")
//Print Size, Type, CodePoint and Character
fmt.Printf("Size: %d\nType: %s\nUnicode CodePoint: %U\nCharacter: %c\n", unsafe.Sizeof(r), reflect.TypeOf(r), r, r)
//Below will raise a compiler error - invalid character literal (more than one character)
//r = 'ab'
}
slice和数组的异同 #
Go中有两种取子切片的语法形式(假设baseContainer是一个切片或者数组):
baseContainer[low : high] // 双下标形式
baseContainer[low : high : max] // 三下标形式
上面所示的双下标形式等价于下面的三下标形式:baseContainer[low : high : cap(baseContainer)]
子切片表达式的结果切片的长度为high - low、容量为max - low。
golang数组是一个指向数组头地址的指针,但是如果你引用超过数组的长度,它会编译不通过.
- 如果使用reflect来
reflect.ValueOf(array).Index(out_of_range_index)它会在运行时panic(我猜时因为interface{}中_type的类型指明数组的大小是多少,所以会有一个判断.)
type arraytype struct {
typ _type
elem *_type
slice *_type
len uintptr
}
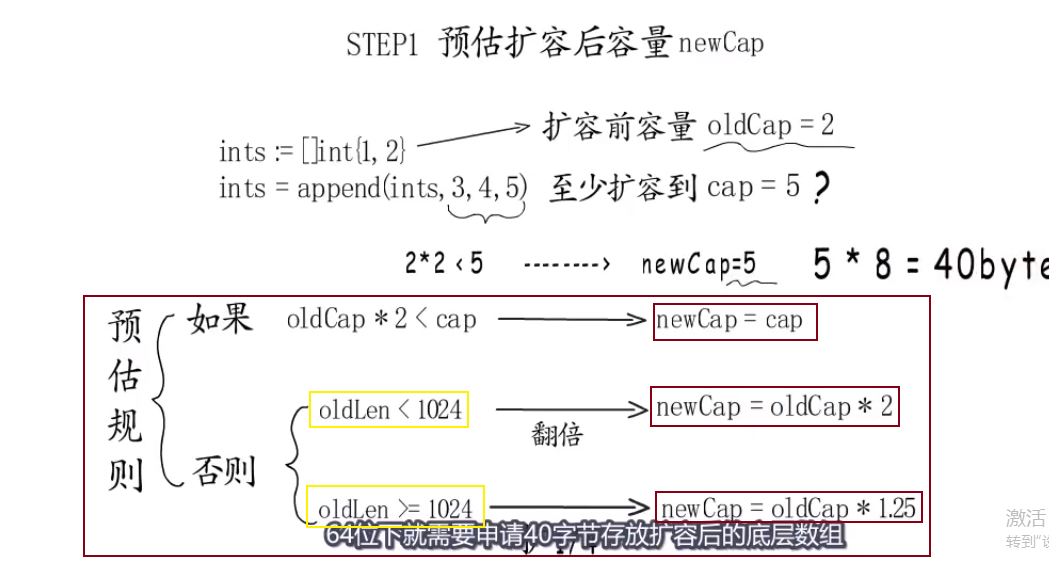
slice的自动扩容后的大小是多少? #
分三步来判断:
var newCap int
if oldCap*2<nowNeedCap{
newCap = nowNeedCap
}else{
if oldCap<1024 {
newCap =oldCap*2
}else{
newCap =oldCap*1.25
}
}
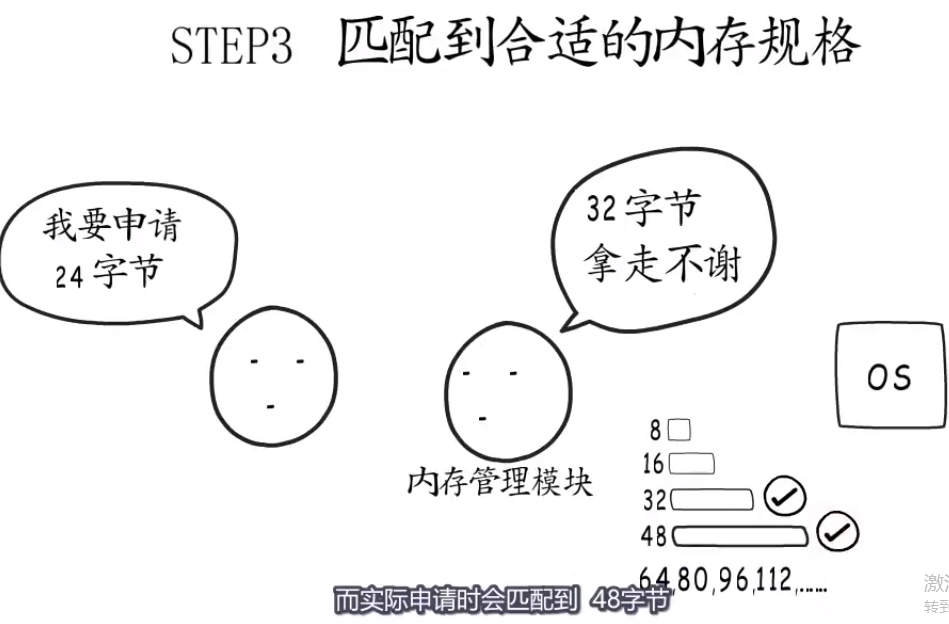
realNewCap := compare(内存管理模块的细分大小, newCap*EveryElementSize)

延伸 #
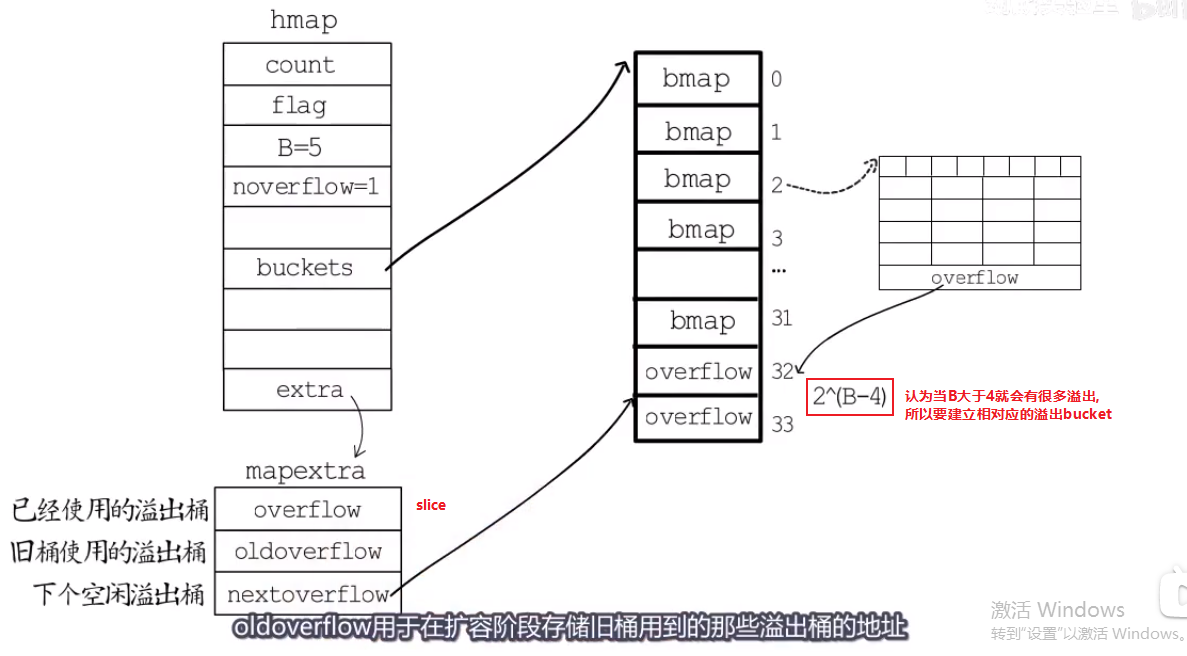
map #
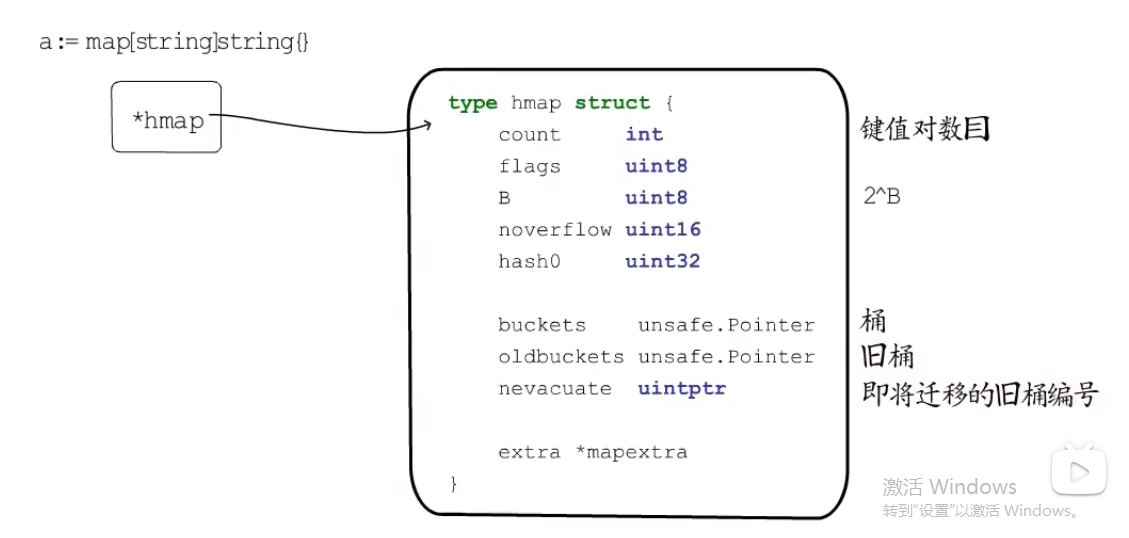
- map的底层是哈希表
- 哈希表的得到buctet的位置一般通过取模,与运算法
- hash%m
- hash&(m-1) //其中m一定要是2的整数倍,然后它减一,才会使它的后面的值都是1.否则就会导致低位buctet不会被选中的情况.
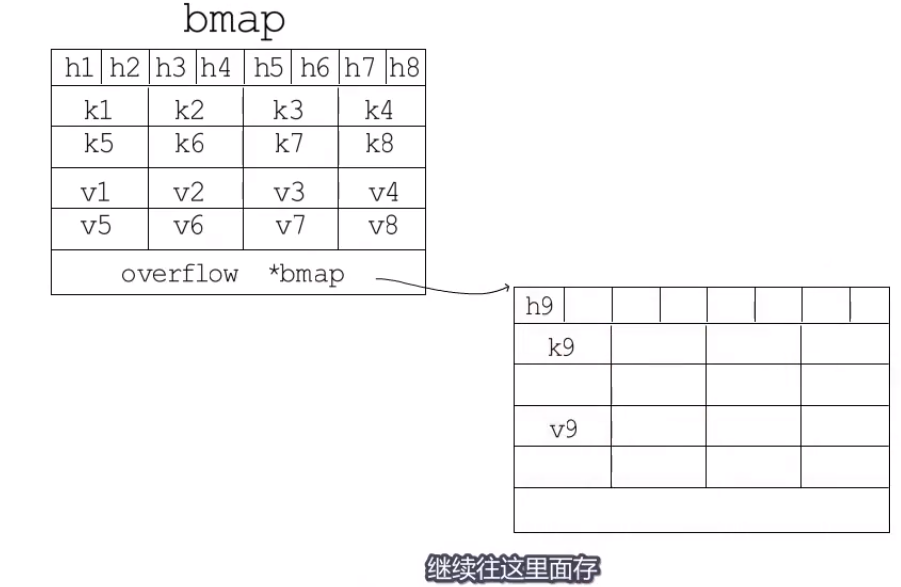
- 哈希冲突
- 开放寻址法
- 拉链法
- 跳表
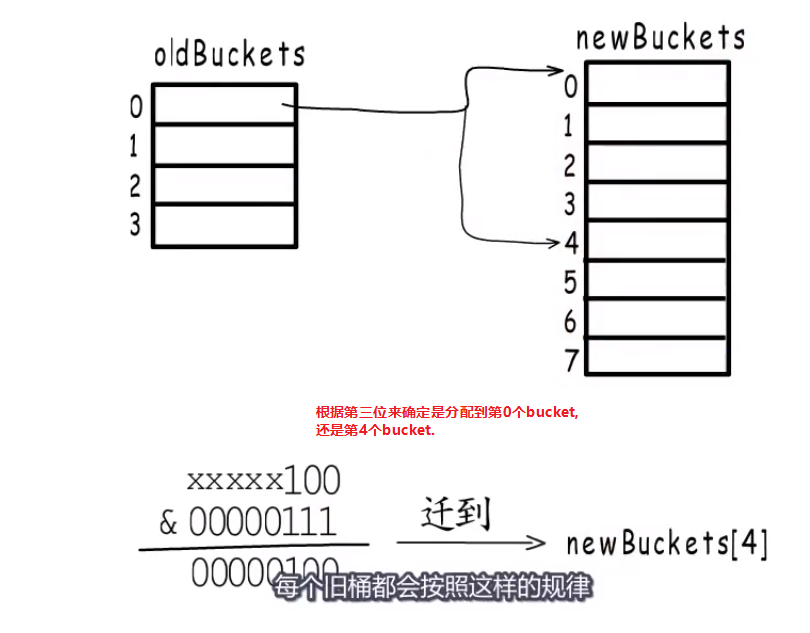
- 建立新bucket,慢慢迁移到新bucket.
- 哈希表的得到buctet的位置一般通过取模,与运算法
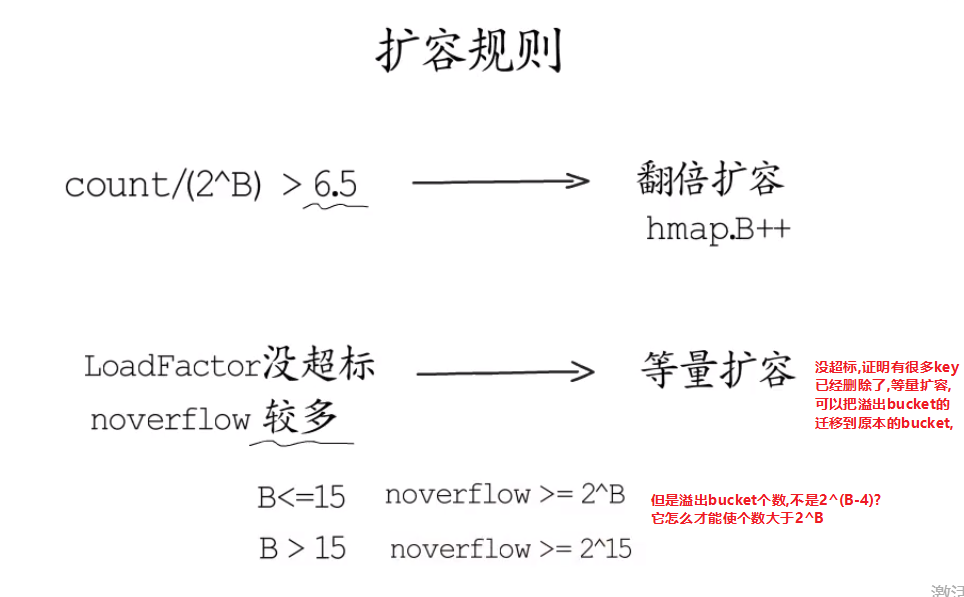
哈希扩容 #
扩容规则 #
struct和内存对齐 #
懂得内存为什么要对齐,如果不对齐会怎么样?
- 不对齐,可能从内存中读一个数据需要读两次,因为总线的原因
所以看一个类型的内存对齐,总的原则是不要读两次,尽量不要浪费内存.
- 比如32位(4byte) 下:
- 小于4byte的类型以他们自己的类型长度为内存对齐.
- 大于等于4byte以4byte.
- 一个struct类型,他的内存对齐为里面field中最大的那个.
- 比如32位(4byte) 下:
判断一个struct在内存中占用的字节数,
- 先按照它的各个field以struct的开始地址作为0,开始一个个排好,
- 最后要符合这个struct类型的内存对齐.
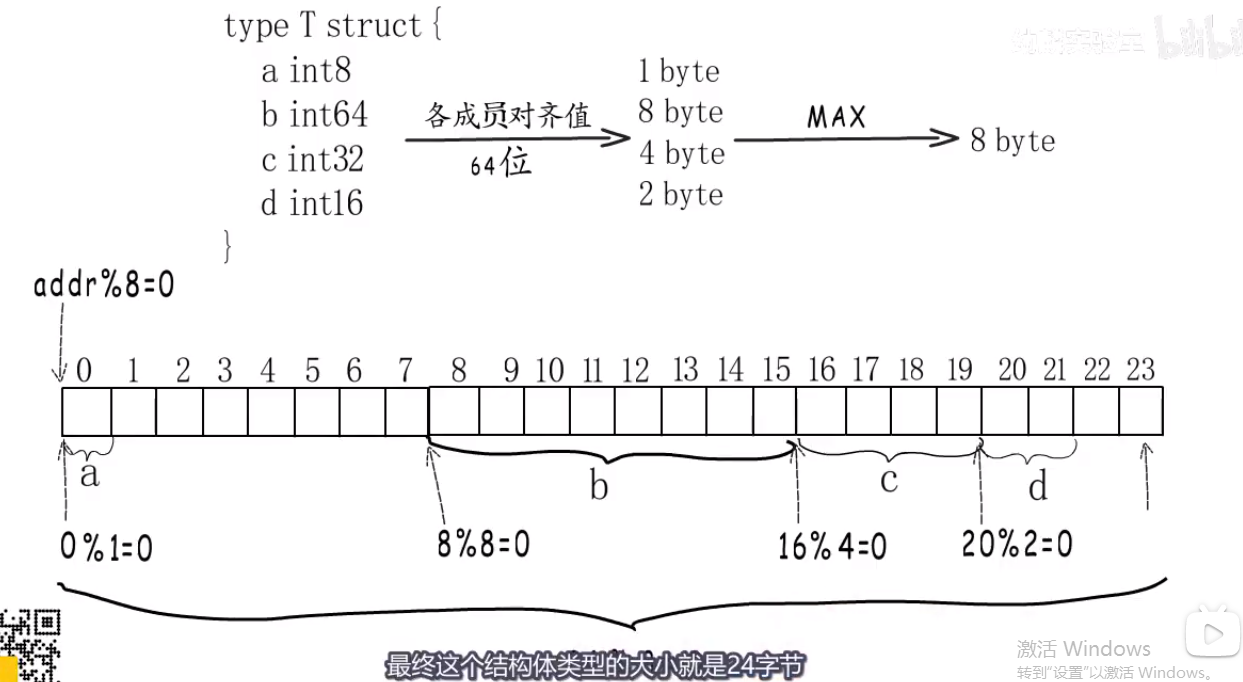
- test
type T1 struct {
f1 int8 // 1 byte
f2 int64 // 8 bytes
f3 int32 // 4 bytes
}
- 24 byte
chan #
‘‘里面的是chan的状态(eg: 一个零值nil通道;一个非零值但已关闭的通道)
‘空’读写阻塞-关闭恐慌; ‘关闭’读为0-关闭写恐慌. 如果是有缓存的chan已关闭,且现在缓存不为空,读正常得到数据 1
what: 从外部看进来.
- 不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存(即通信顺序进程(Communicating sequential processes,CSP))
|thread A|--------[memory]--------|thread B| |goroutine A|-----[channel]-------|goroutine B|- 先进先出
(FIFO:first in first out)数据队列- 可以把一个通道看作是在一个程序内部的一个先进先出(FIFO:first in first out)数据队列。 一些协程可以向此通道发送数据,另外一些协程可以从此通道接收数据。
- 有锁管道
- Channel是一个用于同步和通信的有锁队列,使用互斥锁解决程序中可能存在的线程竞争问题是很常见的,我们能很容易地实现有锁队列。
- CAS实现的无锁Channel没有提供先进先出的特性,所以该提案暂时也被搁浅了.
why: 内部结构细节.
- 结构
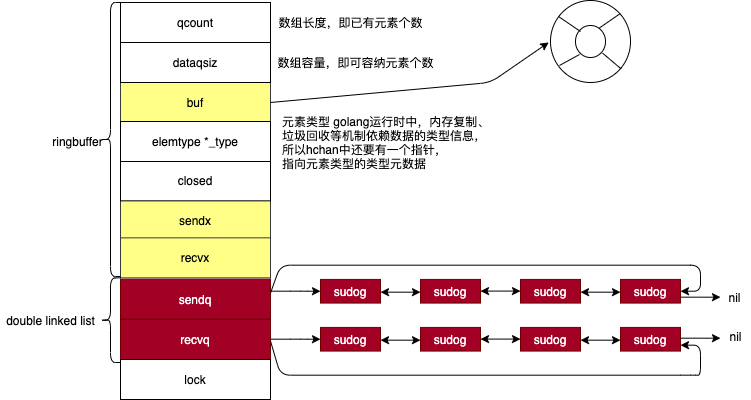
type hchan struct { qcount uint // - 数组长度,即已有元素个数 dataqsiz uint // - 数组容量,即可容纳元素个数 buf unsafe.Pointer // - 数组地址 elemsize uint16 // - 元素大小 closed uint32 elemtype *_type // 元素类型 golang运行时中,内存复制、垃圾回收等机制依赖数据的类型信息,所以hchan中还要有一个指针,指向元素类型的类型元数据 sendx uint // - 下一次写下标位置 recvx uint // - 下一次读下标位置 recvq waitq // 读等待队列 sendq waitq // 写等待队列 lock mutex } type waitq struct { first *sudog last *sudog }前面有
-的就是无缓冲chan不需要的字段。 sudog- 结构
how: chan的实践,一般用它来干什么?
- 五种操作:
close(ch)ch <- v<-chv = <-chv, sentBeforeClosed = <-ch
cap(ch)len(ch)
- 五种操作:
https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-channel/#fnref:12
https://golang.design/under-the-hood/zh-cn/part1basic/ch03lang/chan/#select- https://docs.google.com/presentation/d/18_9LcMc8u93aITZ6DqeUfRvOcHQYj2gwxhskf0XPX2U/edit#slide=id.g5ea99f63e9_0_26
error.Unwrap #
- 通过消除错误来消除错误处理
- 错误只处理一次
type errWriter struct {
w io.Writer
err error
}
func (ew *errWriter) write(buf []byte) {
if ew.err != nil {
return
}
_, ew.err = ew.w.Write(buf)
}
ew := &errWriter{w: fd}
ew.write(p0[a:b])
ew.write(p1[c:d])
ew.write(p2[e:f])
// and so on
if ew.err != nil {
return ew.err
}
- 将错误视为不透明的值对于生成松散耦合的软件很重要,所以如果对错误值所做的唯一事情是如下两个方面的话,则原始错误是什么类型就无关紧要了。
- 检查是否为 nil
- 打印或记录日志
- 但是,在某些场景,您确实需要恢复原始错误, 然后再判断的场景吗。
- 向错误添加上下文
fmt.Errorf
防止原始的错误类型被掩盖
error.Unwrap
错误发生一般是从外部,比如数据库,缓存,其他调用第三方导致的。
[一般有error code] ---来源---> [转换成中间值] ---去向---> [最后变成输出给外面的error code AND error message]
其中中间值是在自己系统中统一的,只要来源到这个系统的,都要先把错误码转为系统的中间值.
跟类型相关 #
- 需要思考类型在内存中是怎么表示的?
类型系统 #
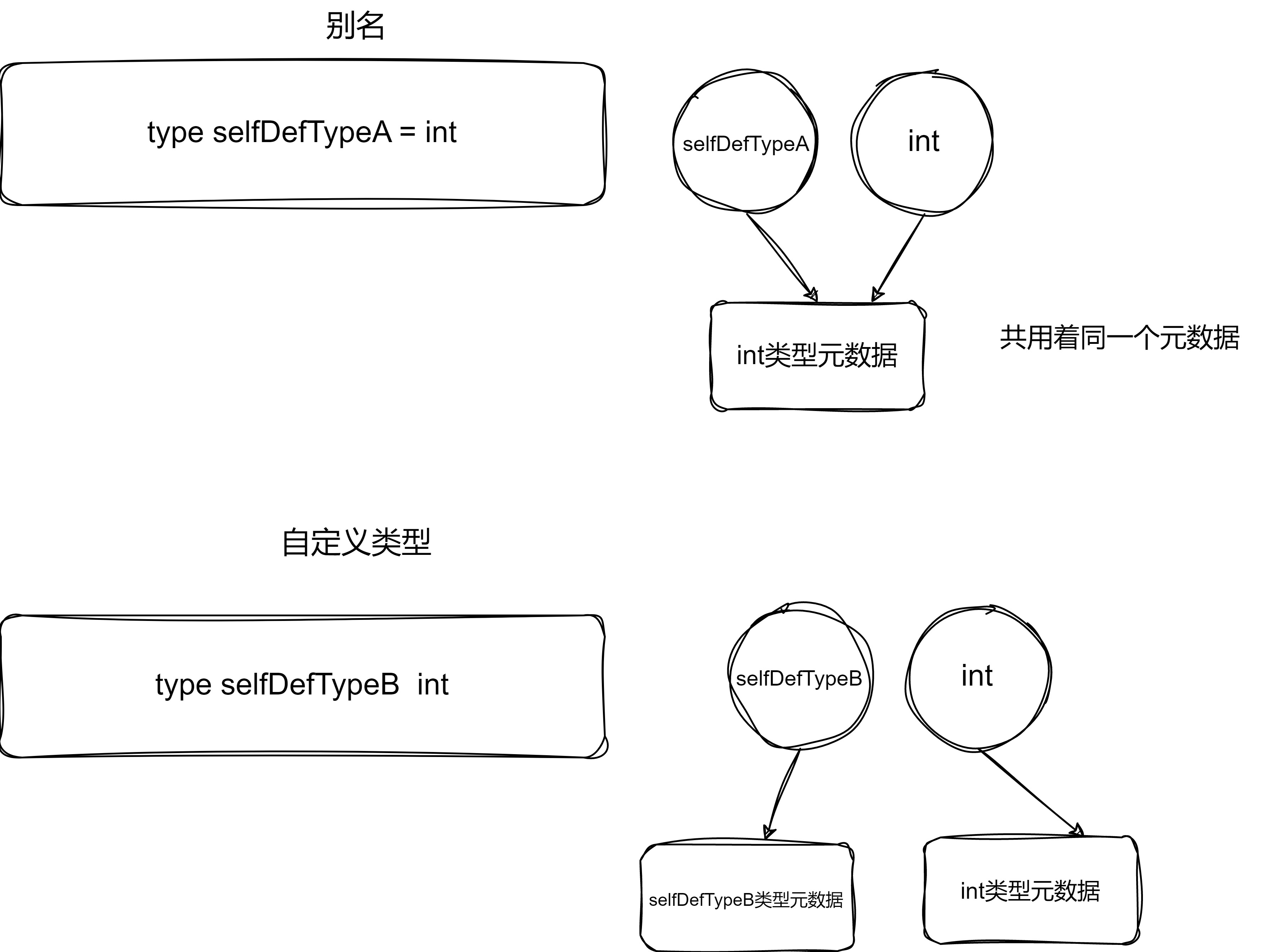
package main
import "fmt"
type selfDefTypeA = int
type selfDefTypeB int
func testAnotherName() {
var a1 selfDefTypeA
var a2 int
if a1 == a2 {
fmt.Println("selfDefTypeA is same with int")
}
}
// func testSelfDefineType() {
// var b1 selfDefTypeB
// var b2 int
// if b1 == b2 { // 编译不通过:invalid operation: b1 == b2 (mismatched types selfDefTypeB and int)
// fmt.Println("selfDefTypeB is same with int")
// }
// }
func main() {
testAnotherName()
//testSelfDefineType()
}
type mType struct{
x int64
}
func (mType) Method(){
}
var mObject mType
- 我们知道mObject内存布局代表的是一块内存,有8个字节,那么mObject怎么调用
mObject.Method()?mObject.Method()—>Method(mObject)调用方法,就是调用函数,对象自己当作第一个参数,但是这仅仅是在编译阶段,编译器可以进行转换,- 但是为了支持在运行阶段的语言特性,比如反射,接口动态派发、类型断言,所以编译器会给每种类型生成对应的类型描述信息写入可执行文件,这些类型描述信息就是类型元数据,方便在运行时操作.
底层类型结构 #
底层类型大致可以分为两类:一类是基本数据结构,一类是自定义的数据结构。
- 其中
_typetype _type struct - 其中
uncommontypetype uncommontype struct
基本数据结构底层表示 #
type structtype struct {
typ _type
pkgPath name
fields []structfield
}
type slicetype struct {
typ _type
elem *_type
}
type arraytype struct {
typ _type
elem *_type
slice *_type
len uintptr
}
type functype struct {
typ _type
inCount uint16
outCount uint16
}
type ptrtype struct {
typ _type
elem *_type
}
type chantype struct {
typ _type
elem *_type
dir uintptr
}
自定义数据结构底层表示 #
type myslice []string
func (ms myslice) Len(){
fmt.Println(len(ms))
}
func (ms myslice) Cap(){
fmt.Println(cap(ms))
}
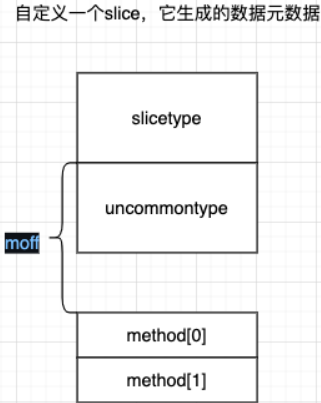
type slicetype struct {
typ _type
elem *_type
}
rune与int32就是别名关系. // TODO 如何比较它们是否相等?
跟函数定义的结构相关 #
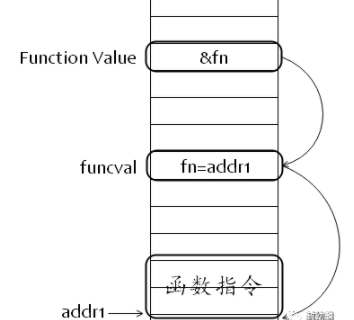
Function Value本质上是一个指针,却不直接指向函数指令入口,而是指向runtime.funcval结构体,然后再由这个结构体来指向函数指令入口。- 为了闭包.
type funcval struct {
fn uintptr
}
函数调用栈细节 #

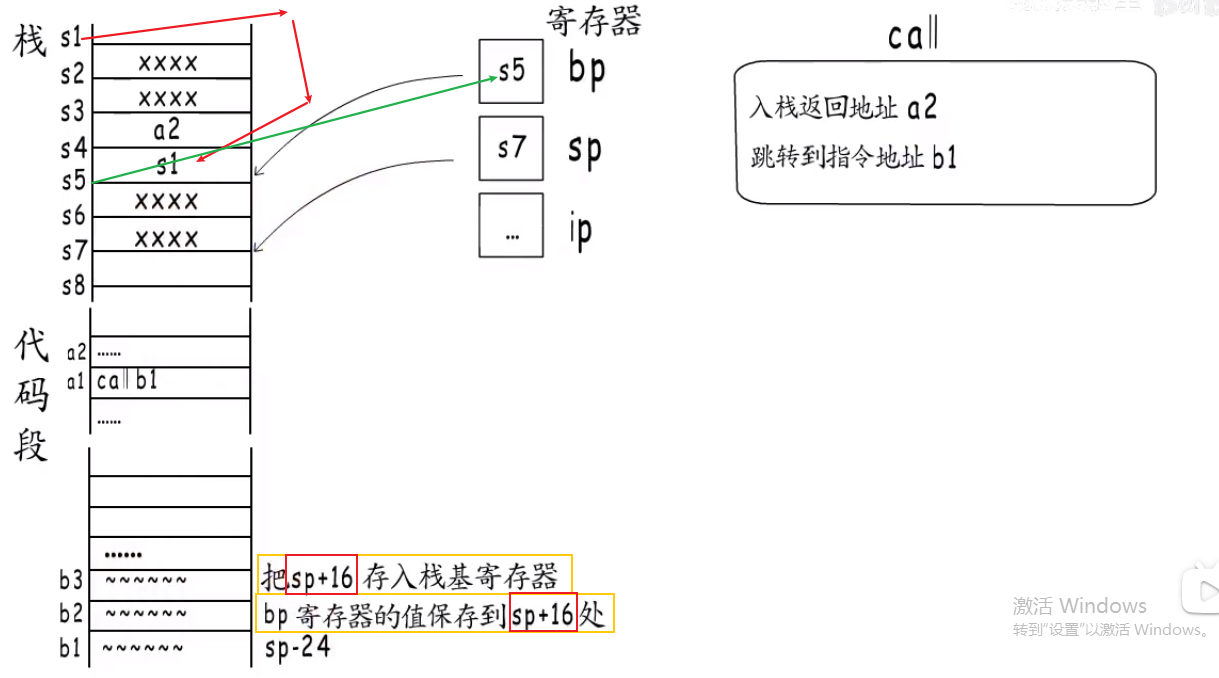
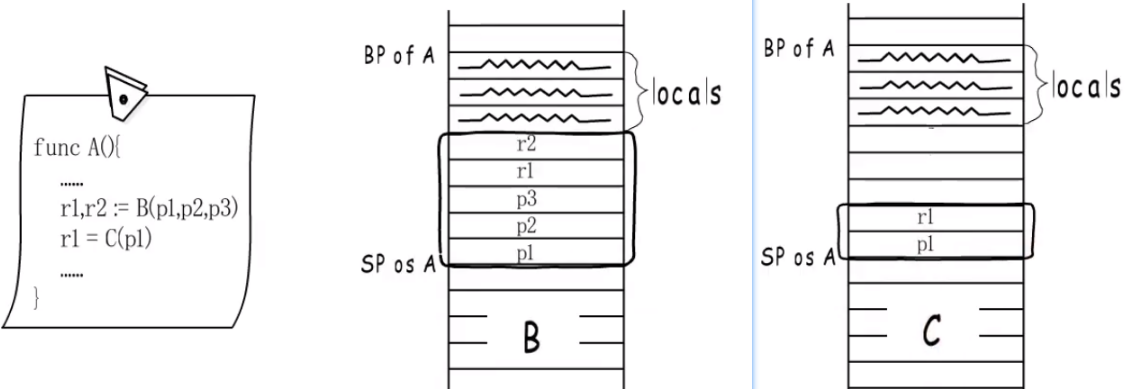
- 为什么被调用函数, 改变不了caller的传给callee的参数?
- 如果一个函数调用几个函数,且他们的形参个数不一, 大小不一, 那么这个caller的栈大小,是:
自己的参数+最大(参数字节和)的callee的值.
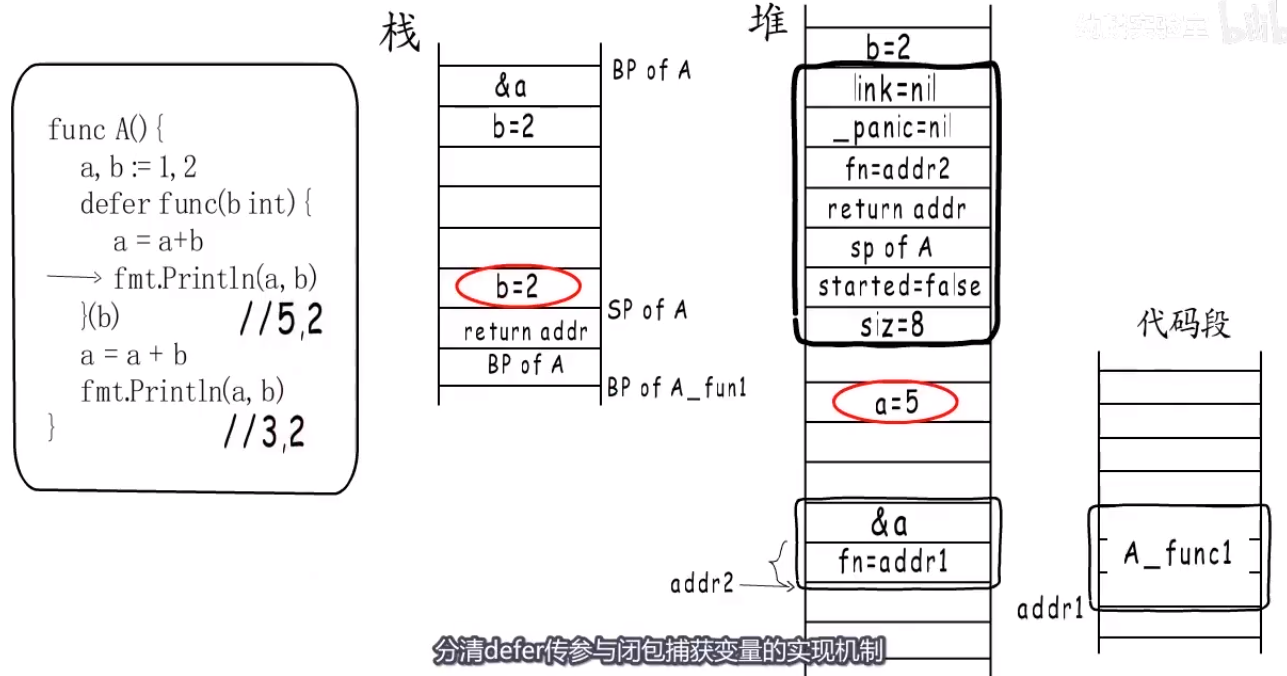
闭包 #
- what:在内存中怎么表示的
- 闭包有自由变量(函数外定义,函数内被引用).
- go语言里面返回一个闭包函数其实就是:一个funcval结构体加上捕获的变量.
- 只是如果这个变量在赋给初值以后没有再改变,与后面又被改变两种情况.
- why:
- how:
- 通过有捕获列表的Function Value实现.
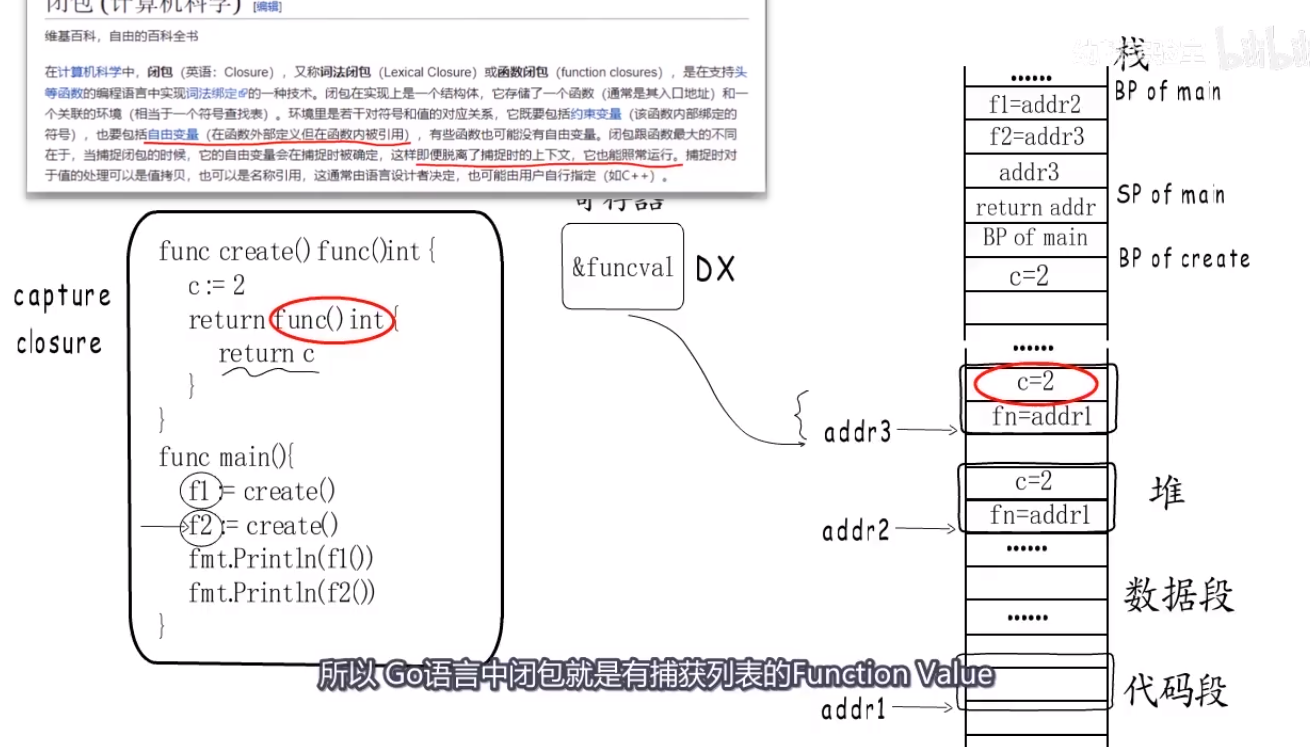
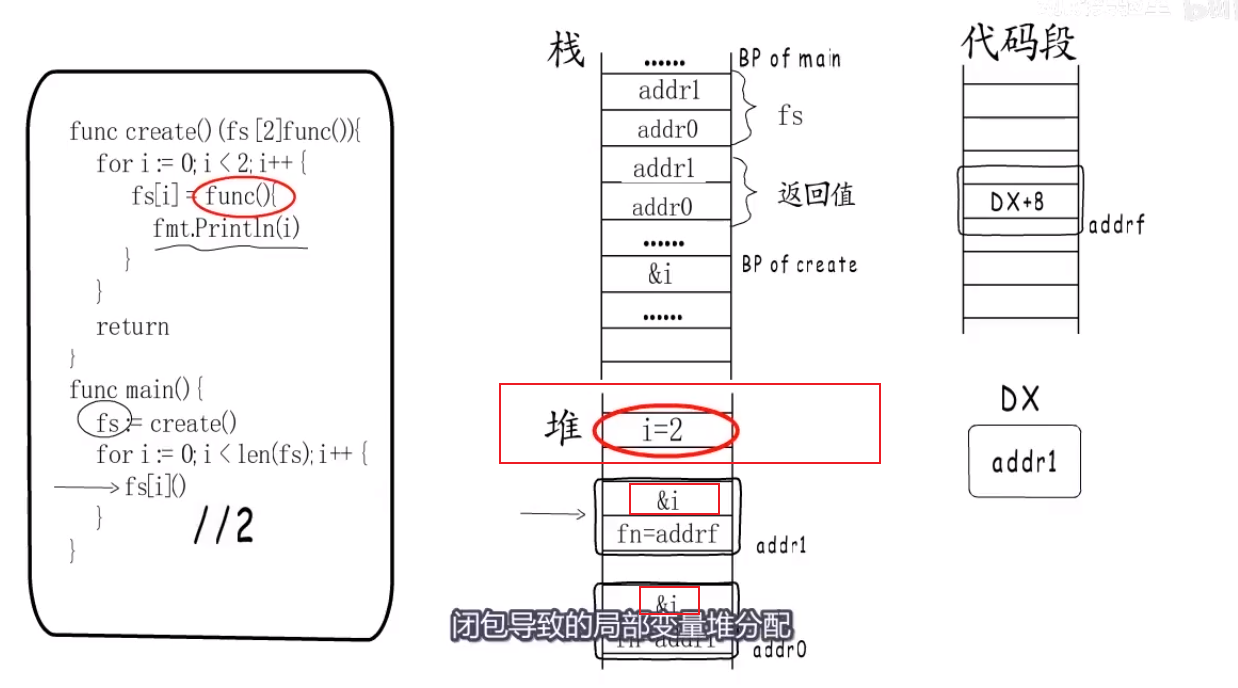
方法(method) #
// TODO
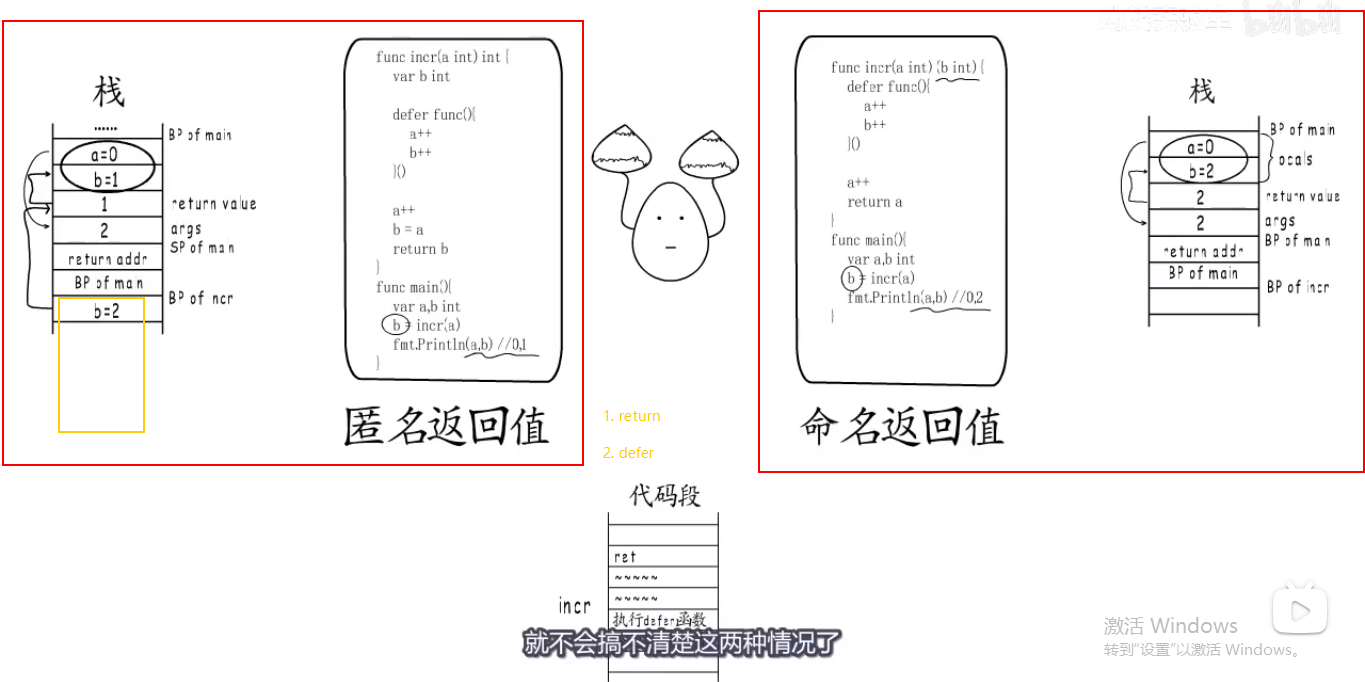
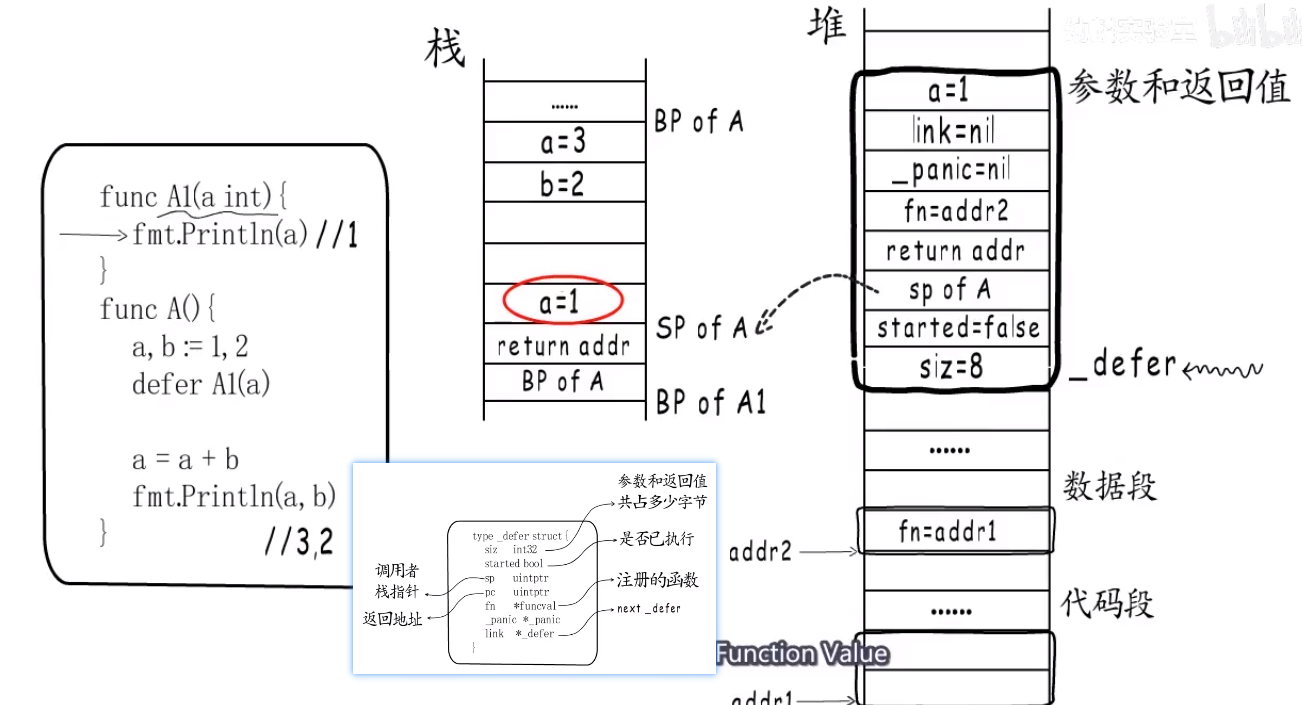
defer三阶段 #
- what:
- defer在内存中怎么表示的?
- 调用
defer B(a)[a是int64]—>func deferproc(size int32, fn *funcval)—>deferproc(8, B's funcval Addr),就变成了调用deferproc函数. func deferproc(siz int32, fn *funcval) 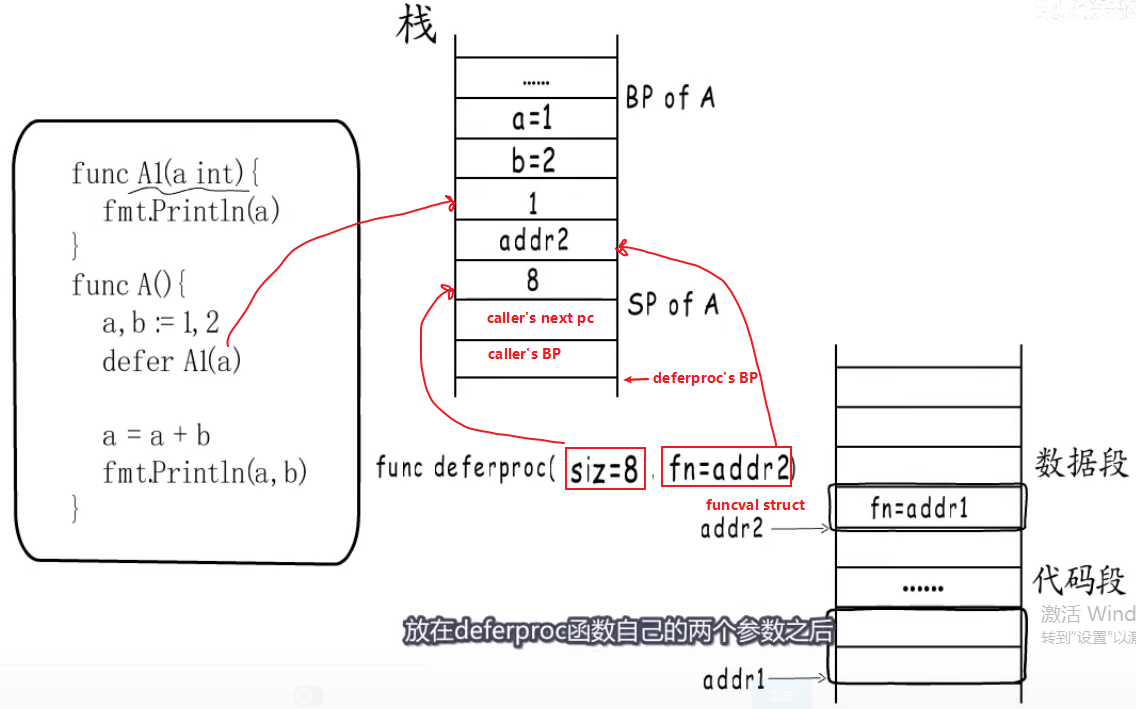
- 调用
- defer在内存中怎么表示的?
- why:
- how:
只要懂得
defer函数其实会被编译器编译成deferproc function。
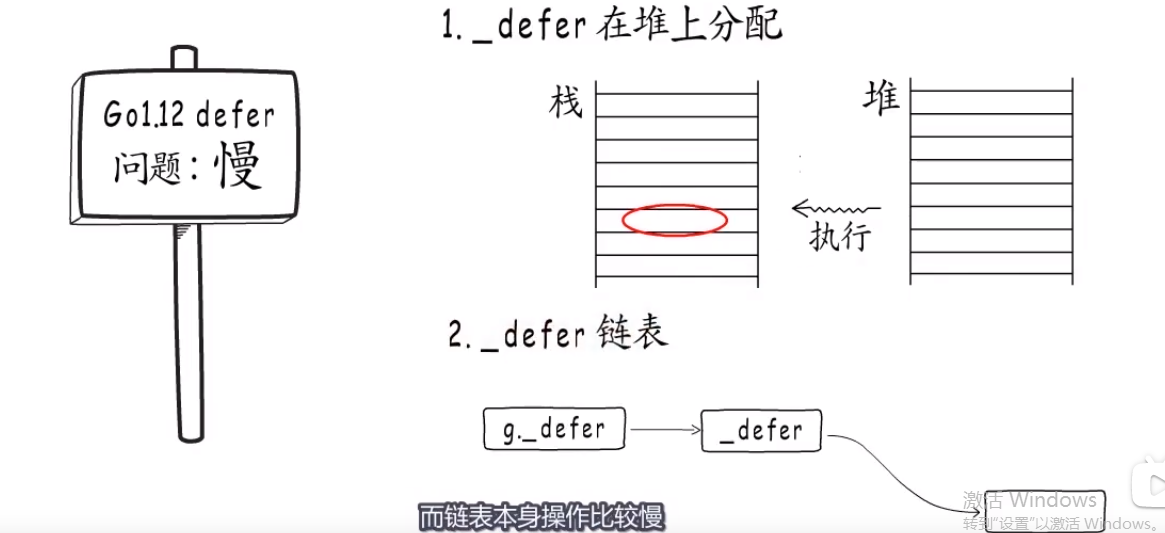
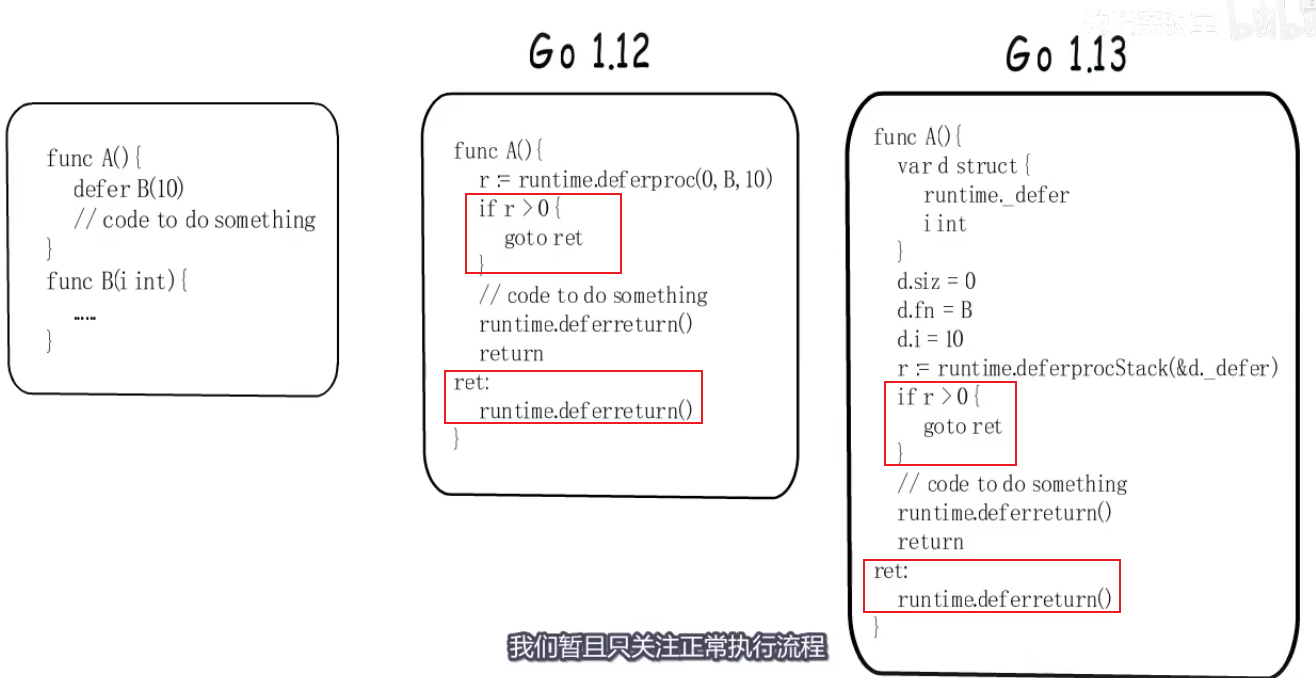
before 1.13 #
deferproc函数填充一个 _defer结构体,参数注册时候会拷贝到堆上,执行时候又拷贝到栈上.
生成的_defer struct放到g._defer链表,且每次都放链表头,这样串联起来.
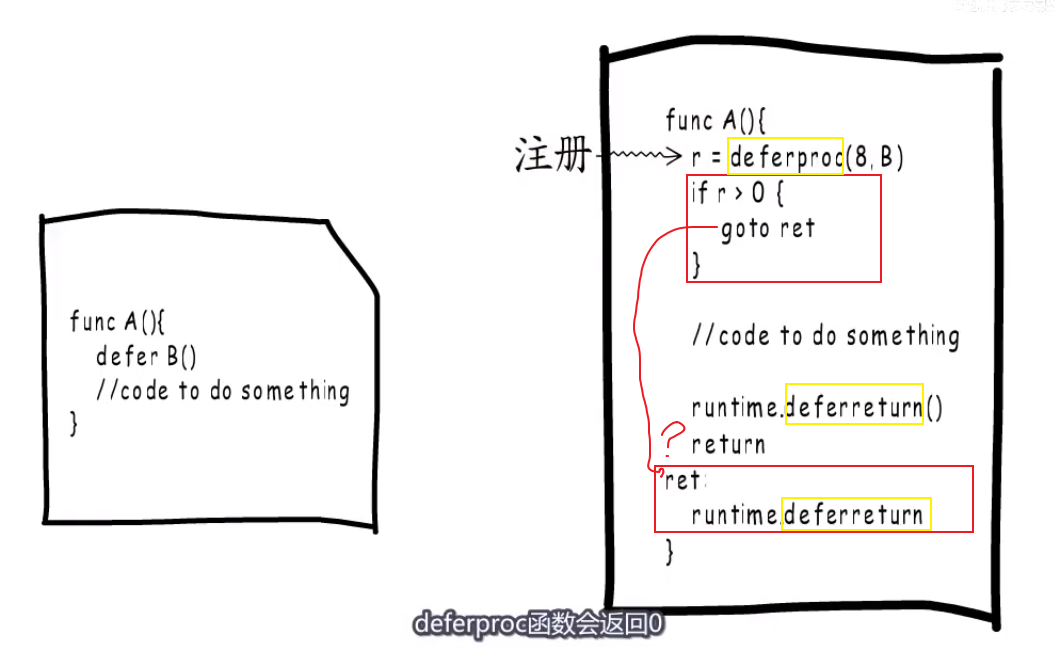
测试题 #
1.13 #
- 1.13如何解决慢的问题?
why:为什么慢?
how:
- 不让_defer结构体参数在栈和堆之间进行拷贝,直接在栈上定义_defer结构体,和参数.
package main
import "testing"
func BenchmarkDefer(b *testing.B){
for i:=0; i< b.N; i++{
Defer(i)
}
}
func Defer(i int)(r int){
defer func(){
r -= 1
r |= r>>1
r |= r>>2
r |= r>>4
r |= r>>8
r |= r>>16
r |= r>>32
r += 1
}()
r = i*i
return
}
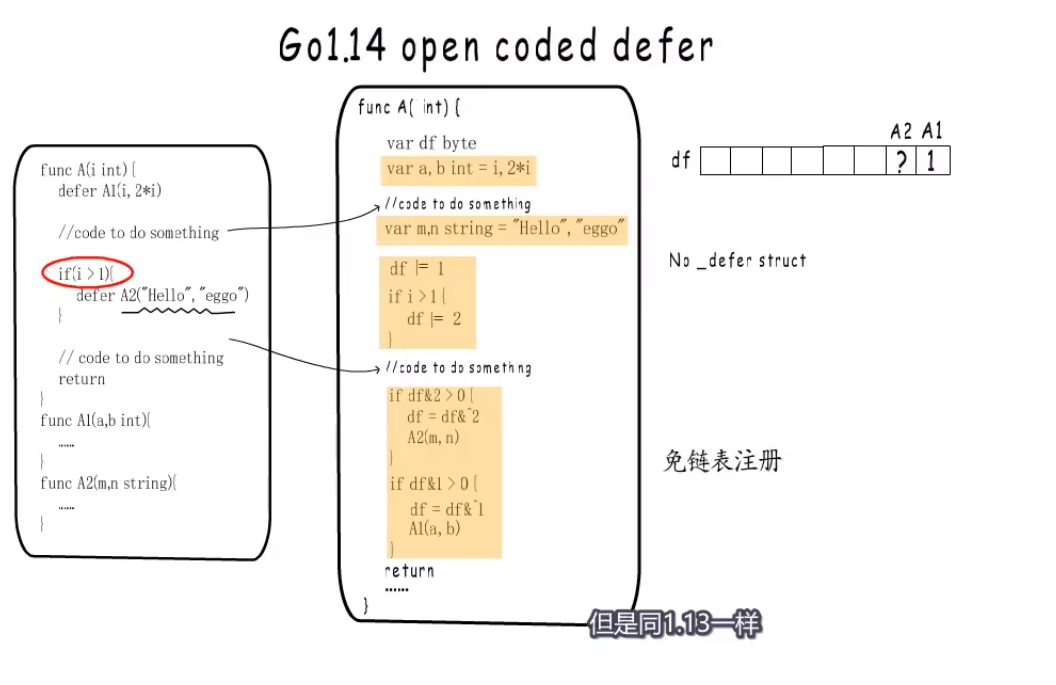
1.14 #
- 1.14如何解决慢的问题?
- why:为什么慢?
- how:
- 直接省去上面两个步骤: 省去构造_defer链表项,并注册到g._defer链表的过程.
- 把defer后面函数需要的参数定义为局部变量,然后在函数返回前直接调用defer后面的函数.
- 如果需要到执行阶段才能确定是否需要被调用执行, go使用标识变量df来解决这个问题.
var df bytedf中的每一位标识一个defer函数是否需要被执行 .
- 直接省去上面两个步骤: 省去构造_defer链表项,并注册到g._defer链表的过程.
- why:为什么慢?
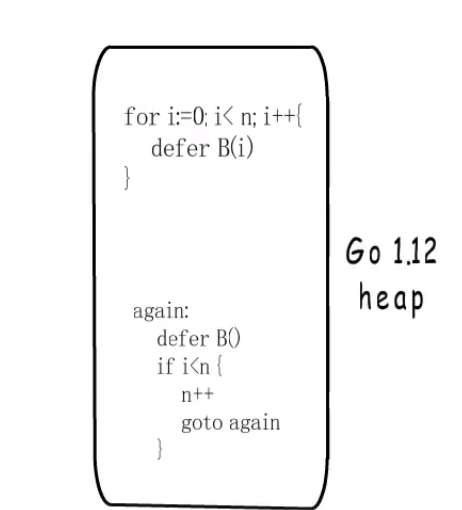
- 思考为什么不支持循环defer?
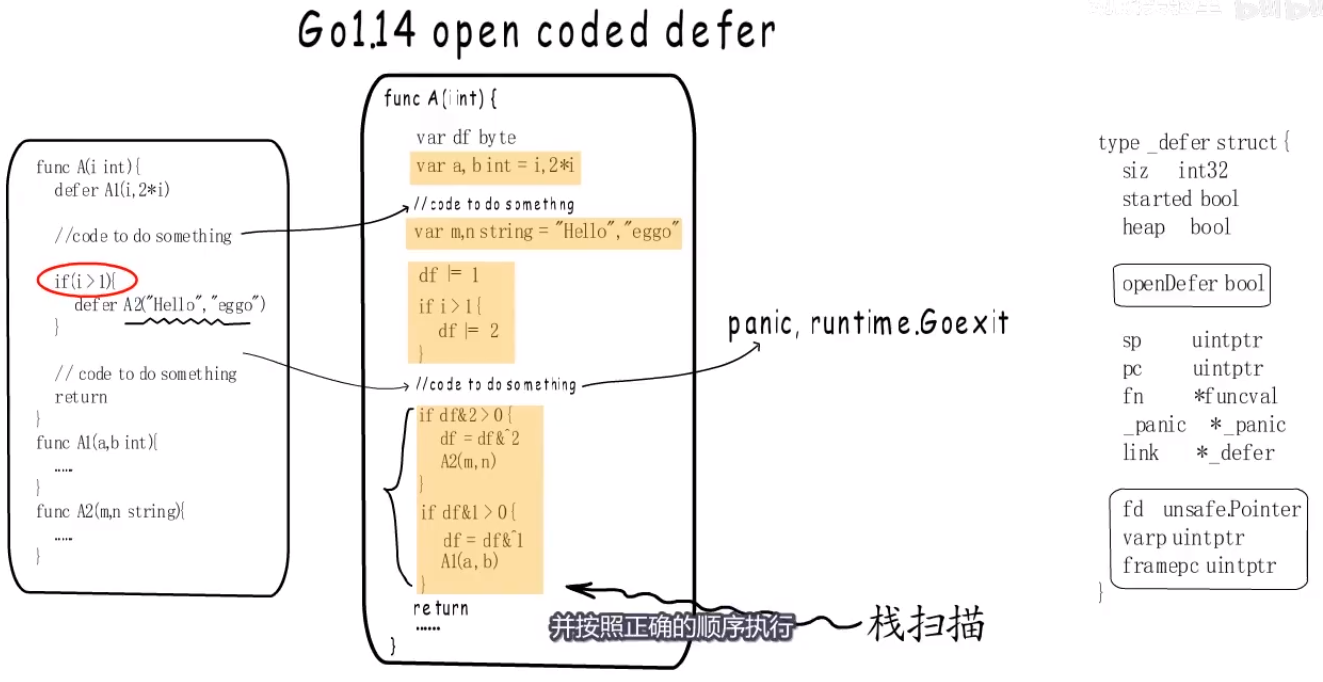
panic AND recover #
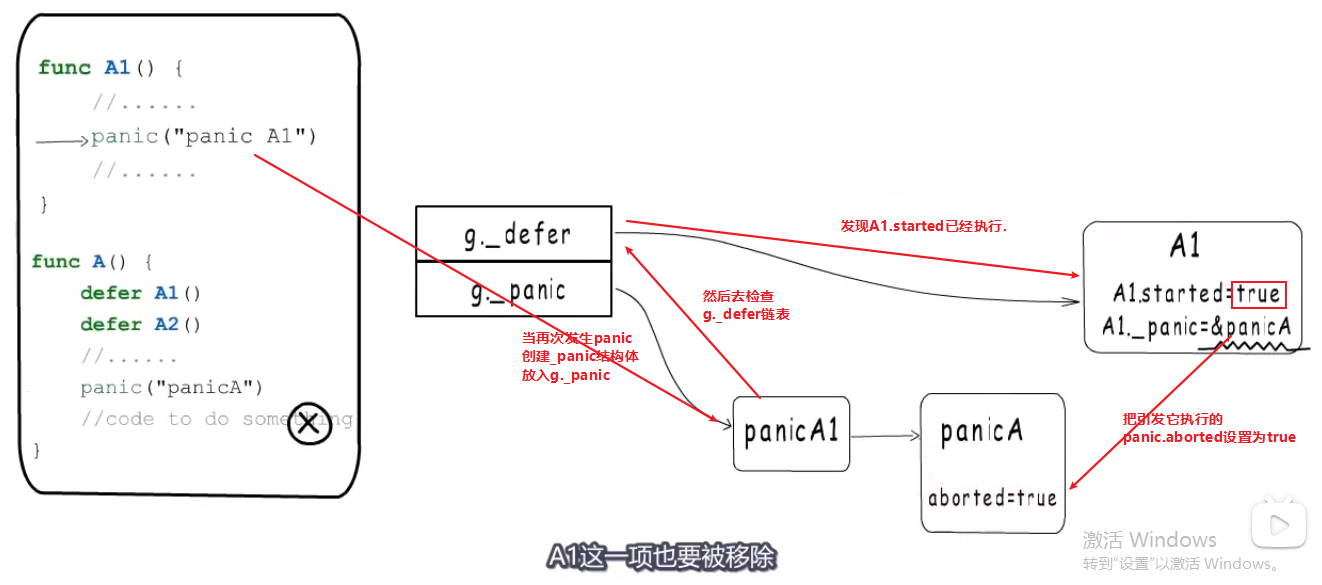
first: panic执行defer函数的方式:先标记后释放,为了终止之前发生的panic. second: 异常信息的输出方式:所有还在panic链表上的项都会被输出.
- what:
panic()函数执行的时候也是填充一个 type _panic struct结构体,放入goroutine's _panic链表中,然后不再执行panic后面的代码,返回,就开始检查goroutine's _defer链表,如果发现_defer’s SP是这个panic所在函数的,就先置started为true,_panic指针指向导致这个defer运行的panic(这是为了当defer里面又有其他panic).当defer执行完后再执行g._panic从链表尾开始输出.- 填充一个_panic结构体
- 不执行panic函数后面的代码, 执行_defer链表。
- why:
- how:
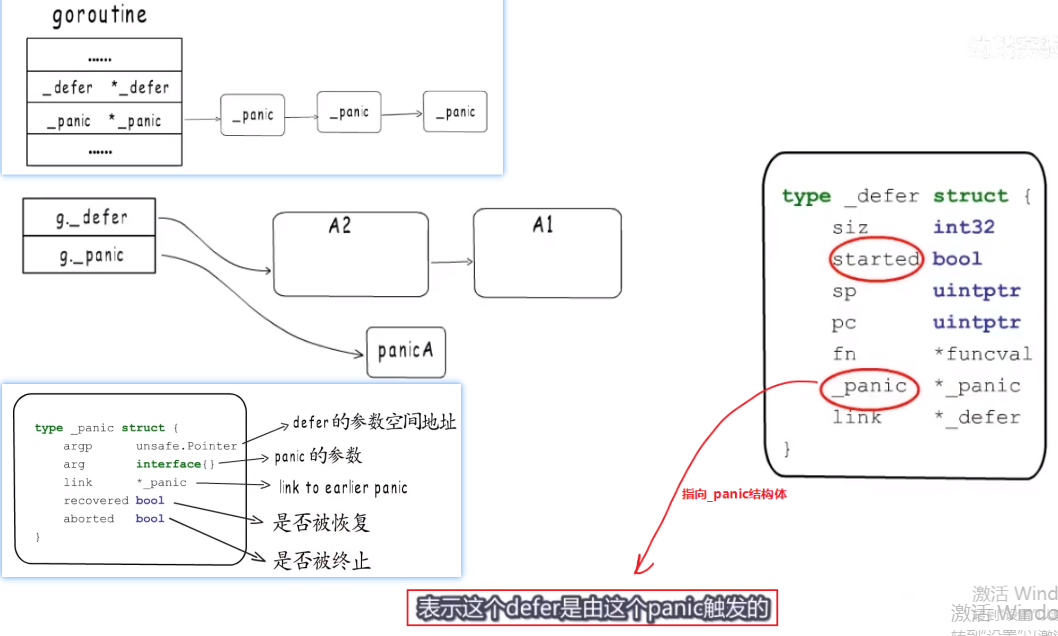
- panic—>defer–>panic
recover
- what:
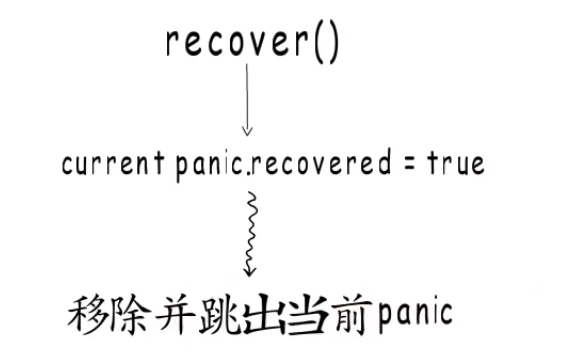
- recover只把当前的_panic.recoved设置为true.
- 然后panic流程会在每个defer执行完毕后,检查次panic是否已经恢复,如果恢复就把它从g._panic链表中移除.
- 然后panic流程会在每个defer执行完毕后,检查次panic是否已经恢复,如果恢复就把它从g._panic链表中移除.
- recover只把当前的_panic.recoved设置为true.
- why:
- how:
- 当_panic被移除后,我们需要跳出panic流程,我们就恢复到defer执行流程(利用它里面的SP, PC),最后ret==1,跳转到
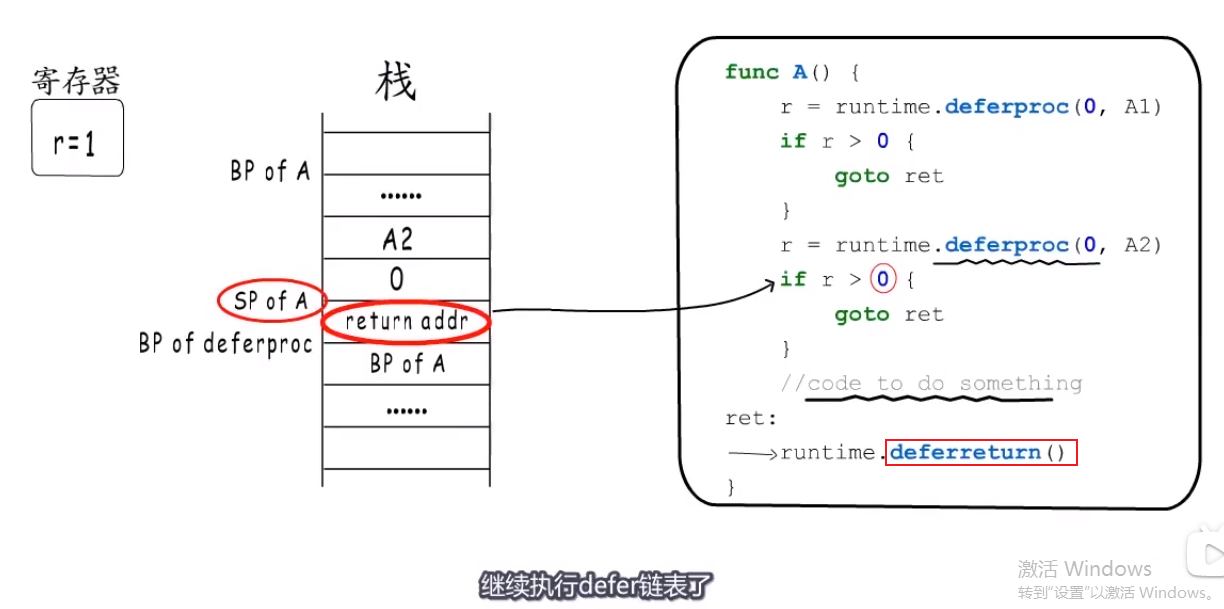
func deferreturn(arg0 uintptr)
func deferreturn(arg0 uintptr) { //... sp := getcallersp() if d.sp != sp { // 如果g._defer链表中头的SP不相等(说明不是这个函数定义的defer)就跳出,不再继续执行. return }- 补充一下,上面可能很难理解,看下图,它有两个
runtime.deferreturn(),如果函数是正常结束,那么会执行第一个runtime.deferreturn()。如果因为中间panic,- 填充一个_panic结构体;
- 不执行panic函数后面的代码, 执行_defer链表。
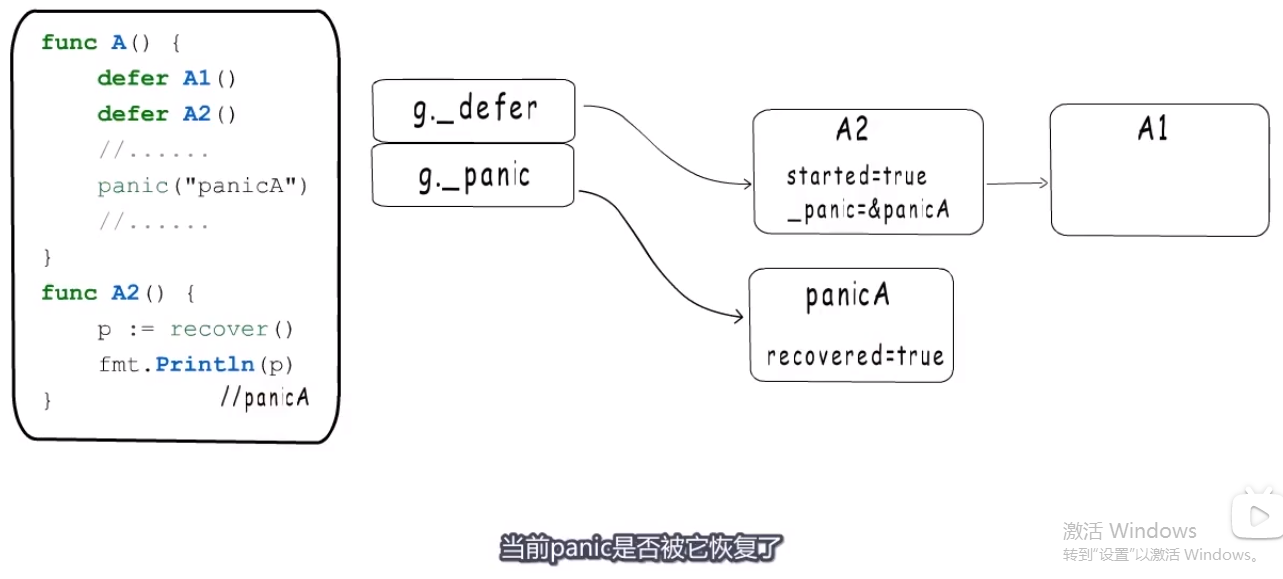
- 当_defer链表中某一个_defer有recover函数
- recover只把当前的_panic.recoved设置为true.
- 然后panic流程会在每个defer执行完毕后,检查次panic是否已经恢复,如果恢复就把它从g._panic链表中移除.
- recover只把当前的_panic.recoved设置为true.
- 此时,panic被移除了,—> 需要跳出这个panic流程
- 恢复_defer链表中的sp,它就到了下图中的
注册~~~~~>这个地方。- 返回1,所以跳到第二个
runtime.deferreturn().
// TODO 如何恢复?
- 返回1,所以跳到第二个
- 当_panic被移除后,我们需要跳出panic流程,我们就恢复到defer执行流程(利用它里面的SP, PC),最后ret==1,跳转到
func deferreturn(arg0 uintptr)
https://goplay.tools/snippet/qoxyANNV481
测验 #
它的输出结果是什么?
package main
import (
"fmt"
)
func deferA() {
fmt.Println("deferA")
panic("panicA")
}
func main() {
defer deferA()
fmt.Println("Hello World")
panic("main")
}
https://goplay.tools/snippet/G5zFPvuiEdJ
package main
import (
"fmt"
)
func A() {
defer A1()
defer A2()
panic("panicA")
}
func A1() {
fmt.Println("A1")
}
func A2() {
defer B1()
panic("panicA2")
}
func B1() {
p := recover()
fmt.Println("B1--->", p)
}
func main() {
A()
}
https://goplay.tools/snippet/phXUi8KDi61
跟interface相关 #
先来看一个Golang如何使用多态来编程:
package main
import "fmt"
// go里面的多态就像是interface
type Itest interface {
Test()
}
type First int
func (f *First) Test() {
fmt.Println("this is First")
return
}
type Second int
func (s *Second) Test() {
fmt.Println("this is Second")
return
}
func main() {
var p Itest
p = new(First)
p.Test()
p = new(Second)
p.Test()
}
空接口与非空接口 #
package main
import "fmt"
// go里面的多态就像是interface
type Itest interface {
Test()
}
type First int
func (f *First) Test() {
fmt.Println("this is First")
return
}
func main() {
var emptyFace interface{} // 空接口
var interfaceFace Itest // 非空接口
var object = new(First)
// 都是保存的一个东西,那么在底层会表现出不一样?
emptyFace = object
interfaceFace = object
// -----------------------------------
_ = emptyFace
_ = interfaceFace
interfaceFace.Test()
// -----------------------------------
}
空接口中的eface结构 #
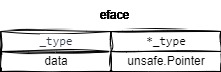
其中
_typetype _type struct
非空接口中的iface结构 #

type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod
}
如果接口类型与动态类型确定了,那么itab的就固定了,此时它是可以复用的.
- go会把itab缓存起来.
https://sourcegraph.com/github.com/golang/go/-/blob/src/runtime/iface.go?L29
func itabHashFunc(inter *interfacetype, typ *_type) uintptr {
// compiler has provided some good hash codes for us.
return uintptr(inter.typ.hash ^ typ.hash)
}
类型断言 #
reflect #
reflect.Type #
- what:
// TypeOf returns the reflection Type that represents the dynamic type of i.
// If i is a nil interface value, TypeOf returns nil.
func TypeOf(i interface{}) Type {
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.typ)
}}
- why:
- how:
- TypeOf它的输入参数是eface,返回参数是iface类型(因为
type Type interface是一个非空接口类型.)
- 所以需要转换一下,下图有说明.
- TypeOf它的输入参数是eface,返回参数是iface类型(因为
type Type interface是一个非空接口类型.)
confliction:
空接口类型的参数只能接收地址的需求.
TOOD:感觉这个地方与reflect不能Set成员函数也有关系.
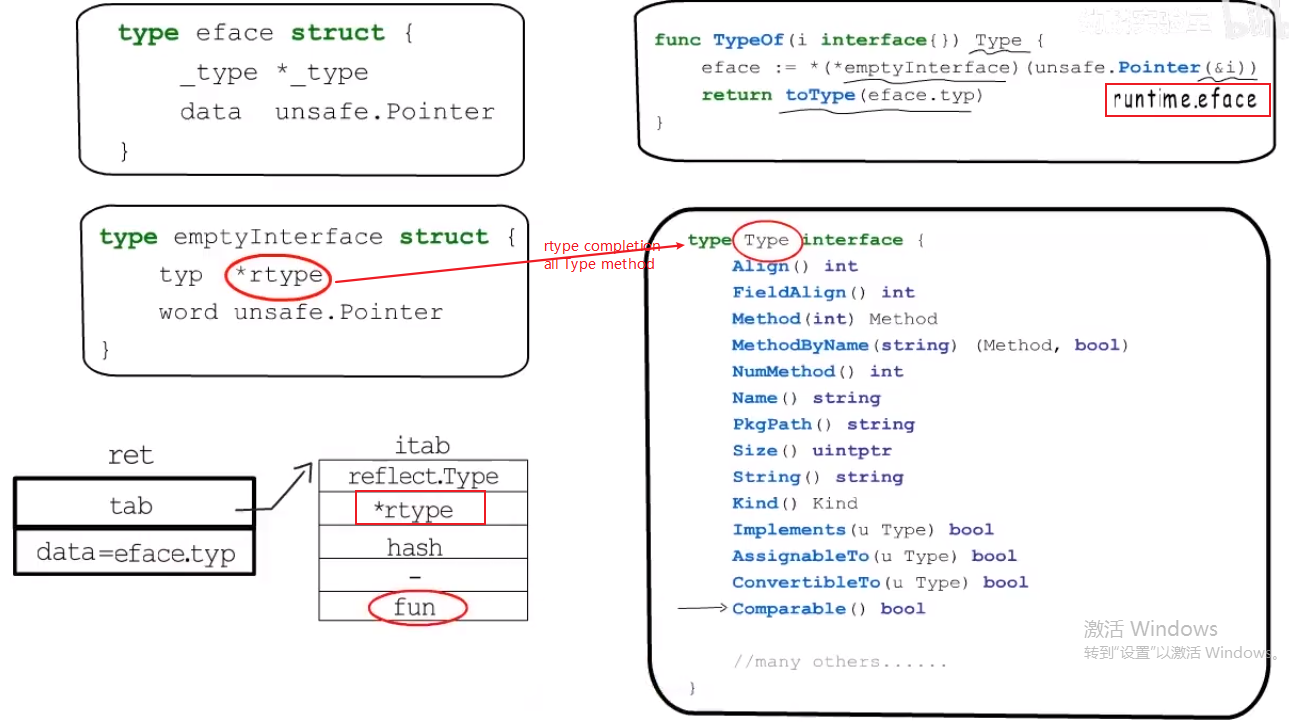
- 因为reflect.Type也是一个非空接口类型, 它有许多方法.所以使用上节所用的非空接口类型。
reflect.Value #
type Value struct {
// typ holds the type of the value represented by a Value.
typ *rtype
ptr unsafe.Pointer
// The lowest bits are flag bits:
// - flagStickyRO: obtained via unexported not embedded field, so read-only
// - flagEmbedRO: obtained via unexported embedded field, so read-only
// - flagIndir: val holds a pointer to the data
// - flagAddr: v.CanAddr is true (implies flagIndir)
// - flagMethod: v is a method value.
flag
}
注意点:rtype这个结构体与 ../runtime/type.go:/^type._type是要保持一致的(一一对应)。

继续来看下这个unpackEface
// unpackEface converts the empty interface i to a Value.
func unpackEface(i interface{}) Value {
e := (*emptyInterface)(unsafe.Pointer(&i))
// NOTE: don't read e.word until we know whether it is really a pointer or not.
t := e.typ
if t == nil {
return Value{}
}
// 下面的这些主要是构建一个Value结构体中的一个字段flag
f := flag(t.Kind())// 这里t.Kind()就是rtype或者说_type中的kind字段
if ifaceIndir(t) {
f |= flagIndir
}
return Value{t, e.word, f}
}
func (t *rtype) Kind() Kind { return Kind(t.kind & kindMask) }
const kindMask = (1 << 5) - 1
//取最后的五个bits。
//最终再强制转为flag类型---》 rtype使用Kind方法可以得到实际的Kind值
//我们看下flag得到Kind值
func (f flag) kind() Kind {
return Kind(f & flagKindMask)
}
const flagKindMask flag = 1<<flagKindWidth -
//是一模一样的。
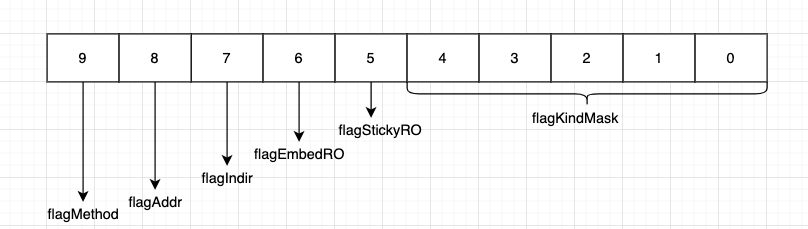
// --------------------------
// --------------------------
// --------------------------
运行时: #
并发编程 #
同步原语 #
- what:
- 并发同步是指如何控制若干并发计算(在Go中,即协程),从而
- 避免在它们之间产生数据竞争的现象;
- 避免在它们无所事事的时候消耗CPU资源。
- 并发同步有时候也称为数据同步。
- 并发同步是指如何控制若干并发计算(在Go中,即协程),从而
- why:
- 避免在它们之间产生数据竞争的现象;
- 避免在它们无所事事的时候消耗CPU资源。
- how:
通道用例大全
如何优雅地关闭通道
- sync.WaitGroup(等待组)类型: :Add(delta int)、Done()和Wait()
- sync.Once类型: Do(f func())方法
- 一个sync.Once值被用来确保一段代码在一个并发程序中被执行且仅被执行一次
- sync.Mutex(互斥锁)和sync.RWMutex(读写锁)类型: 实现了
sync.Locker接口类型。 所以这两个类型都有两个方法:Lock()和Unlock(),- 用来保护一份数据不会被多个使用者同时读取和修改。
- *sync.RWMutex类型还有两个另外的方法:RLock()和RUnlock(),
- 用来支持多个读取者并发读取一份数据但防止此份数据被某个数据写入者和其它数据访问者(包括读取者和写入者)同时使用
- sync.Cond类型:提供了一种有效的方式来实现多个协程间的通知。
- 成员: sync.Locker类型的名为L的字段
- 成员函数: Wait()、Signal()和Broadcast()。
- 每个Cond值维护着一个先进先出等待协程队列。 对于一个可寻址的Cond值c,
- c.Wait()必须在c.L字段值的锁被成功获取的时候调用;否则,c.Wait()调用将造成一个恐慌。 一个c.Wait()调用将
- 首先将当前协程入到c所维护的等待协程队列;
- 然后调用c.L.Unlock()释放c.L的锁;
- 然后使当前协程进入阻塞状态;(当前协程将被另一个协程通过c.Signal()或c.Broadcast()调用唤醒而重新进入运行状态。)
- 一旦当前协程重新进入运行状态,c.L.Lock()将被调用以试图重新获取c.L字段值的锁。 此c.Wait()调用将在此试图成功之后退出。
- 一个c.Signal()调用将唤醒并移除c所维护的等待协程队列中的第一个协程(如果此队列不为空的话)。
- 一个c.Broadcast()调用将唤醒并移除c所维护的等待协程队列中的所有协程(如果此队列不为空的话)。
- c.Wait()必须在c.L字段值的锁被成功获取的时候调用;否则,c.Wait()调用将造成一个恐慌。 一个c.Wait()调用将
- 每个Cond值维护着一个先进先出等待协程队列。 对于一个可寻址的Cond值c,
T—可以换成—>内置int32、int64、uint32、uint64和uintptr类型func AddT(addr *T, delta T)(new T) func LoadT(addr *T) (val T) func StoreT(addr *T, val T) func SwapT(addr *T, new T) (old T) func CompareAndSwapT(addr *T, old, new T) (swapped bool)
我们也可以利用网络和文件读写来做并发同步,但是这样的并发同步方法使用在一个程序进程内部时效率相对比较低。 一般来说,这样的方法多适用于多个进程之间或多个主机之间的并发同步。《Go语言101》中不介绍这样的并发同步方法。
内存顺序保证 #
- Go中的内存顺序保证
- 内存顺序
- what: 调整指令执行顺序,从而使得指令执行顺序和代码中指定的顺序不太一致。 指令顺序也称为内存顺序。
- why:
- how:
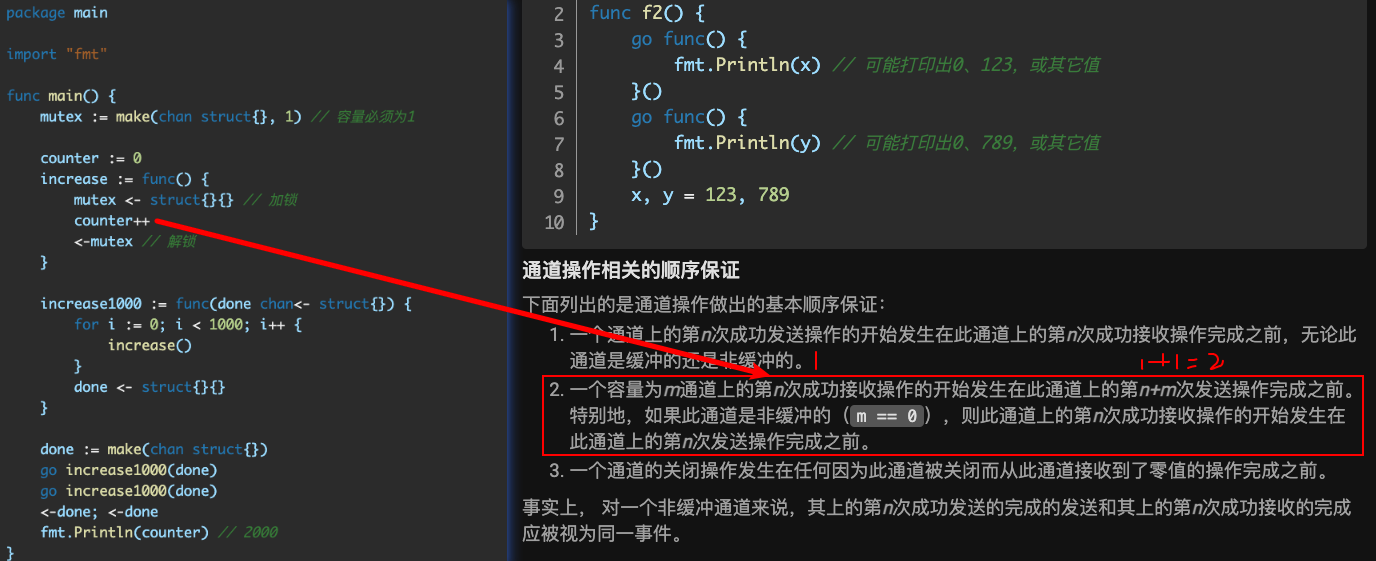
- 通道操作相关的顺序保证:
- 一个通道上的第n次成功发送操作的开始发生在此通道上的第n次成功接收操作完成之前,无论此通道是缓冲的还是非缓冲的。
- 如果是缓冲,一边是发送,数据进入到通道中,当另一边接收的时候,肯定在前一边之后。
- 一个容量为m通道上的第n次成功接收操作的开始发生在此通道上的第n+m次发送操作完成之前。 特别地,如果此通道是非缓冲的(m == 0),则此通道上的第n次成功接收操作的开始发生在此通道上的第n次发送操作完成之前。
- 一个通道的关闭操作发生在任何因为此通道被关闭而从此通道接收到了零值的操作完成之前。
- 事实上, 对一个非缓冲通道来说,其上的第n次成功发送的完成和其上的第n次成功接收的完成应被视为同一事件。
- 好像他们就是保证当阻塞发送接收的时候,他们可以当成一个事件,同时发生的。
- example:
- 通道操作相关的顺序保证:
- what: 调整指令执行顺序,从而使得指令执行顺序和代码中指定的顺序不太一致。 指令顺序也称为内存顺序。
- 内存顺序
sync包 #
- sync.Map的核心实现 - 两个map,一个用于写,另一个用于读,这样的设计思想可以类比
缓存与数据库 - sync.Map的局限性 - 如果写远高于读,dirty->readOnly 这个类似于
刷数据的频率就比较高,不如直接用mutex + map的组合 - sync.Map的设计思想 - 保证高频读的无锁结构、空间换时间
- sync.Cond的核心实现 - 通过一个锁,封装了
notify 通知的实现,包括了单个通知与广播这两种方式 - sync.Cond与channel的异同 - channel应用于
一收一发的场景,sync.Cond应用于多收一发的场景 - sync.Cond的使用探索 - 多从专业社区收集意见 https://github.com/golang/go/issues/21165
- sync.Pool的核心作用 - 读源码,
缓存稍后会频繁使用的对象+减轻GC压力 - sync.Pool的Put与Get - Put的顺序为
local private-> local shared,Get的顺序为local private -> local shared -> remote shared - 思考sync.Pool应用的核心场景 -
高频使用且生命周期短的对象,且初始化始终一致,如fmt - 探索Go1.13引入
victim的作用 - 了解victim cache的机制
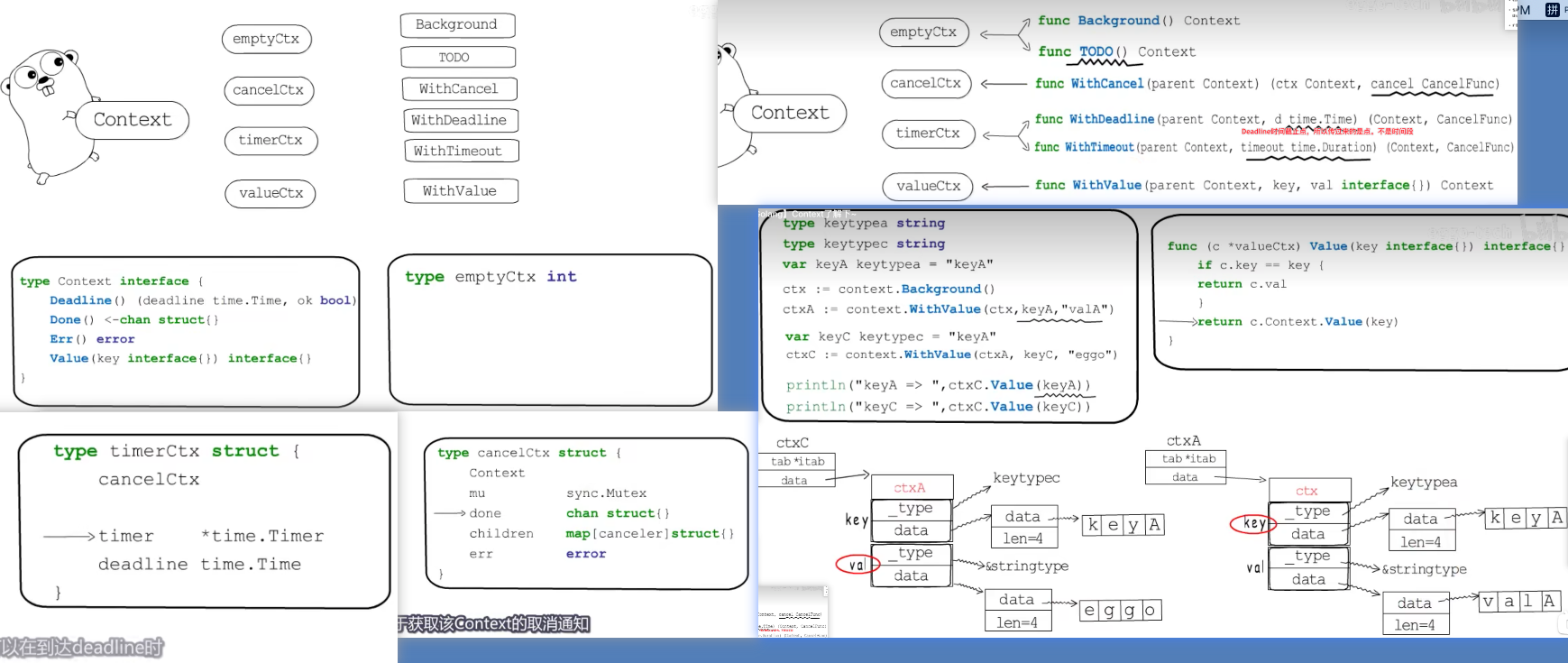
context(上下文) #
一个接口,四种实现,六个函数
- 传值,从上游传值到下游。
- 取消事件,当上游取消时,能通知下游也取消,避免无用功,资源浪费。
- 监听事件:一般下游监听上游取消事件(但是也可以反过来)。
- 主动取消事件:上游取消,下游监听/设置超时
func main() {
// Create an HTTP server that listens on port 8000
http.ListenAndServe(":8000", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
ctx := r.Context() // 这个context从http请求中来
// This prints to STDOUT to show that processing has started
fmt.Fprint(os.Stdout, "processing request\n")
// We use `select` to execute a peice of code depending on which
// channel receives a message first
select {
case <-time.After(2 * time.Second):
// If we receive a message after 2 seconds
// that means the request has been processed
// We then write this as the response
w.Write([]byte("request processed"))
case <-ctx.Done():
// If the request gets cancelled, log it
// to STDERR
fmt.Fprint(os.Stderr, "request cancelled\n")
}
}))
}
package main
import (
"context"
"errors"
"fmt"
"time"
)
func operation1(ctx context.Context) error {
// Let's assume that this operation failed for some reason
// We use time.Sleep to simulate a resource intensive operation
time.Sleep(100 * time.Millisecond)
return errors.New("failed")
}
func main() {
// Create a new context
ctx := context.Background()
// Create a new context, with its cancellation function
// from the original context
ctx, cancel := context.WithCancel(ctx)
// Run two operations: one in a different go routine
go func() {
err := operation1(ctx)
// If this operation returns an error
// cancel all operations using this context
if err != nil {
cancel()
}
}()
// Run operation2 with the same context we use for operation1
operation2(ctx)
}
func operation2(ctx context.Context) {
// We use a similar pattern to the HTTP server
// that we saw in the earlier example
select {
case <-time.After(500 * time.Millisecond):
fmt.Println("done")
case <-ctx.Done():
fmt.Println("halted operation2")
}
}
func main() {
// Create a new context
// With a deadline of 100 milliseconds
ctx := context.Background()
ctx, _ = context.WithTimeout(ctx, 2*time.Second)
// Make a request, that will call the google homepage
req, _ := http.NewRequest(http.MethodGet, "http://google.com", nil)
// Associate the cancellable context we just created to the request
req = req.WithContext(ctx)
// Create a new HTTP client and execute the request
client := &http.Client{}
res, err := client.Do(req)
// If the request failed, log to STDOUT
if err != nil {
fmt.Println("Request failed:", err)
return
}
// Print the statuscode if the request succeeds
fmt.Println("Response received, status code:", res.StatusCode)
}
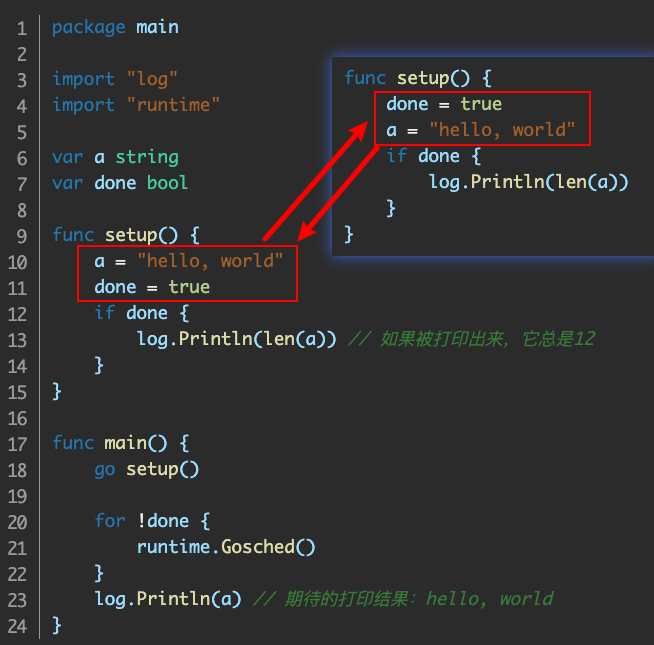
1 // TODO
- 四个方法
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{} //返回一个channel.
Err() error
Value(key interface{}) interface{}
}
- 内部Ctx
- cancelCtx
- WithCancel: 把父Context装进子Context’s Context.
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) { if parent == nil { panic("cannot create context from nil parent") } c := newCancelCtx(parent) // 常见一个新的子context; propagateCancel(parent, &c) // 然后准备把新生成的子context加入到parent中; return &c, func() { c.cancel(true, Canceled) } }- 目前 context 有个非常重要点, 在 Go 只有阻塞式调用没有非阻塞调用,所以必须要有 context cancel (or Done() or Err()) 相关操作,否则操作一旦陷进去没响应 (本质是 goroutines 调度控制),goroutine 就无法继续了.
func main() { ctx,cancel := context.WithCancel(context.Background()) go Speak(ctx) time.Sleep(10*time.Second) cancel() time.Sleep(1*time.Second) } func Speak(ctx context.Context) { for range time.Tick(time.Second){ select { case <- ctx.Done(): fmt.Println("我要闭嘴了") return default: fmt.Println("balabalabalabala") } } } - valueCtx
- WithValue:
- emptyCtx
- cancelCtx
这里需要说明的是type interface可以放进struct里面:
内存管理 #
GC #
逃逸分析 #
- what:
转义分析是go编译器的一个阶段。它分析源代码并确定哪些变量应该分配到堆栈上,哪些变量应该转义到堆中。
指针(或者引用)的逃逸(Escape): 当变量(或者对象)在方法中分配后,其指针有可能被返回或者被全局引用,这样就会被其他过程或者线程所引用.
- 逃逸分析: 是一种确定指针动态范围的方法,可以分析在程序的哪些地方可以访问到指针。
- 必然发生逃逸:
- 在某个函数中new或字面量创建出的变量,将其指针作为函数返回值,则该变量一定发生逃逸(构造函数返回的指针变量一定逃逸);
- 被已经逃逸的变量引用的指针,一定发生逃逸;
type User struct { Username string Password string Age int } func main() { a := "aaa" u := &User{a, "123", 12} Call1(u) } func Call1(u *User) { fmt.Printf("%v",u) } /* func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error) { p := newPrinter() p.doPrintf(format, a) ... } func (p *pp) doPrintf(format string, a []interface{}) { ... p.printArg(a[argNum], rune(c)) ... } func (p *pp) printArg(arg interface{}, verb rune) { p.arg = arg p.value = reflect.Value{} ... } */ //-------------上面逃逸,下面没有------------------// func main() { a := "aaa" u := &User{a, "123", 12} Call1(u) } func Call1(u *User) int { return Call2(u) } func Call2(u *User) int { return Call3(u) } func Call3(u *User) int { u.Username = "bbb" return u.Age * 20 } /* go run -gcflags "-m -l" main.go # command-line-arguments ./main.go:23:12: Call3 u does not escape ./main.go:19:12: Call2 u does not escape ./main.go:15:12: Call1 u does not escape ./main.go:11:23: main &User literal does not escape */- 被指针类型的slice、map和chan引用的指针,一定发生逃逸;
func main() { a := make([]*int,1) b := 12 a[0] = &b c := make(map[string]*int) d := 14 c["aaa"]=&d e := make(chan *int,1) f := 15 e <- &f } /* go run -gcflags "-m -l" main.go # command-line-arguments ./main.go:7:2: moved to heap: b ./main.go:11:2: moved to heap: d ./main.go:15:2: moved to heap: f ./main.go:6:11: main make([]*int, 1) does not escape ./main.go:10:11: main make(map[string]*int) does not escape */ - 必然不会逃逸的情况:
- 指针被未发生逃逸的变量引用;
- 仅仅在函数内对变量做取址操作,而未将指针传出;
- 可能发生逃逸,也可能不会发生逃逸:
- 将指针作为入参传给别的函数;这里还是要看指针在被传入的函数中的处理过程,如果发生了上边的三种情况,则会逃逸;否则不会逃逸;
- 必然发生逃逸:
- 逃逸分析: 是一种确定指针动态范围的方法,可以分析在程序的哪些地方可以访问到指针。
why: 存储位置确实对编写高效程序有影响。在可能的情况下,Go编译器会在一个函数的堆栈框架中分配属于该函数的局部变量。然而,如果编译器不能证明该变量在函数返回后没有被引用,那么编译器必须在垃圾收集的堆上分配该变量,以避免悬空指针错误。另外,如果一个局部变量非常大,把它存储在堆上而不是堆上可能更有意义。
不逃逸的对象分配在栈上,则变量在用完后就会被编译器回收,从而减少GC的压力
栈上的分配要比堆上的分配更加高效
同步消除,如果定义的对象上有同步锁,但是栈在运行时只有一个线程访问,逃逸分析后如果在栈上则会将同步锁去除
- gc压力
//我:“golang函数传参是不是应该跟c一样,尽量不要直接传结构体,而要传结构体指针?“ //leader:“不对,咱们项目很多都是直接传结构体的。“ //我:“那样不会造成不必要的内存copy开销吗?” //leader:“确实会有,但这样可以减小gc压力,因为传值会在栈上分配,而一旦传指针,结构体就会逃逸到堆上。“ - 不逃逸的对象放栈上,可能逃逸的放堆上:
- gc的压力: 最大的好处应该是减少gc的压力,不逃逸的对象分配在栈上,当函数返回时就回收了资源,不需要gc标记清除。
- 因为逃逸分析完后可以确定哪些变量可以分配在栈上,栈的分配比堆快,性能好
- 同步消除,如果你定义的对象的方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行。
- gc压力
how:
-gcflags '-m -l'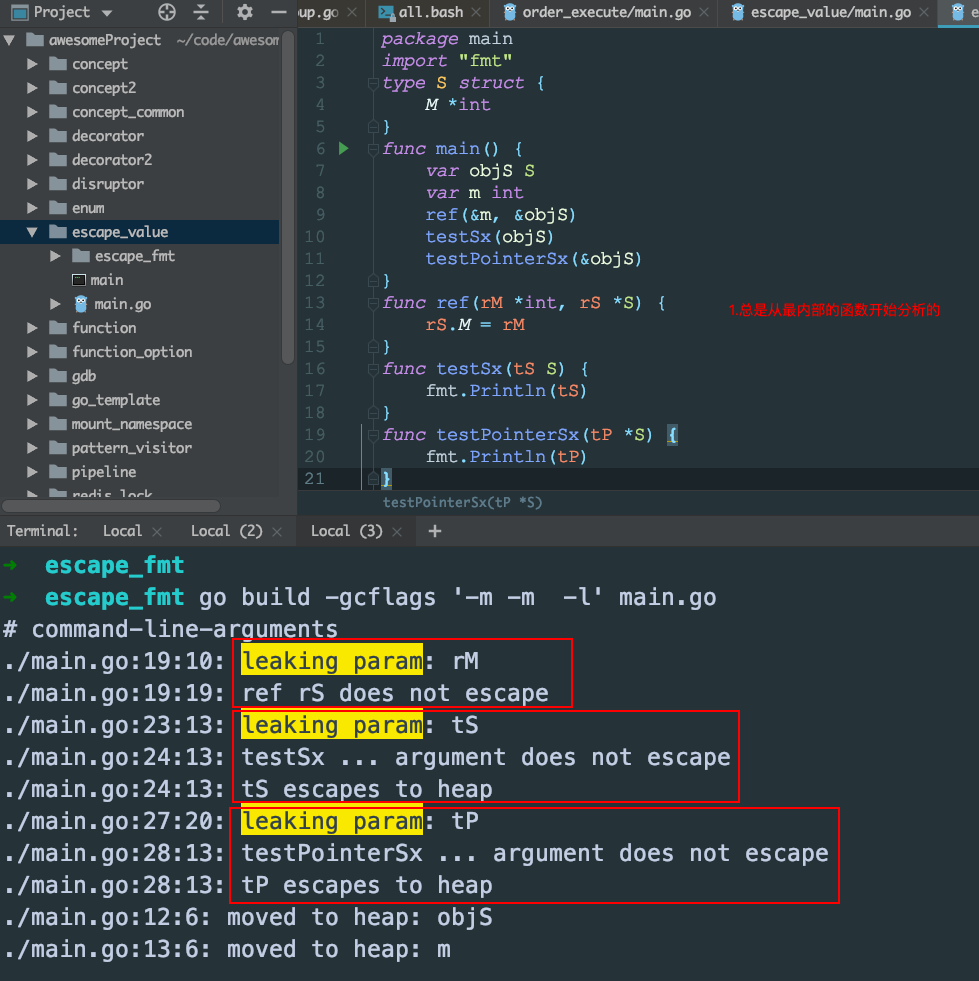
- 从内部函数开始分析,它的好处的是,如果底部的函数中都没有逃逸,那么最上层的变量就直接放入栈里面就行了,不需要放堆里。
- 这里的objS没有逃逸,而m却逃逸了,这是因为go的逃逸分析不知道objS和m的关系,逃逸分析不知道参数M是
struct S的一个成员,所以只能把它分配给堆。
- 这里的objS没有逃逸,而m却逃逸了,这是因为go的逃逸分析不知道objS和m的关系,逃逸分析不知道参数M是
- 从内部函数开始分析,它的好处的是,如果底部的函数中都没有逃逸,那么最上层的变量就直接放入栈里面就行了,不需要放堆里。
- 指针逃逸
- 栈空间不足
- 闭包
// $GOROOT/src/runtime/stubs.go
func noescape(p unsafe.Pointer) unsafe.Pointer {
x := uintptr(p)
return unsafe.Pointer(x ^ 0) // 任何数值与0的异或都是原数
}
该函数的实现逻辑使得我们传入的指针值与其返回的指针值是一样的。该函数只是通过uintptr做了一次转换,而这次转换将指针转换成了数值,这“切断”了逃逸分析的数据流跟踪,导致传入的指针避免逃逸。
package main
import (
"fmt"
"unsafe"
)
func noescape(p unsafe.Pointer) unsafe.Pointer {
x := uintptr(p)
return unsafe.Pointer(x ^ 0)
}
func foo() {
var a int = 66666666
var b int = 77
// 按道理此处会发生逃逸
fmt.Printf("addr of a in bar = %p\n", (*int)(noescape(unsafe.Pointer(&a))))
println("addr of a in bar =", &a)
println("addr of b in bar =", &b)
}
func main() {
foo()
}
https://zhuanlan.zhihu.com/p/91559562
内存泄漏 #
what:
- 当使用一门支持自动垃圾回收的语言编程时,一般来说我们不需要关心内存泄露问题,因为程序的运行时会负责回收不再使用的内存。 但是,我们确实也需要知道一些特殊的可能会造成暂时性或永久性内存泄露的情形。
why:
- 临时性内存泄露
- 底层共用同一个内存空间引起的:
- 子字符串造成的暂时性内存泄露
var s0 []int func g(s1 []int) { // 假设s1的长度远大于30。 s0 = s1[len(s1)-30:] }- 子切片造成的暂时性内存泄露
- 因为未重置丢失的切片元素中的指针而造成的临时性内存泄露
func h() []*int { s := []*int{new(int), new(int), new(int), new(int)} // 使用此s切片 ... //s[0], s[len(s)-1] = nil, nil // 添加这一行:重置首尾元素指针 return s[1:3:3] } - 延迟调用函数导致的临时性内存泄露
func writeManyFiles(files []File) error { for _, file := range files { f, err := os.Open(file.path) if err != nil { return err } defer f.Close() _, err = f.WriteString(file.content) if err != nil { return err } err = f.Sync() if err != nil { return err } } return nil }
- 底层共用同一个内存空间引起的:
- 永久性内存泄露
- 因为协程被永久阻塞而造成的永久性内存泄露
泄露的场景不仅限于以下两类,但因channel相关的泄露是最多的。
- channel的读或者写:
- ‘空’读写阻塞-关闭恐慌; <—>
‘关闭’读为0-关闭写恐慌.如果是有缓存的chan已关闭,且现在缓存不为空,读正常得到数. - 写:
- 无缓冲channel的阻塞通常是写操作因为没有读而阻塞
- 有缓冲的channel因为缓冲区满了,写操作阻塞
- 读:期待从channel读数据,结果没有goroutine写
- select操作,select里也是channel操作,如果所有case上的操作阻塞,goroutine也无法继续执行。
default
- ‘空’读写阻塞-关闭恐慌; <—>
- channel的读或者写:
- 因为没有停止不再使用的time.Ticker值而造成的永久性内存泄露
- 因为不正确地使用终结器(finalizer)而造成的永久性内存泄露
- 因为协程被永久阻塞而造成的永久性内存泄露
泄露的场景不仅限于以下两类,但因channel相关的泄露是最多的。
- 临时性内存泄露
how: 怎么发现内存泄露,
- 在Go中发现内存泄露有2种方法:
- 一个是通用的监控工具;
- 另一个是go pprof。
- 在Go中发现内存泄露有2种方法:
当连接在服务器终端上的时候,是没有浏览器可以使用的,Go提供了命令行的方式,能够获取以上5类信息,这种方式用起来更方便。
使用命令go tool pprof url可以获取指定的profile文件,此命令会发起http请求,然后下载数据到本地,之后进入交互式模式(只要进入到交互模式说明已经下载完成,与将要调查的程序无关了).
# 下载cpu profile,默认从当前开始收集30s的cpu使用情况,需要等待30s
go tool pprof http://localhost:6060/debug/pprof/profile # 30-second CPU profile
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=120 # wait 120s
# 下载heap profile
go tool pprof http://localhost:6060/debug/pprof/heap # heap profile
# 下载goroutine profile
go tool pprof http://localhost:6060/debug/pprof/goroutine # goroutine profile
# 下载block profile
go tool pprof http://localhost:6060/debug/pprof/block # goroutine blocking profile
# 下载mutex profile
go tool pprof http://localhost:6060/debug/pprof/mutex
- top
- 按前面下载的指标是什么,按照它们的大小列出前10个函数,比如heap是按heap占用多少。
- list function_name
- 查看某个函数的代码,以及该函数每行代码的指标信息,如果函数名不明确,会进行模糊匹配,比如list main会列出main.main和runtime.main。
- traces
- 打印所有调用栈,以及调用栈的指标信息。
// 隔一段时间分别运行,抓取它的heap信息.
go tool pprof http://localhost:6060/debug/pprof/heap
// 使用-base Options来以001作为基准,与003来比较。
go tool pprof -base pprof.main.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz pprof.main.alloc_objects.alloc_space.inuse_objects.inuse_space.003.pb.gz
// top
top
// list 上面展示的函数,查看具体代码行。 很像gdb
list xxxxx
https://segmentfault.com/a/1190000019222661 https://gfw.go101.org/article/memory-leaking.html
附录 #
[1] go101
[2] code_reading
[3] Go 语言设计与实现
[4] 接口内部实现
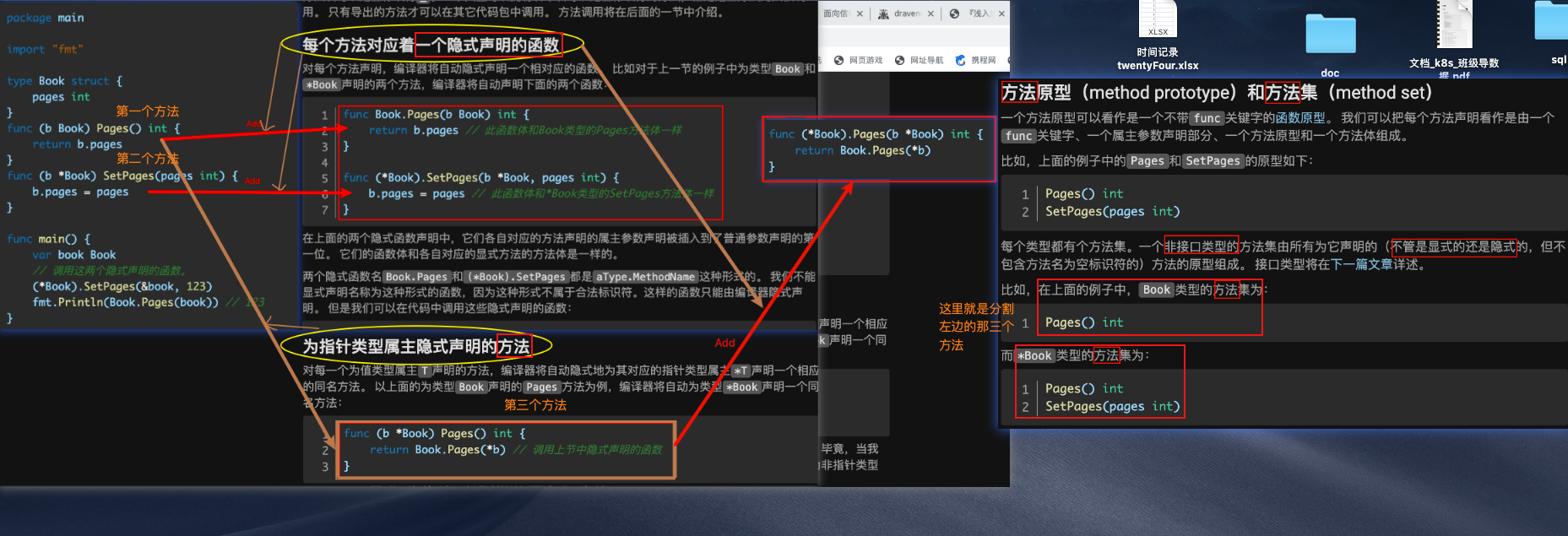
0.方法 #
为指针类型属主隐式声明的方法
- 每个方法对应着一个隐式声明的函数
类型T的方法集总是类型*T的方法集的子集。
如何决定一个方法声明使用值类型属主还是指针类型属主?
package main import "fmt" type Book struct { pages int } type Books []Book func (books *Books) Modify() { *books = append(*books, Book{789}) (*books)[0].pages = 500 } func main() { var books = Books{{123}, {456}} books.Modify() fmt.Println(books) // [{500} {456} {789}] }(&book).SetPages(123)一行为什么可以被简化为book.SetPages(123)呢?- 毕竟,类型Book并不拥有一个SetPages方法。
- 这可以看作是Go中为了让代码看上去更简洁而特别设计的语法糖。
- 此语法糖只对可寻址的值类型的属主有效。 编译器会自动将
book.SetPages(123)改写为(&book).SetPages(123)。 - 但另一方面,我们应该总是认为
aBookExpression.SetPages是一个合法的选择器(从语法层面讲),即使表达式aBookExpression被估值为一个不可寻址的Book值(在这种情况下,aBookExpression.SetPages是一个无效但合法的选择器)。
package main import "fmt" type Book struct { pages int } func (b Book) Pages() int { return b.pages } func (b *Book) SetPages(pages int) { b.pages = pages } func main() { var book Book fmt.Printf("%T \n", book.Pages) // func() int fmt.Printf("%T \n", (&book).SetPages) // func(int) // &book值有一个隐式方法Pages。 fmt.Printf("%T \n", (&book).Pages) // func() int // 调用这三个方法。 (&book).SetPages(123) book.SetPages(123) // 等价于上一行 fmt.Println(book.Pages()) // 123 fmt.Println((&book).Pages()) // 123 } - 此语法糖只对可寻址的值类型的属主有效。 编译器会自动将
1. new And make #
what: allocates AND initializes
- new
- (allocates memory).
- make
- (allocates and initializes an object of type slice, map, or chan (only)).
- new
why:
how:
- 区别从函数定义就可以看出来:
func new(Type) *TypeANDfunc make(t Type, size ...IntegerType) Type- 入参值
- make 只能用来分配及初始化类型为 slice、map、chan 的数据(slice, map, or chan (only))。new 可以分配任意类型的数据;
- 输出值
- new 分配返回的是指针,即类型 *Type。make 返回引用,即 Type;
- new 分配的空间被清零。make 分配空间后,会进行初始化;
- 入参值
- 区别从函数定义就可以看出来:
example #
package main
import (
"fmt"
)
func main() {
var i *int
*i=10
fmt.Println(*i)
}
这个例子会打印出什么?0还是10?。以上全错,运行的时候会painc,原因如下:
panic: runtime error: invalid memory address or nil pointer dereference
从这个提示中可以看出,对于引用类型的变量,我们不光要声明它,还要为它分配内容空间,否则我们的值放在哪里去呢?这就是上面错误提示的原因。
对于值类型的声明不需要,是因为已经默认帮我们分配好了。
要分配内存,就引出来今天的new和make。
2. 值类型和引用类型的区别 #
2.1. go语言中没有引用类型。
2.2. 引用关系是通过指针和各种内置类型的某些可能的内部结构建立的
- 内部结构的实现定义
// 映射类型 type _map *hashtableImpl // 目前,官方标准编译器是使用哈希表来实现映射的。 // 通道类型 type _channel *channelImpl // 函数类型 type _function *functionImpl type _slice struct { elements unsafe.Pointer // 引用着底层的元素 len int // 当前的元素个数 cap int // 切片的容量 } type _string struct { elements *byte // 引用着底层的byte元素 len int // 字符串的长度 } type _interface struct { dynamicType *_type // 引用着接口值的动态类型 dynamicValue unsafe.Pointer // 引用着接口值的动态值 } type _interface struct { dynamicTypeInfo *struct { dynamicType *_type // 引用着接口值的动态类型 methods []*_function // 引用着动态类型的对应方法列表 } dynamicValue unsafe.Pointer // 引用着动态值 }
- 内部结构的实现定义
Question
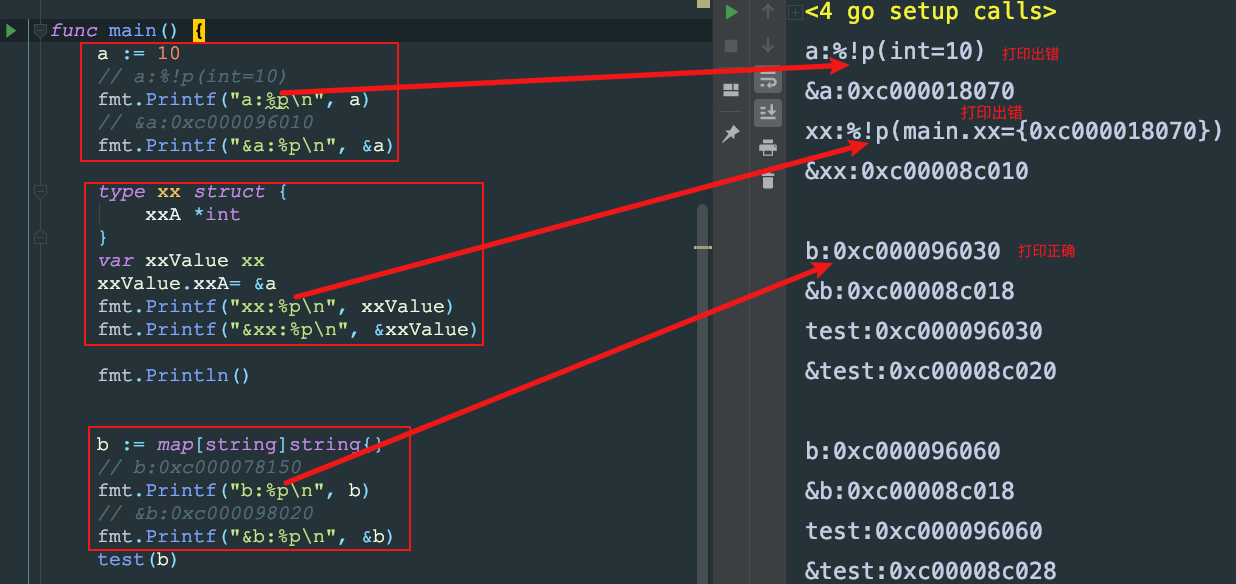
- 但是为什么使用
%p来打印的时候这些常规认为的“引用类型”,可以打印,答应我们认为的值类型的时候,出错。- 从下面的gdb例子中可以看出,我们能打印这些常规认为的“引用类型”,是因为
Slice: %p address of 0th element in base 16 notation, with leading 0x, 它实际打印的是第0个元素的地址。而&test是打印的它实际的struct的地址。package main import ( "fmt" "unsafe" ) func testS(test []int) { // test:0xc000078150 fmt.Printf("---test:%p\n", test) // &test:0xc000098028 fmt.Printf("&test:%p\n", &test) fmt.Println() } func main() { s := []int{1, 2} fmt.Println(unsafe.Sizeof(s)) fmt.Printf("s---:%p\n", s) fmt.Printf("&s[0]---:%p\n", &s[0]) fmt.Printf("&s:%p\n", &s) testS(s) } 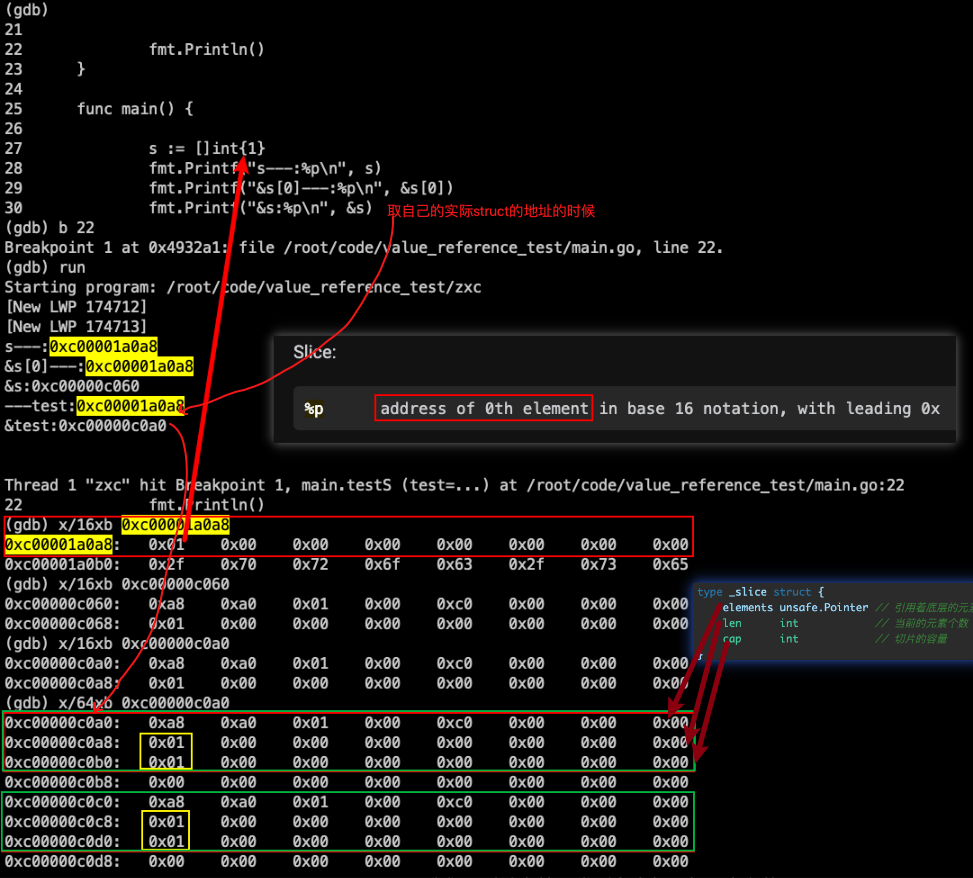
- 从下面的gdb例子中可以看出,我们能打印这些常规认为的“引用类型”,是因为
Package fmt There Are No Reference Types in Go About the terminology “reference type” in Go
3. 计算golang中类型的大小的方式 #
- struct会不会有填充的(padding)的bit?
- 会的,就像下方的例子中,T.B就是一个bit,但是它后面填充了7个bit.
- 类似sizeof的函数?
unsafe.Sizeof()
- 如果是分配在heap中,还可以使用什么方式来评估?
runtime.ReadMemStats(&m1)// 好像一个snapshot,可以评估当前heap的空间. t := T{} runtime.ReadMemStats(&m2)
package main
import (
"fmt"
"runtime"
"strconv"
"unsafe"
)
// Unlike C, there is no _#pragma pack_ in Go, the real memory allocation
// depends on its implementation.
type T struct {
B uint8 // is a byte
I int // it is int32 on my x86 32 bit PC
P *int // it is int32 on my x86 32 bit PC
S string
SS []string
}
var p = fmt.Println
// In this case, the `t := T{}` can not measured by this method.
func memUsage(m1, m2 *runtime.MemStats) {
p("Alloc:", m2.Alloc-m1.Alloc,
"TotalAlloc:", m2.TotalAlloc-m1.TotalAlloc,
"HeapAlloc:", m2.HeapAlloc-m1.HeapAlloc)
}
func main() {
// Here is a tricky to get pointer size
const PtrSize = 32 << uintptr(^uintptr(0)>>63)
p("PtrSize=", PtrSize)
p("IntSize=", strconv.IntSize)
var m1, m2, m3, m4, m5, m6 runtime.MemStats
runtime.ReadMemStats(&m1)
t := T{}
runtime.ReadMemStats(&m2)
p("sizeof(uint8)", unsafe.Sizeof(t.B),
"offset=", unsafe.Offsetof(t.B))
p("sizeof(int)", unsafe.Sizeof(t.I),
"offset=", unsafe.Offsetof(t.I))
p("sizeof(*int)", unsafe.Sizeof(t.P),
"offset=", unsafe.Offsetof(t.P))
p("sizeof(string)", unsafe.Sizeof(t.S),
"offset=", unsafe.Offsetof(t.S))
// Slice is a structure of Pointer, Len and Cap.
// Detail [here](http://blog.golang.org/go-slices-usage-and-internals)
p("sizeof([]string)", unsafe.Sizeof(t.SS),
"offset=", unsafe.Offsetof(t.SS))
// We can see the this structure is 4 + 4 + 4 + 8 + 12 = 32 bytes
// There are 3 padding bytes of first t.B expanded to 4 bytes.
p("sizeof(T)", unsafe.Sizeof(t))
// We will see 0 bytes, because it is on stack, so sizeof is the
// proper method to tell how much memory allocated.
memUsage(&m1, &m2)
// Even string assignment is in stack. also is zero
runtime.ReadMemStats(&m3)
t2 := "abc"
runtime.ReadMemStats(&m4)
memUsage(&m3, &m4)
// map will alloc memory in heap
runtime.ReadMemStats(&m5)
t3 := map[int]string{1: "x"}
runtime.ReadMemStats(&m6)
memUsage(&m5, &m6)
fmt.Println(t2, t3) // prevent compiler error
}
golang的chan #

‘‘里面的是chan的状态(eg: 一个零值nil通道;一个非零值但已关闭的通道)
‘空’读写阻塞-关闭恐慌; ‘关闭’读为0-关闭写恐慌. 如果是有缓存的chan已关闭,且现在缓存不为空,读正常得到数据
what:
- 通道的主要作用是用来实现并发同步
- 可以把一个通道看作是在一个程序内部的一个先进先出(FIFO:first in first out)数据队列。 一些协程可以向此通道发送数据,另外一些协程可以从此通道接收数据。
- channel类型与值
- 字面形式chan T表示一个元素类型为T的双向通道类型。 编译器允许从此类型的值中接收和向此类型的值中发送数据。
- 字面形式chan<- T表示一个元素类型为T的单向发送通道类型。 编译器不允许从此类型的值中接收数据。
- 字面形式<-chan T表示一个元素类型为T的单向接收通道类型。 编译器不允许向此类型的值中发送数据。
- 类型T总是放在最后面。
- 我们了解到一个通道值可能含有底层部分。 当一个通道值被赋给另一个通道值后,这两个通道值将共享相同的底层部分。
- channel类型与值
why:
- 一个通道内部维护了三个队列(均可被视为先进先出队列):
- 接收数据协程队列(可以看做是先进先出队列但其实并不完全是,见下面解释)。此队列是一个没有长度限制的链表。 此队列中的协程均处于阻塞状态,它们正等待着从此通道接收数据。
- 发送数据协程队列(可以看做是先进先出队列但其实并不完全是,见下面解释)。此队列也是一个没有长度限制的链表。 此队列中的协程亦均处于阻塞状态,它们正等待着向此通道发送数据。 此队列中的每个协程将要发送的值(或者此值的指针,取决于具体编译器实现)和此协程一起存储在此队列中。
- 数据缓冲队列。这是一个循环队列(绝对先进先出),它的长度为此通道的容量。此队列中存放的值的类型都为此通道的元素类型。 如果此队列中当前存放的值的个数已经达到此通道的容量,则我们说此通道已经处于满槽状态。 如果此队列中当前存放的值的个数为零,则我们说此通道处于空槽状态。 对于一个非缓冲通道(容量为零),它总是同时处于满槽状态和空槽状态。
- 一个通道内部维护了三个队列(均可被视为先进先出队列):
| 操作 | 一个零值nil通道 | 一个非零值但已关闭的通道 | 一个非零值且尚未关闭的通道 |
|---|---|---|---|
| 关闭 | 产生恐慌 | 产生恐慌 | 成功关闭(C) |
| 发送数据 | 永久阻塞(I) | 产生恐慌 | 阻塞或者成功发送(B) |
| 接收数据 | 永久阻塞(II) | 永不阻塞(D) | 阻塞或者成功接收(A) |
看下I: 直接看下发送数据的源码 walkexpr –> chansend1 –> chansend
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if c == nil {
if !block {
return false
}
// 这里面直接进入睡眠,永远阻塞
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
//...
- how:
- 五种操作:
close(ch)ch <- v<-chv = <-chv, sentBeforeClosed = <-ch
cap(ch)len(ch)
- 五种操作:
archive #
数据结构
常用关键字
- for 和 range
- select
- defer
- panic 和 recover
- make 和 new
并发编程
内存